









1 项目简介
项目的开源地址:GitHub - HKUDS/LightRAG: "LightRAG: Simple and Fast Retrieval-Augmented Generation"
LightRAG是香港大学开发的一种简单高效的大模型检索增强(RAG)系统。
LightRag基于LLM、VectorDB、和GraphDb构建知识库,将图结构整合到文本索引和检索过程中。
LightRag框架采用了双层检索系统,从低层次和高层次的知识发现中增强了全面信息检索。根据其官方介绍,图结构与向量表示的整合便于高效检索相关实体及其关系,显著提高了响应时间。
2 框架结构
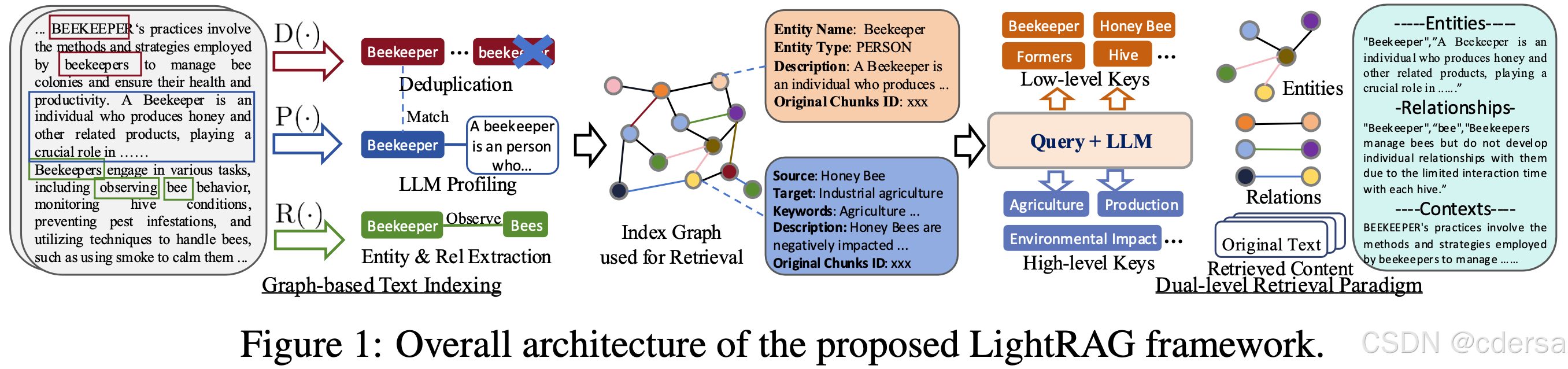
系统的类图
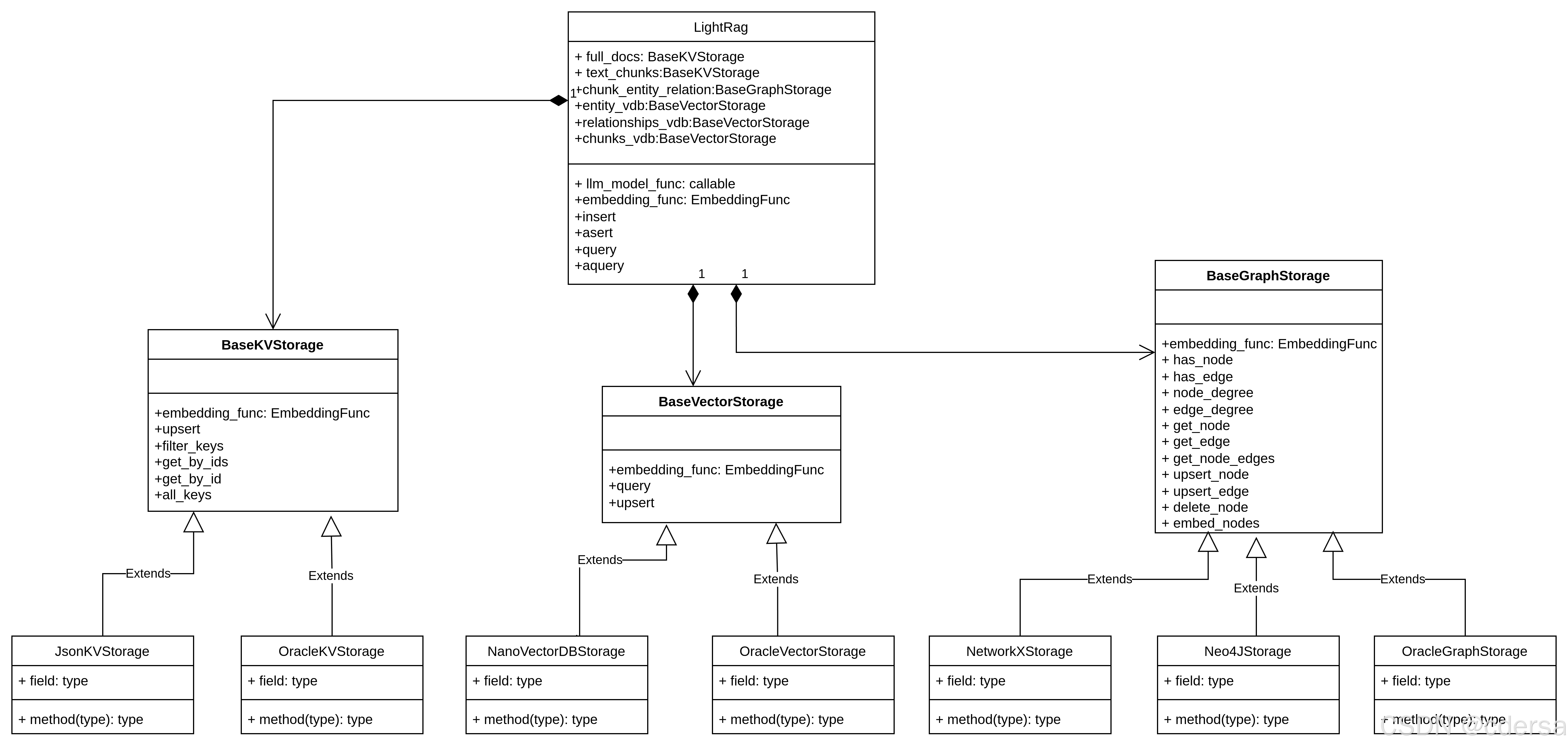
3 组件分析
3.1 LLM组件
在LightRag中,LLM的用途有两用途:Embedding和Query。
Embedding的作用:根据LightRag传的内容计算vector信息,LightRag根据vector存储信息到vectordb或从vectordb中查询数据。
支持的Embedding的引擎有:openai_embedding、siliconcloud_embedding、bedrock_embedding、hf_embedding、ollama_embedding
Query的作用有三种:
- 根据分析文本内容之间的关系的prompt进行分析文本
- 提取问题关键词,lightrag根据关键从知识库中查找与之相关的内容,进行知识召回
- 根据LightRag使用召回的知识和要问的问题进行内容生成。
支持Query的引擎有:hf_model_complete、ollama_model_complete、bedrock_complete、gpt_4o_complete、gpt_4o_mini_complete、azure_openai_complete
3.2 kv组件
kv的有两种:
全量文件full_docs,存储应用直接传过来的文件,key为文本的hashid,value为文本内容。
chunk文件text_chunks,由于传过的文本可能超长,所以要先计算token是否超长,如果超了,就要对文本执行chunk操作,text_chunks存储的就是chunks之后的文本。
3.3 vector组件
vectordb存储的内容有三种:
chunk_vdb存储chunk文本和chunk文本的embedding信息
entity_vdb存储entity和entity文本的embedding信息
relation_vdb存储relation和relation相关文本的embedding信息
3.4 graph组件
chunk_entity_relation_graph用于图形化存储实体数据,以及实体之间的关系数据
4 处理流程分析
相关原代码的分析参考https://gitee.com/tmfll/LightRAG.git的reviewbranch中的注释
4.1 构建知识库
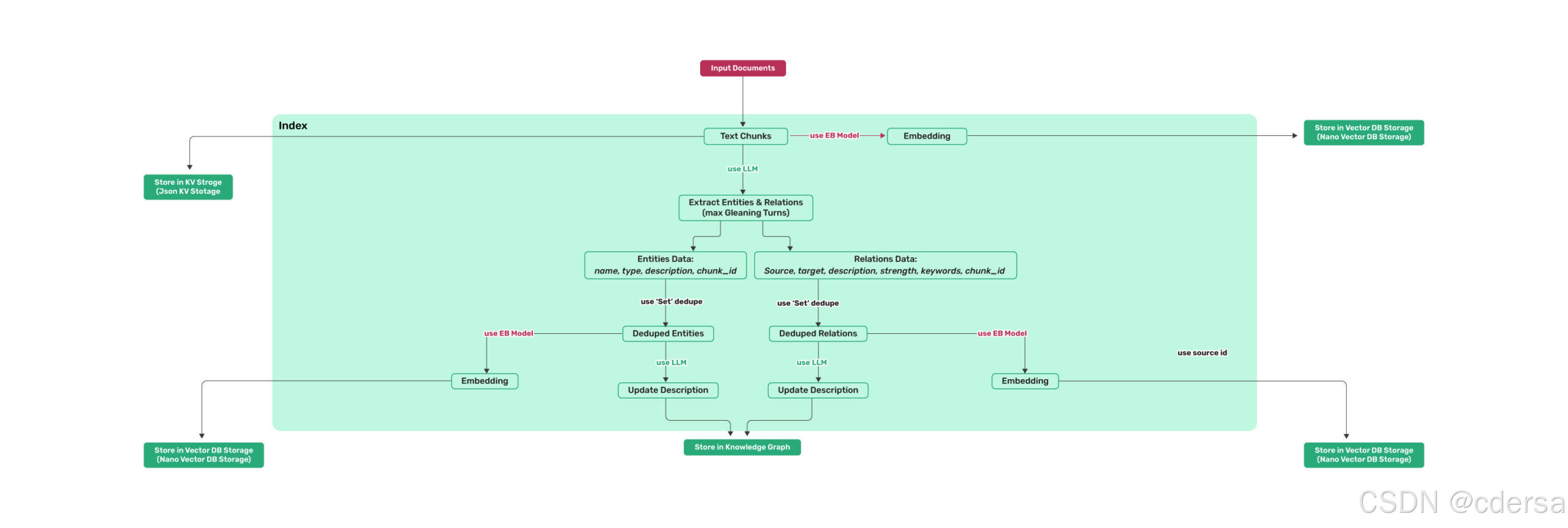
- 初始化LightRag环境,指定Embedding函数、LLM_func回调函数、LLM和Embedding使用的模型,LLM目标服务的访问地址。其中nde2vee_params中所述的dimensions的值,须和参数中的embedding_dims的值相同。
rag = LightRAG( working_dir=WORKING_DIR, llm_model_func=ollama_model_complete, llm_model_name="qwen2m", llm_model_max_async=4, llm_model_max_token_size=32768, llm_model_kwargs={"host": "http://192.168.8.156:11434", "options": {"num_ctx": 32768}}, node2vec_params={"dimensions": 768, "num_walks": 10, "walk_length": 40, "window_size": 2, "iterations": 3, "random_seed": 3,}, embedding_func=EmbeddingFunc( embedding_dim=768, max_token_size=8192, func=lambda texts: ollama_embedding( texts, embed_model="nomic-embed-text", host="http://192.168.8.156:11434" ), ), ) - 应用首先读取文件,应用在读取文件时是按页,或是按行,或是按段,并不作特定的要求。应用读取内容后,循环调用LightRag的insert方法。
- lightrag的循环插入数据构建知识库逻辑如下:
- 存储doc_text全量信息,计算chunk和存储chunk
- 因为读取的内容传入进来的,可以是一个字符串,也可能是字符串例表。所以在判断的时候,如果普通的字符串要先转成列表。
- 遍历字符串列表,计算读取内容的hashId
- 从full_docs中,查看是否有相同的hashid存在,如果没有相同的存在,就执行下面的动作,否则过滤掉相同的内容。
- 将计算传入的文本的token数量是否超长,若超长就拆分出chunk列表,遍历chunk列表,检查text_chunks中是否有相同的chunk存在,若不存在的话,就插入到text_chunks中。
- 遍历新增的text_chunks中,向llm embedding服务请求计算embedding信息,拿到embedding信息后,将text_chunks和与之相关的embedding信息填入数据库中。
- 利用LLM提取知识
- 遍历新增的text_chunk信息,使用entity_extraction模板,拼装prompt信息(prompt中约定好提取内容的格式),并调用llm_model_func向LLM引擎发送指令,llm_model_func返回提取的entity和relation报文。
- 为防止提取的内容没有完全提取,组装历史消息,使用continue_prompt和历史消息继续向LLM 发送提取指令,直至使用entiti_if_loop_extraction向LLM查询时,返回yes或迭代次数达到了预设的值(entity_extract_max_gleaning默认为1)。
- 解析知识,并存储到graph数据库和vector数据库
- 根据约定的格式内容,从上述提取的内容中,分解出entity和relation,
- 进行entity合并和relation合并。将entity和relation信息,分别写到entity_graph和relation_graph中
- 向LLM请求计算提取到的entity和relation的embedding值,将entity和relation及相对应的embedding值,填写到entity_vdb和relation_vdb中。
- 存储doc_text全量信息,计算chunk和存储chunk
4.2 检索知识库
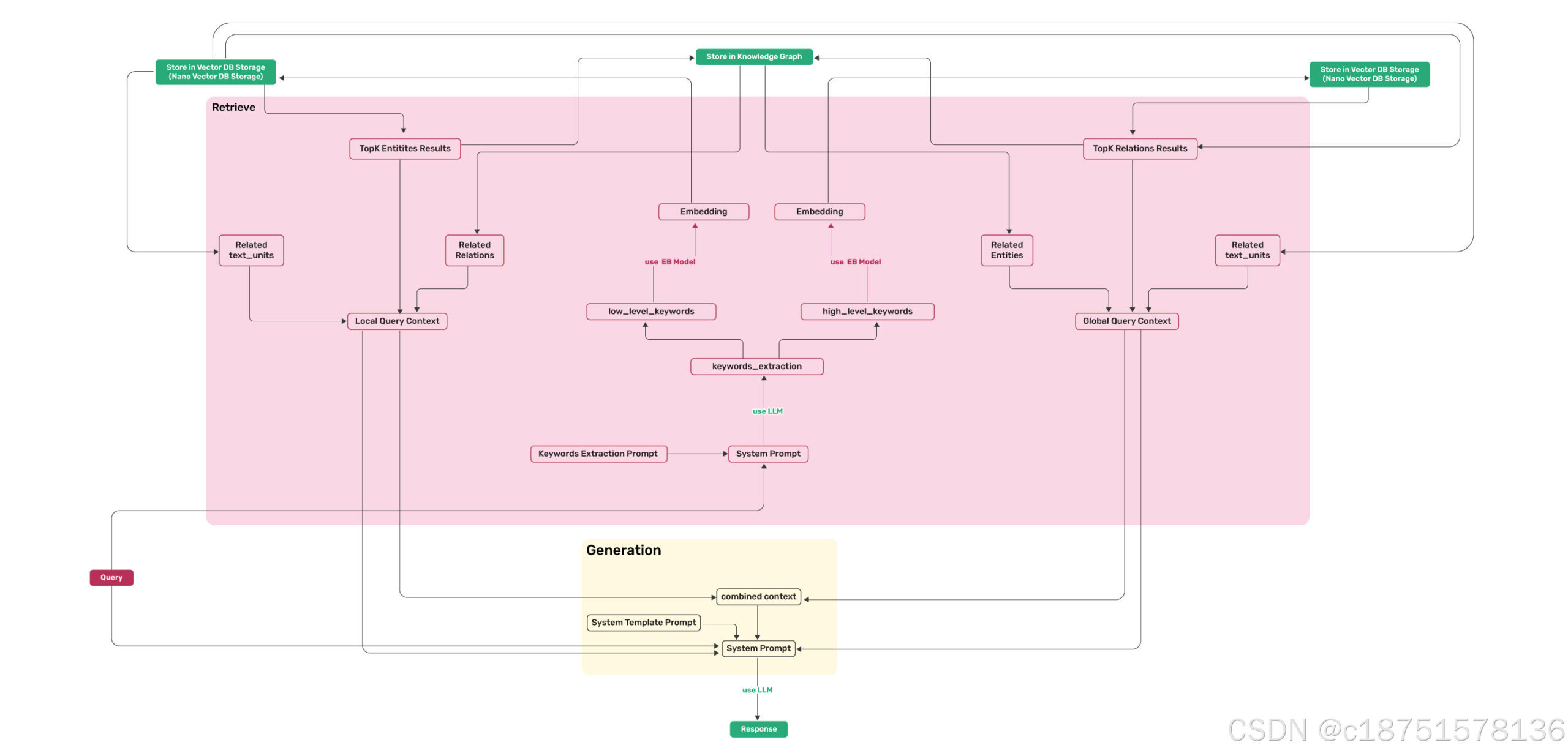
- 初始化LightRag环境,指定Embedding函数、LLM_func回调函数、LLM和Embedding使用的模型,LLM目标服务的访问地址。其中nde2vee_params中所述的dimensions的值,须和参数中的embedding_dims的值相同。
- 应用调用LightRag的query方法,发送查询的内容。查询的逻辑分为四种:
- global_query: 通过vdb和graphdb查询relation的信息,构建prompt,向LLM获得最终的结果
- local_query:通过vdb和graphdb查询entity的信息,构建prompt,向LLM获得最终的结果
- hybrid_query:通过vdb和graphdb查询relation和entity的信息,构建prompt,向LLM获得最终的结果
- naive:从chunk中查询信息,构建prompt,向LLM获得最终的结果
- global_query的promt的组装逻辑:
- 使用keywords_extraction模板和query内容,拼装prompt,并并调用llm_model_func向LLM引擎发送prompt,获得keywords,返回的结果一般状况下应该是一个json格式,如不是json格式,需要转换为json格式,将json格式转换为字典,从字典中获得high_level_keywords
- 将获得的high_level_keywords调用embedding接口,获得embedding vector,然后使用该vector,从relation_vdb中获得relation信息。
- 根据获得的relation信息,从chunk_entity_relation_graph中获得relation的信息
- 根据relation的图信息从chunk_entity_relation_graph中获得相关的entitiy节点信息。
- 根据relaiton信息,从text_chunk_db中获得chunk信息。
- 拼接3~5获得的信息中的文本,返回csv格式。
- 根据模板rag_response和拼接的召回知识,生成prompt信息。
- 调用llm_model_func向LLM引擎发送消息,获得应答。其中prompt该prompt作为system_prompt参数,query作为用户的消息参数。
- local_query的promt的组装逻辑:
- 使用keywords_extraction模板和query内容,拼装prompt,并并调用llm_model_func向LLM引擎发送prompt,获得keywords,返回的结果一般状况下应该是一个json格式,如不是json格式,需要转换为json格式,将json格式转换为字典,从字典中获得low_level_keywords
- 将获得的low_level_keywords调用embedding接口,获得embedding vector,然后使用该vector,从entity_vdb中获得entity信息
- 根据获得的entity信息,从chunk_entity_relation_graph中获得entity的节点信息,并根据该节点的边的数量,计算该节点的degree
- 根据entity节点,获得与该节点相关的relation边的信息,并根据degree和weight的值进行排序,并根据token的长度的限制,选择排名靠前的的relation的信息
- 找出entity节点的邻居节点列表,根据entity的节点的id,从text_chunk_db中根据id找出相对应的文本信息
- 将3~5中所获得的信息拼成csv信息
- 根据模板rag_response和拼接的召回知识,生成prompt信息
- 调用llm_model_func向LLM引擎发送消息,获得应答。其中prompt该prompt作为system_prompt参数,query作为用户的消息参数
- hybrid_query的promt的组装逻辑:
- 在生成prompt的过程中,可以看成是上述两种逻辑的综合组装prompt,该prompt作为system_prompt参数,query作为用户的消息参数,向LLM引擎发送prompt信息,获得应答。
5 存在的问题
代码逻辑总体清晰,易于理解,安装的依赖包相比较其它的Rag少很多,易于使用,处理英文时效果较佳。
个人认为还存在以下的可改进点:
-
prompt模板为英文描述,在处理中文时,返回的关键词或entity或relation会存在中英文混搭的情况,此时知识的召回的效果较差。若在构建知识库时,根据LLM query提取的entity或relation的文本去计算Embedding的语言类型和进行检索时根据query获得的keyword的语言类型不一致时,会导致检索失败,无法进行知识的召回。针对中文的情况,需要额外进行调优。
-
在chunk语句时,简单的根据Token的最大长度进行chunk,导致语句不完整,特别在中文环境下,容易导致出现无法识别的字符。
-
返回的实体中,存在并不是文本中的内容,但实际上是prompt中举例的内容,也可以LLM自己猜的内容。代码在处理的逻辑中,并未将这些与事实上无关的文本信息过滤。
-
没有并行处理的逻辑,当文本较大时,处理耗时较久。
-
在处理图数据库时的逻辑似乎并不够高效,存在反复处理的逻辑。节点和Relation之间的关系的设置和检索可以更高效。
-
本库在实际工程化的时候可以考虑以下改进点:例如进行文本的切分首先构建全量的普通的文档的chunk库,此进可以进行在进行知识检索的时候,先使用naive模式进行知识的召回;再根据chunk库构建vector db和graph db,在知识图谱构建完成后,可以根据相关的知识库进行更准确的知识召回 。
6 验证过程
相关的环境已打容器镜像:swr.cn-north-4.myhuaweicloud.com/tiger202203/lightrag-cuda-conda-11:121-ubuntu2204
验证过程如下:
-
下载基础镜像swr.cn-north-4.myhuaweicloud.com/tiger202203/cuda-conda-11:121-ubuntu2204-c036
-
创建容器
-
conda create -n lightrag python=3.11
-
执行pip install -r requirement.txt
-
python setup.py install
-
按照官方文档安装ollama,下载qwen模型和nomic-embed-text
-
在example目录下,参考lightrag_ollama_demo.py,设置LightRag参数和要分析的文档,创建知识库。本代码分析的文档是《三国演义》
import os import logging from lightrag import LightRAG, QueryParam from lightrag.llm import ollama_model_complete, ollama_embedding from lightrag.utils import EmbeddingFunc WORKING_DIR = "./dickens" logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.INFO) if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR) rag = LightRAG( working_dir=WORKING_DIR, llm_model_func=ollama_model_complete, llm_model_name="qwen2m", llm_model_max_async=4, llm_model_max_token_size=32768, llm_model_kwargs={"host": "http://127.0.0.1:11434", "options": {"num_ctx": 32768}}, node2vec_params={"dimensions": 768, "num_walks": 10, "walk_length": 40, "window_size": 2, "iterations": 3, "random_seed": 3,}, embedding_func=EmbeddingFunc( embedding_dim=768, max_token_size=8192, func=lambda texts: ollama_embedding( texts, embed_model="nomic-embed-text", host="http://127.0.0.1:11434" ), ), ) with open("./data/sgyy.txt", "r", encoding="utf-8") as f: rag.insert(f.read()) -
在example目录下,参考lightrag_ollama_demo.py,设置LightRag参数和和查询的语句,进行知识检索。
import os import logging from lightrag import LightRAG, QueryParam from lightrag.llm import ollama_model_complete, ollama_embedding from lightrag.utils import EmbeddingFunc WORKING_DIR = "./dickens" logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.INFO) if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR) rag = LightRAG( working_dir=WORKING_DIR, llm_model_func=ollama_model_complete, llm_model_name="qwen2m", llm_model_max_async=4, llm_model_max_token_size=32768, llm_model_kwargs={"host": "http://192.168.8.156:11434", "options": {"num_ctx": 32768}}, node2vec_params={"dimensions": 768, "num_walks": 10, "walk_length": 40, "window_size": 2, "iterations": 3, "random_seed": 3,}, embedding_func=EmbeddingFunc( embedding_dim=768, max_token_size=8192, func=lambda texts: ollama_embedding( texts, embed_model="nomic-embed-text", host="http://192.168.8.156:11434" ), ), ) # Perform local search print("-----------------------------------------------------------------------------") print('global 刘备是谁:',rag.query("刘备是谁?", param=QueryParam(mode="global"))) print("*****************************************************************************") print('local 刘备是谁:', rag.query("刘备是谁?", param=QueryParam(mode="local"))) print("############################################################################") print('hybrid 刘备是谁:', rag.query("刘备是谁?", param=QueryParam(mode="hybrid")))

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









