










1.简介
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了检索和生成的自然语言处理技术。它主要是在传统的语言生成模型的基础上,通过检索模块来引入外部知识,从而提升生成内容的质量和准确性。
RAG系统通过集成外部知识源来增强大语言模型(Large Language Model,LLM),从而能够根据用户需求定制更准确且上下文相关的响应。然而,现有的RAG系统具有显著的局限性,包括依赖于平面数据表示和不充分的上下文感知,这可能导致无法捕获复杂的相互依赖性的碎片化答案。
为了解决这些问题,北邮/港大团队提出了LightRAG,它将图结构融入到文本索引和检索过程中。该创新框架采用了一个双层检索系统,从低层和高层知识发现中增强了综合信息检索。另外,图结构与向量表示的集成便于相关实体及其关系的高效检索,从而在保持上下文相关性的同时显著地改进响应时间。增量更新算法可确保及时整合新数据,从而使系统在快速变化的数据环境中保持高效和响应能力,从而进一步增强了这一能力。大量的实验验证表明,与现有方法相比,该方法在检索精度和效率上都有了显著的提高。
部署LightRAG的博客:基于LightRAG进行本地RAG部署(包括单卡多卡本地模型部署、调用阿里云或DeepSeekAPI的部署方法、RAG使用方法)_lightrag-server-CSDN博客
github代码:https://github.com/HKUDS/LightRAG
-
-
2.原理解读
标准RAG的缺点
现有的RAG系统存在妨碍其性能的关键限制。首先,许多方法依赖于平面数据表示方法,这限制了它们基于实体之间复杂关系理解和检索信息的能力。其次,这些系统往往缺乏上下文意识,需要保持跨各种实体及其相互关系的一致性,导致响应可能无法完全解决用户查询。例如,假设有用户问:“电动汽车的兴起对城市空气质量和公共交通基础设施有何影响?”现有的RAG方法可能会检索关于电动汽车、空气污染和公共交通挑战的单独文档,但很难将这些信息综合到一个有凝聚力的响应中。他们可能无法解释电动汽车的采用如何改善空气质量,而这反过来又可能影响公共交通规划。结果,用户可能接收到不充分地捕捉这些主题之间的复杂的相互依赖性的片段化回答。
为解决该问题,作者提出了将图结构引入文本索引和相关信息检索中。图在表示不同实体之间的相互依赖性方面特别有效,这使得人们能够更细致地理解关系。基于图的知识结构的集成有助于将来自多个源的信息合成为连贯且上下文丰富的响应。尽管有这些优点,但开发一个快速、可扩展的、支持图的RAG系统来有效地处理变化的查询量是至关重要的。
LightRAG采用了高效的双层检索策略:低层检索,关注关于特定实体及其关系的精确信息;高层检索,包含更广泛的主题。通过将详细检索和概念检索相结合,LightRAG有效地适应了各种各样的查询,确保用户收到针对其特定需求的相关和全面的响应。此外,通过将图结构与向量表示相结合,LightRAG框架有助于有效地检索相关实体和关系,同时通过构建的知识图的相关结构信息增强结果的全面性。
-
标准RAG
检索增强生成(RAG)将用户查询与来自外部知识数据库的相关文档集合集成在一起,其包含两个基本组件:检索组件和生成组件。
- 检索组件负责从外部知识数据库中获取相关文档或信息。它根据输入查询识别和检索最相关的数据。
- 在检索过程之后,生成组件获取检索到的信息并生成连贯的、上下文相关的响应。它利用语言模型的功能来产生有意义的输出。
具体来说,RAG模型在生成文本之前,会先利用检索模块从一个大规模的外部知识库中检索出与当前输入文本相关的信息。这个知识库可以是网页、书籍、文档等各种形式的文本数据集合。检索模块会根据输入文本的语义和关键词等信息,寻找出与之最匹配的文本片段或者知识片段。
然后,这些检索到的知识片段会被整合到生成模型中,作为额外的上下文信息来辅助生成过程。这样生成模型就不仅仅依赖于自身训练时学到的知识,还能利用到最新的、更广泛的知识库中的内容,从而生成更加丰富、准确和符合实际需求的文本。比如在回答问题时,能够提供更准确的答案;在生成文章时,能够包含更丰富的内容和细节,避免出现知识盲区或者生成不合理的内容。
形式上,我们将RAG框架表示为M,可以定义如下:
在这个框架中,G和R分别表示生成模块和检索模块,q表示输入的查询,D表示外部数据库。检索模块R包括两个关键功能:i)数据索引器:其涉及基于外部数据库D构建特定数据结构
。ii)数据检索器
:通过将查询与索引数据进行比较来获得相关文档,也被表示为“相关文档”。通过利用通过沿着初始查询q检索的信息,生成模型G(·)有效地产生高质量的上下文相关的响应。
-
基于图的文本索引
图模型增强的实体和关系提取。LightRAG通过将文档分割成更小、更易于管理的片段来增强检索系统。此策略允许快速识别和访问相关信息,而无需分析整个文档。接下来,框架利用LLM来识别并提取各种实体(例如,名称、日期、位置和事件)和它们之间的关系。通过此流程收集的信息将用于创建一个全面的知识图表,突出整个文档集之间的联系和见解。我们将该图生成模块正式表示如下:
其中表示得到的知识图。为了生成该数据,LightRAG对原始文本文档
应用三个主要处理步骤。这些步骤利用LLM进行文本分析和处理:
- 提取实体和关系。R(·):此函数提示LLM识别文本数据中的实体V(节点)及其关系
(边)。例如,它可以从文本中提取像“心脏病学家”和“心脏病”这样的实体,以及像“心脏病学家诊断心脏病”这样的关系:“心脏病学家评估症状以识别潜在的心脏问题。”为了提高效率,原始文本D被分割成多个块
。
- LLM 概况信息,生成键值对。P(·):LightRAG使用以LLM为基础的分析函数P(·)为每个实体节点和关系边生成文本键值对(K,V)。每个索引键都是一个单词或短语,可以实现高效检索,而相应的值是一个文本段落,总结了外部数据中的相关片段,以帮助生成文本。实体使用它们的名称作为唯一的索引键,而关系可能有多个索引键,这些索引键来自LLM增强,包括来自连接实体的全局主题。
- 去重。D(·):最后,LightRAG实现了一个去重函数D(·),它识别并合并来自原始文本
上的图操作相关的开销,从而提高了数据处理的效率。
基于图的文本索引范式提供了两个优势。一是全面了解信息。构建的图结构能够从多跳子图中提取全局信息,大大增强了LightRAG处理跨多个文档块的复杂查询的能力。第二,提高检索性能。从图中导出的关键字-值数据结构被优化用于快速和精确的检索。这为不太准确的嵌入匹配方法提供了一种上级替代方案和低效的块遍历技术,这在现有的方法中普遍使用。
快速更新知识库。为了有效地适应不断变化的数据,同时确保准确和相关的响应,LightRAG更新知识库时,无需完全重新处理整个外部数据库。对于新文档D′,增量更新算法使用与之前相同的基于图的索引步骤φ来处理它,从而得到。随后,LightRAG将新的图形数据与原始图形数据进行合并,方法是取节点集
和
以及边集
和
的并集。
-
双层检索范式
为了从特定的文档块及其复杂的相互依赖关系中检索相关信息,LightRAG建议在细节和抽象级别上生成查询键。
- 细节查询。这些查询是面向细节的,并且通常引用图中的特定实体,需要精确检索与特定节点或边相关联的信息。例如,一个特定的查询可能是,“谁写了《傲慢与偏见》?”
- 抽象查询。相比之下,抽象查询更具概念性,包含更广泛的主题,摘要或不直接与特定实体联系的总体主题。抽象查询的一个例子是,“人工智能如何影响现代教育?”
为了适应不同的查询类型,LightRAG采用两种不同的检索策略内的双级检索范式。这确保了具体和抽象的查询都得到有效处理,使系统能够根据用户需求提供相关的答复。
- 低级检索。此级别主要用于检索特定实体的关联属性或关系。此级别的查询是面向细节的,旨在提取有关图中特定节点或边的精确信息。列如,对于“XX大学的建校时间?”,低级检索生成的结果是["XX大学",“建校时间”]
- 高级检索。这一级别涉及更广泛的主题和最重要的主题。此级别的查询聚合了多个相关实体和关系中的信息,提供了对更高级别的概念和摘要(而不是具体细节)的深入了解。列如,对于“XX大学的建校时间?”,高级检索生成的结果是["高校",“历史沿革”]
-
集成图形和向量以实现高效检索。通过将图形结构与向量表示(即标准RAG)相结合,该模型可以更深入地了解实体之间的相互关系。
- 查询关键字提取。对于给定的查询q,LightRAG的检索算法通过提取局部查询关键字k(l)和全局查询关键字k(g)两者开始。
- 关键字匹配。该算法使用高效的向量数据库将局部查询关键字与候选实体进行匹配,并将全局查询关键字与全局关键字链接的关系进行匹配。
- 合并相邻节点。LightRAG进一步收集检索到的图形元素的局部子图内的相邻节点。此过程涉及集合节点v和边e的一跳相邻节点。
这种双层检索模式不仅通过关键字匹配实现了对相关实体和关系的高效检索,而且通过整合构建的知识图中的相关结构信息,增强了检索结果的全面性。
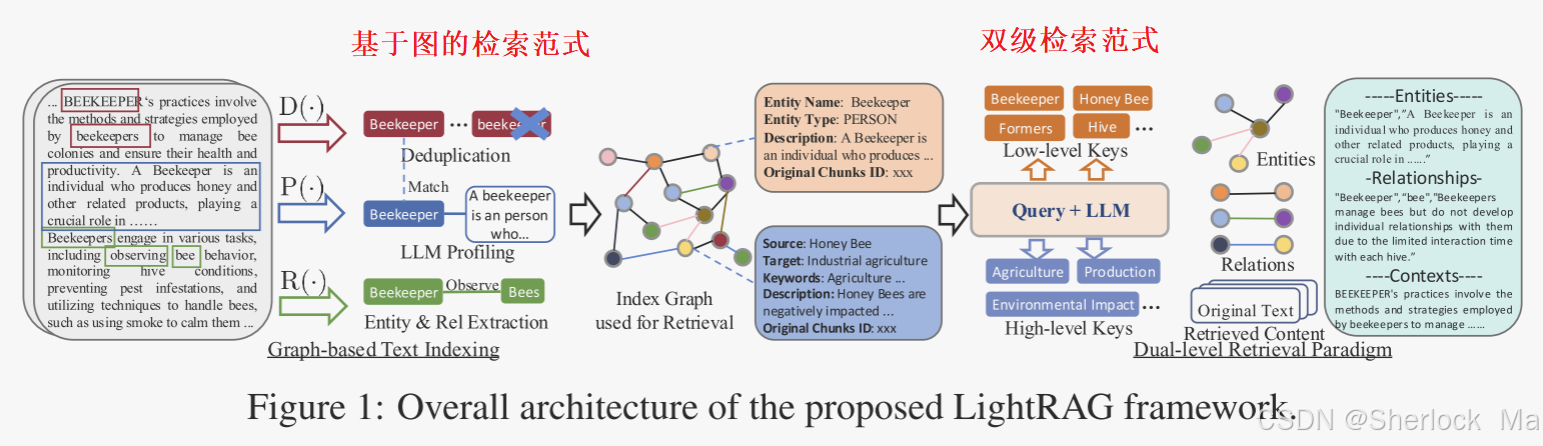
整个过程的案例如下:
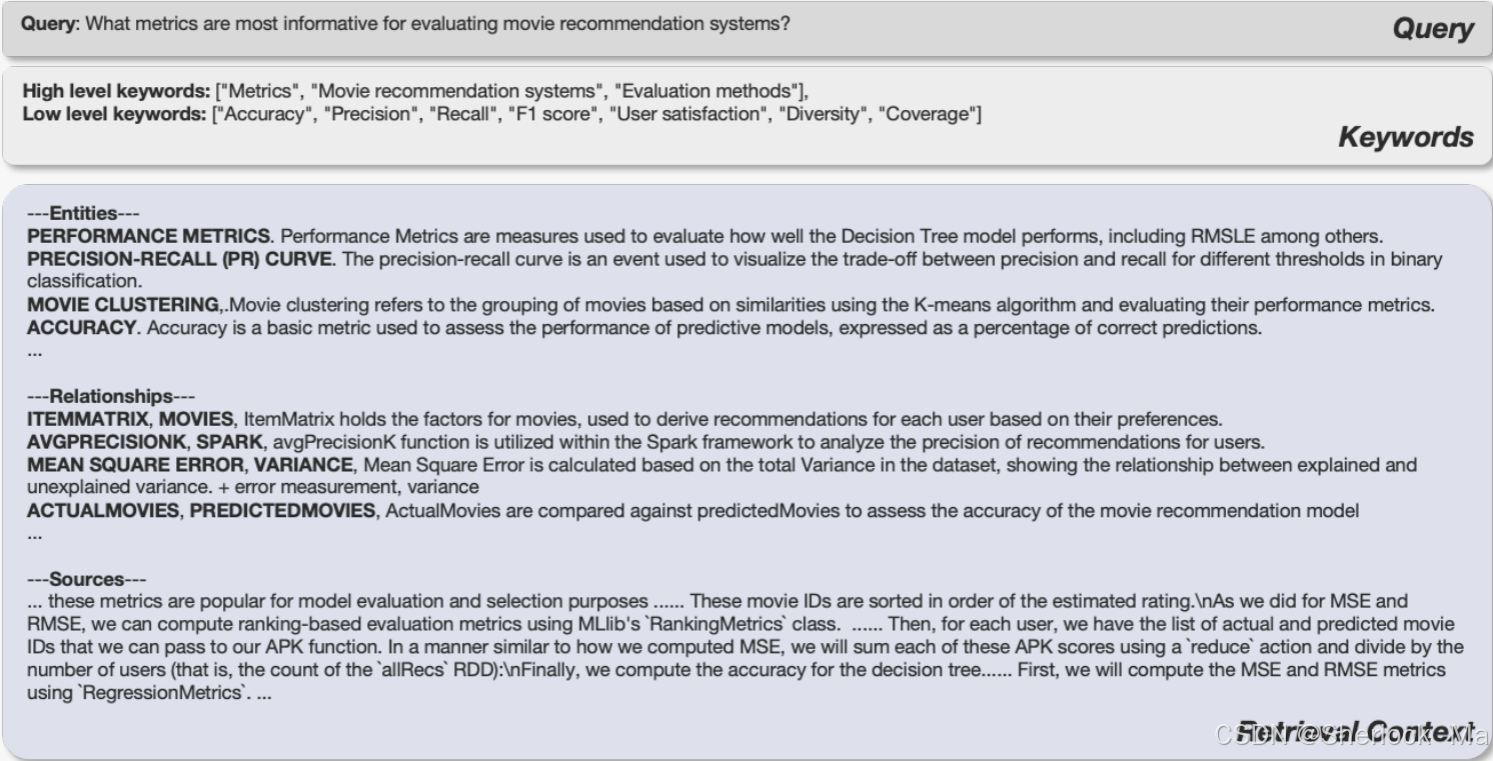

-
复杂度
该框架可分为两个主要部分。
第一部分是基于图的索引阶段。在这个阶段,LightRAG使用大语言模型(LLM)从每个文本块中提取实体和关系。因此,LLM需要调用次。重要的是,在此过程中没有涉及额外的开销,这使得该方法在管理新文本的更新方面非常高效。
该过程的第二部分涉及基于图的检索阶段。对于每个查询,首先利用大语言模型(LLM)来生成相关的关键字。与当前的检索增强生成(RAG)系统相似,LightRAG的检索机制依赖于基于向量的搜索。然而,与传统的RAG检索块不同,LightRAG专注于检索实体和关系。与GraphRAG中使用的基于社区的遍历方法相比,该方法显著降低了检索开销。
-
-
3.代码详解
我们以examples/lightrag_openai_compatible_demo.py为例。其中main()如下:
async def main():
try:
# Initialize RAG instance
rag = await initialize_rag()
with open(f"../library/file.txt", "r", encoding="utf-8") as f:
await rag.ainsert(f.read())
# Perform naive search
print(
await rag.aquery(
"XXXXXXXXXX?", param=QueryParam(mode="naive")
)
)
# ...
except Exception as e:
print(f"An error occurred: {e}")初始化
我们首先来看初始化部分
# Initialize RAG instance
rag = await initialize_rag()这段代码的主要功能是:创建并配置一个 LightRAG 实例,包括设置工作目录、语言模型函数和嵌入函数。初始化 LightRAG 的存储和管道状态。然后返回初始化完成的 LightRAG 实例。
async def initialize_rag():
embedding_dimension = await get_embedding_dim() # 获取嵌入维度
print(f"Detected embedding dimension: {embedding_dimension}")
rag = LightRAG( # 创建 LightRAG 实例
working_dir=WORKING_DIR,
llm_model_func=llm_model_func, # 语言模型函数
embedding_func=EmbeddingFunc( # 嵌入函数配置
embedding_dim=1024,
max_token_size=32768,
func=embedding_func,
),
)
await rag.initialize_storages() # 初始化存储。
await initialize_pipeline_status() # 返回初始化完成的 LightRAG 实例。
return rag
其中get_embedding_dim()的功能是获取嵌入向量的维度,具体步骤如下:
- 定义一个测试文本列表 test_text。
- 调用异步函数 embedding_func 计算测试文本的嵌入向量,返回形状为 [1, 1024] 的数组。
- 获取嵌入向量的第二维尺寸(即嵌入维度)。
- 返回嵌入维度值。
async def get_embedding_dim(): # 获取嵌入维度
test_text = ["This is a test sentence."]
embedding = await embedding_func(test_text) # [b,embed_size]=[1,1024]
embedding_dim = embedding.shape[1]
return embedding_dim其中lightrag的初始化参数如下:已全部加上注释
@final
@dataclass
class LightRAG:
"""LightRAG: Simple and Fast Retrieval-Augmented Generation."""
# Directory
# ---
working_dir: str = field( # 缓存和临时文件的存储目录
default=f"./lightrag_cache_{datetime.now().strftime('%Y-%m-%d-%H:%M:%S')}"
)
"""Directory where cache and temporary files are stored."""
# Storage
# ---
kv_storage: str = field(default="JsonKVStorage")
"""Storage backend for key-value data.""" # 键值对存储
vector_storage: str = field(default="NanoVectorDBStorage")
"""Storage backend for vector embeddings.""" # 向量存储
graph_storage: str = field(default="NetworkXStorage")
"""Storage backend for knowledge graphs.""" # 图存储
doc_status_storage: str = field(default="JsonDocStatusStorage")
"""Storage type for tracking document processing statuses.""" # 文档状态跟踪存储
# Logging (Deprecated, use setup_logger in utils.py instead)
# ---
log_level: int | None = field(default=None) # 日志级别
log_file_path: str | None = field(default=None) # 日志文件路径
# Entity extraction
# ---
entity_extract_max_gleaning: int = field(default=1) # 设置最大实体提取次数
"""Maximum number of entity extraction attempts for ambiguous content."""
entity_summary_to_max_tokens: int = field( # 设置实体摘要的最大令牌数
default=int(os.getenv("MAX_TOKEN_SUMMARY", 500))
)
# Text chunking
# ---
chunk_token_size: int = field(default=int(os.getenv("CHUNK_SIZE", 1200))) # 设置每个文本块的最大令牌数
"""Maximum number of tokens per text chunk when splitting documents."""
chunk_overlap_token_size: int = field( # 设置相邻文本块之间的重叠令牌数
default=int(os.getenv("CHUNK_OVERLAP_SIZE", 100))
)
"""Number of overlapping tokens between consecutive text chunks to preserve context."""
tiktoken_model_name: str = field(default="gpt-4o-mini") # 指定用于分词的模型名称,默认为 gpt-4o-mini
"""Model name used for tokenization when chunking text."""
"""Maximum number of tokens used for summarizing extracted entities."""
chunking_func: Callable[ # 自定义文本块分割函数
[
str,
str | None,
bool,
int,
int,
str,
],
list[dict[str, Any]],
] = field(default_factory=lambda: chunking_by_token_size)
"""
Custom chunking function for splitting text into chunks before processing.
The function should take the following parameters:
- `content`: The text to be split into chunks.
- `split_by_character`: The character to split the text on. If None, the text is split into chunks of `chunk_token_size` tokens.
- `split_by_character_only`: If True, the text is split only on the specified character.
- `chunk_token_size`: The maximum number of tokens per chunk.
- `chunk_overlap_token_size`: The number of overlapping tokens between consecutive chunks.
- `tiktoken_model_name`: The name of the tiktoken model to use for tokenization.
The function should return a list of dictionaries, where each dictionary contains the following keys:
- `tokens`: The number of tokens in the chunk.
- `content`: The text content of the chunk.
Defaults to `chunking_by_token_size` if not specified.
"""
# Node embedding
# ---
node_embedding_algorithm: str = field(default="node2vec") # 节点嵌入算法
"""Algorithm used for node embedding in knowledge graphs."""
node2vec_params: dict[str, int] = field( # node2vec 参数
default_factory=lambda: {
"dimensions": 1536,
"num_walks": 10,
"walk_length": 40,
"window_size": 2,
"iterations": 3,
"random_seed": 3,
}
)
"""Configuration for the node2vec embedding algorithm:
- dimensions: Number of dimensions for embeddings.
- num_walks: Number of random walks per node.
- walk_length: Number of steps per random walk.
- window_size: Context window size for training.
- iterations: Number of iterations for training.
- random_seed: Seed value for reproducibility.
"""
# Embedding
# ---
embedding_func: EmbeddingFunc | None = field(default=None)
"""Function for computing text embeddings. Must be set before use.""" # 计算文本嵌入的函数,必须在使用前设置。
embedding_batch_num: int = field(default=int(os.getenv("EMBEDDING_BATCH_NUM", 32))) # 设置嵌入批次的大小
"""Batch size for embedding computations."""
embedding_func_max_async: int = field( # :并发调用嵌入函数的最大数量
default=int(os.getenv("EMBEDDING_FUNC_MAX_ASYNC", 16))
)
"""Maximum number of concurrent embedding function calls."""
embedding_cache_config: dict[str, Any] = field( # 嵌入缓存配置
default_factory=lambda: {
"enabled": False,
"similarity_threshold": 0.95,
"use_llm_check": False,
}
)
"""Configuration for embedding cache.
- enabled: If True, enables caching to avoid redundant computations.
- similarity_threshold: Minimum similarity score to use cached embeddings.
- use_llm_check: If True, validates cached embeddings using an LLM.
"""
# LLM Configuration
# ---
llm_model_func: Callable[..., object] | None = field(default=None) # LLM模型函数
"""Function for interacting with the large language model (LLM). Must be set before use."""
llm_model_name: str = field(default="gpt-4o-mini") # 指定使用的LLM模型名称
"""Name of the LLM model used for generating responses."""
llm_model_max_token_size: int = field(default=int(os.getenv("MAX_TOKENS", 32768))) # 单个LLM响应的最大令牌数
"""Maximum number of tokens allowed per LLM response."""
llm_model_max_async: int = field(default=int(os.getenv("MAX_ASYNC", 4))) # 最大并发LLM调用数
"""Maximum number of concurrent LLM calls."""
llm_model_kwargs: dict[str, Any] = field(default_factory=dict) # LLM模型函数的额外参数,默认为空字典。
"""Additional keyword arguments passed to the LLM model function."""
# Storage
# ---
vector_db_storage_cls_kwargs: dict[str, Any] = field(default_factory=dict) # 用于存储向量数据库的额外参数,默认为空字典。
"""Additional parameters for vector database storage."""
namespace_prefix: str = field(default="") # 为不同环境中的存储数据提供命名空间前缀,默认为空字符串。
"""Prefix for namespacing stored data across different environments."""
enable_llm_cache: bool = field(default=True) # 启用 LLM 响应缓存以避免冗余计算,默认为 True。
"""Enables caching for LLM responses to avoid redundant computations."""
enable_llm_cache_for_entity_extract: bool = field(default=True) # 启用实体提取步骤的缓存以减少 LLM 成本,默认为 True。
"""If True, enables caching for entity extraction steps to reduce LLM costs."""
# Extensions
# ---
max_parallel_insert: int = field(default=int(os.getenv("MAX_PARALLEL_INSERT", 2))) # 最大并行插入数
"""Maximum number of parallel insert operations."""
addon_params: dict[str, Any] = field( # 插件参数
default_factory=lambda: {
"language": os.getenv("SUMMARY_LANGUAGE", PROMPTS["DEFAULT_LANGUAGE"])
}
)
# Storages Management
# ---
auto_manage_storages_states: bool = field(default=True) # 自动管理存储状态
"""If True, lightrag will automatically calls initialize_storages and finalize_storages at the appropriate times."""
# Storages Management
# ---
convert_response_to_json_func: Callable[[str], dict[str, Any]] = field( # 自定义函数
default_factory=lambda: convert_response_to_json
)
"""
Custom function for converting LLM responses to JSON format.
The default function is :func:`.utils.convert_response_to_json`.
"""
cosine_better_than_threshold: float = field( # 默认值
default=float(os.getenv("COSINE_THRESHOLD", 0.2))
)
_storages_status: StoragesStatus = field(default=StoragesStatus.NOT_CREATED)其中initialize_storages()实现了一个异步方法,用于初始化多个存储组件。其主要步骤包括:
-
检查存储状态是否为
CREATED。 -
遍历多个存储组件,将每个组件的初始化任务添加到任务列表中。
-
使用
asyncio.gather并发执行所有初始化任务。 -
初始化完成后,更新存储状态为
INITIALIZED,并记录日志。
async def initialize_storages(self):
"""Asynchronously initialize the storages"""
if self._storages_status == StoragesStatus.CREATED:
tasks = []
for storage in (
self.full_docs,
self.text_chunks,
self.entities_vdb,
self.relationships_vdb,
self.chunks_vdb,
self.chunk_entity_relation_graph,
self.llm_response_cache,
self.doc_status,
):
if storage:
tasks.append(storage.initialize()) # 将其初始化任务添加到任务列表中。
await asyncio.gather(*tasks) # asyncio.gather 并发执行所有初始化任务。
self._storages_status = StoragesStatus.INITIALIZED # 初始化完成后,更新存储状态为 StoragesStatus.INITIALIZED,并记录日志。
logger.debug("Initialized Storages")自此,lightRAG的初始化部分就结束了
-
query
print(
await rag.aquery(
"XXXXXXXXXXXX?", param=QueryParam(mode="naive")
)
)aquery 方法根据 param.mode 的值选择不同的查询模式(kg_query、naive_query 或 mix_kg_vector_query),并执行异步查询。
async def aquery()
# If a custom model is provided in param, temporarily update global config
global_config = asdict(self)
if param.mode in ["local", "global", "hybrid"]: # 如果 param.mode 是 local、global 或 hybrid,调用 kg_query。
response = await kg_query(
query.strip(),
self.chunk_entity_relation_graph,
self.entities_vdb,
self.relationships_vdb,
self.text_chunks,
param,
global_config,
hashing_kv=self.llm_response_cache, # Directly use llm_response_cache
system_prompt=system_prompt,
)
elif param.mode == "naive": # 如果 param.mode 是 naive,调用 naive_query。
response = await naive_query(
query.strip(),
self.chunks_vdb,
self.text_chunks,
param,
global_config,
hashing_kv=self.llm_response_cache, # Directly use llm_response_cache
system_prompt=system_prompt,
)
elif param.mode == "mix": # 如果 param.mode 是 mix,调用 mix_kg_vector_query。
response = await mix_kg_vector_query(
query.strip(),
self.chunk_entity_relation_graph,
self.entities_vdb,
self.relationships_vdb,
self.chunks_vdb,
self.text_chunks,
param,
global_config,
hashing_kv=self.llm_response_cache, # Directly use llm_response_cache
system_prompt=system_prompt,
)
else:
raise ValueError(f"Unknown mode {param.mode}")
await self._query_done()
return response-
mode=naive
我们以mode=naive为例,其代码位于lightrag/operate.py下的naive_query()
- 缓存处理:首先通过compute_args_hash生成查询的哈希值,并调用handle_cache检查缓存中是否存在对应响应。如果存在,直接返回缓存结果。
- 向量数据库查询:若缓存未命中,从chunks_vdb中查询与输入查询最相关的文本块。
- 过滤和截断:从text_chunks_db获取相关文本块,过滤无效数据并根据最大令牌数截断内容。
- 生成系统提示:根据上下文和历史对话生成系统提示,若只需上下文或提示,直接返回相应内容。
- 模型推理:调用语言模型生成响应,并清理多余内容。
- 保存缓存:将生成的响应保存到缓存中,供后续使用。
完整代码及注释如下:
async def naive_query(
query: str,
chunks_vdb: BaseVectorStorage,
text_chunks_db: BaseKVStorage,
query_param: QueryParam,
global_config: dict[str, str],
hashing_kv: BaseKVStorage | None = None,
system_prompt: str | None = None,
) -> str | AsyncIterator[str]:
# 1.处理hash值 Handle cache
use_model_func = ( # 定义调用大模型的方法
query_param.model_func
if query_param.model_func
else global_config["llm_model_func"]
)
args_hash = compute_args_hash(query_param.mode, query, cache_type="query") # 生成查询的哈希值
cached_response, quantized, min_val, max_val = await handle_cache( # 检查缓存中是否存在对应响应
hashing_kv, args_hash, query, query_param.mode, cache_type="query"
)
if cached_response is not None: # 如果存在,直接返回缓存结果。
return cached_response
# 2.向量数据库查询
results = await chunks_vdb.query( # 从向量数据库中查询与输入查询相关的文本块,并判断查询结果是否为空。
query, top_k=query_param.top_k, ids=query_param.ids
)
if not len(results): # 如果查询结果为空(即 results 的长度为 0),直接返回预定义的失败响应 PROMPTS["fail_response"]。
return PROMPTS["fail_response"]
# 3.过滤和截断
chunks_ids = [r["id"] for r in results] # 获取查询结果中的文本块的 ID
chunks = await text_chunks_db.get_by_ids(chunks_ids) # 并使用 text_chunks_db 从数据库中获取对应的文本块。
# 过滤无效数据。Filter out invalid chunks
valid_chunks = [
chunk for chunk in chunks if chunk is not None and "content" in chunk
]
if not valid_chunks:
logger.warning("No valid chunks found after filtering")
return PROMPTS["fail_response"]
maybe_trun_chunks = truncate_list_by_token_size( # 根据最大令牌数截断内容
valid_chunks,
key=lambda x: x["content"],
max_token_size=query_param.max_token_for_text_unit,
)
if not maybe_trun_chunks:
logger.warning("No chunks left after truncation")
return PROMPTS["fail_response"]
logger.debug(
f"Truncate chunks from {len(chunks)} to {len(maybe_trun_chunks)} (max tokens:{query_param.max_token_for_text_unit})"
)
section = "\n--New Chunk--\n".join([c["content"] for c in maybe_trun_chunks]) # 合并文本块
if query_param.only_need_context:
return section
# Process conversation history
history_context = ""
if query_param.conversation_history:
history_context = get_conversation_turns(
query_param.conversation_history, query_param.history_turns
)
# 4.生成系统提示
sys_prompt_temp = system_prompt if system_prompt else PROMPTS["naive_rag_response"]
sys_prompt = sys_prompt_temp.format(
content_data=section, # 知识库
response_type=query_param.response_type, # 响应类型
history=history_context, # 历史
)
if query_param.only_need_prompt:
return sys_prompt
len_of_prompts = len(encode_string_by_tiktoken(query + sys_prompt)) # 计算提示的令牌数
logger.debug(f"[naive_query]Prompt Tokens: {len_of_prompts}")
# 5.模型推理
response = await use_model_func(
query,
system_prompt=sys_prompt,
)
if len(response) > len(sys_prompt): # 从响应中删除提示部分,并返回剩余部分。
response = (
response[len(sys_prompt) :]
.replace(sys_prompt, "")
.replace("user", "")
.replace("model", "")
.replace(query, "")
.replace("<system>", "")
.replace("</system>", "")
.strip()
)
# 6.保存缓存Save to cache
await save_to_cache(
hashing_kv,
CacheData(
args_hash=args_hash,
content=response,
prompt=query,
quantized=quantized,
min_val=min_val,
max_val=max_val,
mode=query_param.mode,
cache_type="query",
),
)
return response接下来我们详细解释:
1.处理hash值,包括计算hash和在已有库中比对是否存在。
# 1.处理hash值 Handle cache
use_model_func = ( # 定义调用大模型的方法
query_param.model_func
if query_param.model_func
else global_config["llm_model_func"]
)
args_hash = compute_args_hash(query_param.mode, query, cache_type="query") # 生成查询的哈希值
cached_response, quantized, min_val, max_val = await handle_cache( # 检查缓存中是否存在对应响应
hashing_kv, args_hash, query, query_param.mode, cache_type="query"
)
if cached_response is not None: # 如果存在,直接返回缓存结果。
return cached_responsecompute_args_hash()
def compute_args_hash(*args: Any, cache_type: str | None = None) -> str:
"""Compute a hash for the given arguments.
Args:
*args: Arguments to hash
cache_type: Type of cache (e.g., 'keywords', 'query', 'extract')
Returns:
str: Hash string
"""
import hashlib
# Convert all arguments to strings and join them
args_str = "".join([str(arg) for arg in args]) # 将所有输入参数转换为字符串并拼接成一个整体字符串。 如:['naive',"问题"]->naive问题
if cache_type: # 如果提供了cache_type参数,则将其作为前缀添加到字符串中。
args_str = f"{cache_type}:{args_str}" # 如:query:naive问题
# Compute MD5 hash
return hashlib.md5(args_str.encode()).hexdigest() # 使用MD5算法对最终字符串进行哈希计算,并返回十六进制表示的哈希值。其中handle_cache()的核心代码如下:
async def handle_cache():
......
if exists_func(hashing_kv, "get_by_mode_and_id"): # 检查hashing_kv对象是否包含get_by_mode_and_id方法。
mode_cache = await hashing_kv.get_by_mode_and_id(mode, args_hash) or {} # 如果存在该方法,则调用get_by_mode_and_id方法,传入mode和args_hash参数,并返回结果或空字典。
else: # 如果不存在该方法,则调用get_by_id方法,传入mode参数,并返回结果或空字典。
mode_cache = await hashing_kv.get_by_id(mode) or {} # model_cache是所有缓存的hash值和对应文字内容(query、answer等)。
if args_hash in mode_cache: # 比对hash值是否在缓存中。
logger.debug(f"Non-embedding cached hit(mode:{mode} type:{cache_type})")
return mode_cache[args_hash]["return"], None, None, None # 如果存在,则返回缓存内容。mode_cache如下:
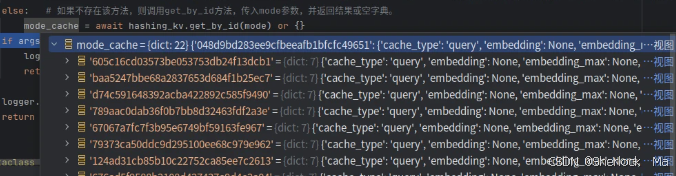
从存储中根据指定的 id 获取数据。
async def get_by_id(self, id: str) -> dict[str, Any] | None:
async with self._storage_lock: # 使用 async with self._storage_lock 确保线程安全,避免并发访问时的数据冲突
return self._data.get(id) # 返回与 id 对应的值,这里是‘naive’、‘global’等2.向量数据库查询:若缓存未命中,从chunks_vdb中查询与输入查询最相关的文本块。
results = await chunks_vdb.query( # 从向量数据库中查询与输入查询相关的文本块,并判断查询结果是否为空。
query, top_k=query_param.top_k, ids=query_param.ids
)
if not len(results): # 如果查询结果为空(即 results 的长度为 0),直接返回预定义的失败响应 PROMPTS["fail_response"]。
return PROMPTS["fail_response"]lightrag/kg/nano_vector_db_impl.py
async def query(
self, query: str, top_k: int, ids: list[str] | None = None
) -> list[dict[str, Any]]:
# Execute embedding outside of lock to avoid long lock times
embedding = await self.embedding_func([query]) # 接收查询字符串 query,计算其嵌入向量 embedding。
embedding = embedding[0] # [b,embed_size]=[1,1024]
client = await self._get_client() # 获取客户端实例 client
results = client.query( # 通过 client.query 方法基于嵌入向量查询最相似的前 top_k 个结果。
query=embedding,
top_k=top_k,
better_than_threshold=self.cosine_better_than_threshold,
)
results = [ # 对查询结果进行格式化处理,提取每个数据点的 id、distance 和 created_at 字段。
{
**dp,
"id": dp["__id__"],
"distance": dp["__metrics__"],
"created_at": dp.get("__created_at__"),
}
for dp in results
]
return results # 返回格式化后的结果列表。nano_vectordb/dbs.py
def query():
return self.usable_metrics[self.metric](
query, top_k, better_than_threshold, filter_lambda=filter_lambda
)其中 usable_metrics()如下:用于执行基于余弦相似度的查询。它从一个存储矩阵中检索与输入查询向量最相似的条目,并根据给定的条件进行过滤和排序。
def _cosine_query(
self,
query: np.ndarray,
top_k: int,
better_than_threshold: float,
filter_lambda: ConditionLambda = None,
):
query = normalize(query) # 对输入查询向量 query 进行归一化处理。
if filter_lambda is None: # 如果没有过滤条件 (filter_lambda is None),使用整个存储矩阵
use_matrix = self.__storage["matrix"] # [len,embed_size]=[知识库大小(vdb_chunks.json),1024]
filter_index = np.arange(len(self.__storage["data"]))
else: # 否则根据过滤条件筛选出符合条件的索引及对应的子矩阵。
filter_index = np.array(
[
i
for i, data in enumerate(self.__storage["data"])
if filter_lambda(data)
]
)
use_matrix = self.__storage["matrix"][filter_index]
scores = np.dot(use_matrix, query) # 计算筛选后的矩阵与查询向量的点积,得到相似度分数。 [len]
sort_index = np.argsort(scores)[-top_k:] # 对分数排序,选取前 top_k 个最高分的索引
sort_index = sort_index[::-1] # 按降序排列。
sort_abs_index = filter_index[sort_index]
results = []
for abs_i, rel_i in zip(sort_abs_index, sort_index): # 遍历排序后的索引,将分数高于阈值的结果添加到结果列表中。
if (
better_than_threshold is not None
and scores[rel_i] < better_than_threshold
):
break
results.append({**self.__storage["data"][abs_i], f_METRICS: scores[rel_i]})
return results3.过滤和截断:从text_chunks_db获取相关文本块,过滤无效数据并根据最大令牌数截断内容。
# 3.过滤和截断
chunks_ids = [r["id"] for r in results] # 获取查询结果中的文本块的 ID
chunks = await text_chunks_db.get_by_ids(chunks_ids) # 并使用 text_chunks_db 从数据库中获取对应的文本块。
# 过滤无效数据。Filter out invalid chunks
valid_chunks = [
chunk for chunk in chunks if chunk is not None and "content" in chunk
]
maybe_trun_chunks = truncate_list_by_token_size( # 根据最大令牌数截断内容
valid_chunks,
key=lambda x: x["content"],
max_token_size=query_param.max_token_for_text_unit,
)
section = "\n--New Chunk--\n".join([c["content"] for c in maybe_trun_chunks]) # 合并文本块首先通过get_by_ids()从数据库中获取对应的文本块。
async def get_by_ids(self, ids: list[str]) -> list[dict[str, Any]]:
async with self._storage_lock: # k确保并发安全
return [
(
{k: v for k, v in self._data[id].items()} # 如果self._data中存在该id,返回其键值对的副本(通过字典推导式实现)。
if self._data.get(id, None)
else None # 如果不存在,返回None。
)
for id in ids
]def truncate_list_by_token_size(
list_data: list[Any], key: Callable[[Any], str], max_token_size: int
) -> list[int]:
"""Truncate a list of data by token size"""
if max_token_size <= 0: # 如果最大令牌数 max_token_size 小于等于0,直接返回空列表。
return []
tokens = 0
for i, data in enumerate(list_data):
tokens += len(encode_string_by_tiktoken(key(data))) # 计算其令牌长度,累加到 tokens。
if tokens > max_token_size: # 如果累计令牌数超过 max_token_size,返回当前索引前的子列表
return list_data[:i]
return list_data4.生成系统提示
# 4.生成系统提示
sys_prompt_temp = system_prompt if system_prompt else PROMPTS["naive_rag_response"]
sys_prompt = sys_prompt_temp.format(
content_data=section, # 知识库
response_type=query_param.response_type, # 响应类型
history=history_context, # 历史
)其中 sys_prompt 的结果如下:
---Role---
You are a helpful assistant responding to user query about Document Chunks provided below.
---Goal---
Generate a concise response based on Document Chunks and follow Response Rules, considering both the conversation history and the current query. Summarize all information in the provided Document Chunks, and incorporating general knowledge relevant to the Document Chunks. Do not include information not provided by Document Chunks.
When handling content with timestamps:
1. Each piece of content has a "created_at" timestamp indicating when we acquired this knowledge
2. When encountering conflicting information, consider both the content and the timestamp
3. Don't automatically prefer the most recent content - use judgment based on the context
4. For time-specific queries, prioritize temporal information in the content before considering creation timestamps
---Conversation History---
---Document Chunks---
# 资料库内容
---Response Rules---
- Target format and length: Multiple Paragraphs
- Use markdown formatting with appropriate section headings
- Please respond in the same language as the user's question.
- Ensure the response maintains continuity with the conversation history.
- List up to 5 most important reference sources at the end under "References" section. Clearly indicating whether each source is from Knowledge Graph (KG) or Vector Data (DC), and include the file path if available, in the following format: [KG/DC] Source content (File: file_path)
- If you don't know the answer, just say so.
- Do not include information not provided by the Document Chunks.
5.模型推理
# 5.模型推理
response = await use_model_func(
query,
system_prompt=sys_prompt,
)
if len(response) > len(sys_prompt): # 从响应中删除提示部分,并返回剩余部分。
response = (
response[len(sys_prompt) :]
.replace(sys_prompt, "")
.replace("user", "")
.replace("model", "")
.replace(query, "")
.replace("<system>", "")
.replace("</system>", "")
.strip()
)async def llm_model_func(
prompt, system_prompt=None, history_messages=[], keyword_extraction=False, **kwargs
) -> str:
return await openai_complete_if_cache( # 调用 openai_complete_if_cache 方法生成文本。
# "Qwen2.5-3B-Instruct",
"Qwen2.5-7B-Instruct-GPTQ-Int4",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key='666', # os.getenv("UPSTAGE_API_KEY"),
base_url="http://0.0.0.0:8000/v1",
**kwargs,
)6.保存缓存Save to cache
# 6.保存缓存Save to cache
await save_to_cache(
hashing_kv,
CacheData(
args_hash=args_hash,
content=response,
prompt=query,
quantized=quantized,
min_val=min_val,
max_val=max_val,
mode=query_param.mode,
cache_type="query",
),
)async def save_to_cache(hashing_kv, cache_data: CacheData):
"""Save data to cache, with improved handling for streaming responses and duplicate content.
Args:
hashing_kv: The key-value storage for caching
cache_data: The cache data to save
"""
# Skip if storage is None or content is a streaming response 检查 hashing_kv 是否为 None 或 cache_data.content 是否为空,若满足任一条件则直接返回。
if hashing_kv is None or not cache_data.content:
return
# If content is a streaming response, don't cache it 判断 cache_data.content 是否为异步迭代器(流式响应),若是则记录日志并返回。
if hasattr(cache_data.content, "__aiter__"):
logger.debug("Streaming response detected, skipping cache")
return
# Get existing cache data 检查 hashing_kv 是否存在 get_by_mode_and_id 若有则调用该方法获取缓存数据
if exists_func(hashing_kv, "get_by_mode_and_id"):
mode_cache = (
await hashing_kv.get_by_mode_and_id(cache_data.mode, cache_data.args_hash)
or {}
)
else: # 否则调用 get_by_id 方法。
mode_cache = await hashing_kv.get_by_id(cache_data.mode) or {}
# Check if we already have identical content cached 检查当前缓存中是否存在相同内容,若已存在且内容一致,则记录日志并返回。
if cache_data.args_hash in mode_cache:
existing_content = mode_cache[cache_data.args_hash].get("return")
if existing_content == cache_data.content:
logger.info(
f"Cache content unchanged for {cache_data.args_hash}, skipping update"
)
return
# Update cache with new content
mode_cache[cache_data.args_hash] = { # 更新缓存数据
"return": cache_data.content,
"cache_type": cache_data.cache_type,
"embedding": cache_data.quantized.tobytes().hex()
if cache_data.quantized is not None
else None,
"embedding_shape": cache_data.quantized.shape
if cache_data.quantized is not None
else None,
"embedding_min": cache_data.min_val,
"embedding_max": cache_data.max_val,
"original_prompt": cache_data.prompt,
}
# Only upsert if there's actual new content 方法将更新后的缓存数据保存。
await hashing_kv.upsert({cache_data.mode: mode_cache})-
mode=local
接下来,我们以mode=local为例,其流程如下:
- 缓存检查:计算查询的哈希值并检查缓存中是否存在对应响应,若存在则直接返回。
- 关键词提取:调用 extract_keywords_only 提取高、低级关键词,并处理空关键词的情况,调整查询模式。
- 上下文构建:根据关键词构建查询上下文,若仅需上下文则直接返回。
- 历史对话处理:生成历史对话上下文并构造系统提示。
- 模型调用:调用大模型生成响应,并清理响应内容。
- 缓存保存:将生成的响应保存到缓存中并返回。
注意,与标准RAG(naive)不同的是,local模式会调用两次大模型,一次用于关键词提取,另一次用于生成响应。
其中,mode=local、global、hybrid会运行下面的代码:
if param.mode in ["local", "global", "hybrid"]: # 如果 param.mode 是 local、global 或 hybrid,调用 kg_query。
response = await kg_query(
query.strip(),
self.chunk_entity_relation_graph,
self.entities_vdb,
self.relationships_vdb,
self.text_chunks,
param,
global_config,
hashing_kv=self.llm_response_cache, # Directly use llm_response_cache
system_prompt=system_prompt,
)kq_query()如下:
- 缓存处理:生成查询的哈希值并检查缓存,若命中则直接返回缓存结果。
- 关键词提取:调用 extract_keywords_only 提取高、低级关键词,并根据关键词情况调整查询模式。
- 上下文构建:基于关键词构建查询上下文,若仅需上下文或上下文为空,则直接返回相应结果。
- 系统提示生成:处理对话历史并生成系统提示,若仅需提示则直接返回。
- 大模型调用:调用大模型获取响应,并清理响应内容。
- 缓存保存:将最终响应保存到缓存中并返回。
async def kg_query():
# 1.处理hash值 Handle cacheHandle cache
use_model_func = ( # 定义调用大模型的方法
query_param.model_func
if query_param.model_func
else global_config["llm_model_func"]
)
args_hash = compute_args_hash(query_param.mode, query, cache_type="query") # 生成查询的哈希值
cached_response, quantized, min_val, max_val = await handle_cache( # 检查缓存中是否存在对应响应
hashing_kv, args_hash, query, query_param.mode, cache_type="query"
)
if cached_response is not None: # 如果存在,直接返回缓存结果。
return cached_response
# 2.关键词提取:调用 extract_keywords_only 提取高、低级关键词 低级是细节,高级是抽象的 Extract keywords using extract_keywords_only function which already supports conversation history y
hl_keywords, ll_keywords = await extract_keywords_only(
query, query_param, global_config, hashing_kv
)
logger.debug(f"High-level keywords: {hl_keywords}")
logger.debug(f"Low-level keywords: {ll_keywords}")
# Handle empty keywords 处理空关键词的情况
if hl_keywords == [] and ll_keywords == []:
logger.warning("low_level_keywords and high_level_keywords is empty")
return PROMPTS["fail_response"]
if ll_keywords == [] and query_param.mode in ["local", "hybrid"]:
logger.warning(
"low_level_keywords is empty, switching from %s mode to global mode",
query_param.mode,
)
query_param.mode = "global"
if hl_keywords == [] and query_param.mode in ["global", "hybrid"]:
logger.warning(
"high_level_keywords is empty, switching from %s mode to local mode",
query_param.mode,
)
query_param.mode = "local"
ll_keywords_str = ", ".join(ll_keywords) if ll_keywords else "" # '词汇1, 词汇2'
hl_keywords_str = ", ".join(hl_keywords) if hl_keywords else ""
# 3.上下文构建:根据关键词构建查询上下文Build context
context = await _build_query_context(
ll_keywords_str,
hl_keywords_str,
knowledge_graph_inst,
entities_vdb,
relationships_vdb,
text_chunks_db,
query_param,
)
if query_param.only_need_context:
return context
if context is None:
return PROMPTS["fail_response"]
# 4.系统提示生成 Process conversation history
history_context = ""
if query_param.conversation_history:
history_context = get_conversation_turns(
query_param.conversation_history, query_param.history_turns
)
sys_prompt_temp = system_prompt if system_prompt else PROMPTS["rag_response"]
sys_prompt = sys_prompt_temp.format(
context_data=context,
response_type=query_param.response_type,
history=history_context,
)
if query_param.only_need_prompt:
return sys_prompt
len_of_prompts = len(encode_string_by_tiktoken(query + sys_prompt))
logger.debug(f"[kg_query]Prompt Tokens: {len_of_prompts}")
# 5.调用大模型,获取响应
response = await use_model_func(
query,
system_prompt=sys_prompt,
stream=query_param.stream,
)
if isinstance(response, str) and len(response) > len(sys_prompt):
response = (
response.replace(sys_prompt, "")
.replace("user", "")
.replace("model", "")
.replace(query, "")
.replace("<system>", "")
.replace("</system>", "")
.strip()
)
# 6.保存缓存 Save to cache
await save_to_cache(
hashing_kv,
CacheData(
args_hash=args_hash,
content=response,
prompt=query,
quantized=quantized,
min_val=min_val,
max_val=max_val,
mode=query_param.mode,
cache_type="query",
),
)
return responseextract_keywords_only()如下:
- 缓存处理:通过compute_args_hash生成缓存键,调用handle_cache检查是否存在缓存数据。若存在且格式正确,则直接返回高、低级关键词。
- 构建示例和语言:从global_config中获取示例数量和语言设置,构建关键词提取的示例字符串。
- 处理对话历史:若存在对话历史,调用get_conversation_turns生成历史上下文。
- 构建提示词:使用预定义模板PROMPTS["keywords_extraction"]生成关键词提取的提示词,并计算其token长度。
- 调用LLM模型:通过use_model_func调用LLM模型进行关键词提取,解析返回的JSON数据。
- 缓存结果:若提取到关键词,调用save_to_cache保存结果到缓存。
- 返回结果:返回高、低级关键词列表。
async def extract_keywords_only()
# 1.处理缓存 Handle cache if needed - add cache type for keywords
args_hash = compute_args_hash(param.mode, text, cache_type="keywords") # 生成缓存键
cached_response, quantized, min_val, max_val = await handle_cache( # 检查是否存在缓存数据
hashing_kv, args_hash, text, param.mode, cache_type="keywords"
)
if cached_response is not None:
try:
keywords_data = json.loads(cached_response)
return keywords_data["high_level_keywords"], keywords_data[
"low_level_keywords"
]
except (json.JSONDecodeError, KeyError):
logger.warning(
"Invalid cache format for keywords, proceeding with extraction"
)
# 2.构建示例和语言 Build the examples
example_number = global_config["addon_params"].get("example_number", None)
if example_number and example_number < len(PROMPTS["keywords_extraction_examples"]):
examples = "\n".join(
PROMPTS["keywords_extraction_examples"][: int(example_number)]
)
else:
examples = "\n".join(PROMPTS["keywords_extraction_examples"])
language = global_config["addon_params"].get(
"language", PROMPTS["DEFAULT_LANGUAGE"]
)
# 3.处理对话历史 Process conversation history
history_context = ""
if param.conversation_history:
history_context = get_conversation_turns(
param.conversation_history, param.history_turns
)
# 4. Build the keyword-extraction prompt
kw_prompt = PROMPTS["keywords_extraction"].format( # 构建提示词,生成关键词提取的提示词
query=text, examples=examples, language=language, history=history_context
)
print(kw_prompt)
len_of_prompts = len(encode_string_by_tiktoken(kw_prompt))
logger.debug(f"[kg_query]Prompt Tokens: {len_of_prompts}")
# 5. 调用LLM模型 Call the LLM for keyword extraction
use_model_func = (
param.model_func if param.model_func else global_config["llm_model_func"]
)
result = await use_model_func(kw_prompt, keyword_extraction=True)
# 6. 解析返回的JSON数据 Parse out JSON from the LLM response
match = re.search(r"\{.*\}", result, re.DOTALL)
if not match:
logger.error("No JSON-like structure found in the LLM respond.")
return [], []
try:
keywords_data = json.loads(match.group(0))
except json.JSONDecodeError as e:
logger.error(f"JSON parsing error: {e}")
return [], []
hl_keywords = keywords_data.get("high_level_keywords", []) # ['词汇1','词汇2']
ll_keywords = keywords_data.get("low_level_keywords", [])
# 7. 缓存结果 Cache only the processed keywords with cache type
if hl_keywords or ll_keywords:
cache_data = {
"high_level_keywords": hl_keywords,
"low_level_keywords": ll_keywords,
}
await save_to_cache(
hashing_kv,
CacheData(
args_hash=args_hash,
content=json.dumps(cache_data),
prompt=text,
quantized=quantized,
min_val=min_val,
max_val=max_val,
mode=param.mode,
cache_type="keywords",
),
)
return hl_keywords, ll_keywords其中kw_prompt如下 :
---Role---
You are a helpful assistant tasked with identifying both high-level and low-level keywords in the user's query and conversation history.
---Goal---
Given the query and conversation history, list both high-level and low-level keywords. High-level keywords focus on overarching concepts or themes, while low-level keywords focus on specific entities, details, or concrete terms.
---Instructions---
- Consider both the current query and relevant conversation history when extracting keywords
- Output the keywords in JSON format, it will be parsed by a JSON parser, do not add any extra content in output
- The JSON should have two keys:
- "high_level_keywords" for overarching concepts or themes
- "low_level_keywords" for specific entities or details
######################
---Examples---
######################
Example 1:
Query: "How does international trade influence global economic stability?"
################
Output:
{
"high_level_keywords": ["International trade", "Global economic stability", "Economic impact"],
"low_level_keywords": ["Trade agreements", "Tariffs", "Currency exchange", "Imports", "Exports"]
}
#############################
Example 2:
Query: "What are the environmental consequences of deforestation on biodiversity?"
################
Output:
{
"high_level_keywords": ["Environmental consequences", "Deforestation", "Biodiversity loss"],
"low_level_keywords": ["Species extinction", "Habitat destruction", "Carbon emissions", "Rainforest", "Ecosystem"]
}
#############################
Example 3:
Query: "What is the role of education in reducing poverty?"
################
Output:
{
"high_level_keywords": ["Education", "Poverty reduction", "Socioeconomic development"],
"low_level_keywords": ["School access", "Literacy rates", "Job training", "Income inequality"]
}
#############################
#############################
---Real Data---
######################
Conversation History:
Current Query: 问题
######################
The `Output` should be human text, not unicode characters. Keep the same language as `Query`.
Output:模型收到的提示词
<|im_start|>system\n
---Role---\n\n
You are a helpful assistant responding to user query about Knowledge Base provided below.
\n\n\n---Goal---\n\n
Generate a concise response based on Knowledge Base and follow Response Rules, considering both the conversation history and the current query. Summarize all information in the provided Knowledge Base, and incorporating general knowledge relevant to the Knowledge Base. Do not include information not provided by Knowledge Base.\n\nWhen handling relationships with timestamps:\n
1. Each relationship has a "created_at" timestamp indicating when we acquired this knowledge\n
2. When encountering conflicting relationships, consider both the semantic content and the timestamp\n
3. Don\'t automatically prefer the most recently created relationships - use judgment based on the context\n
4. For time-specific queries, prioritize temporal information in the content before considering creation timestamps
\n\n---Conversation History---\n\n\n
---Knowledge Base---\n
# 最后将实体、关系和来源数据格式化为字符串并返回。\n
-----Entities-----\n
```csv\n "id","entity","type","description","rank","created_at","file_path"\n"0","第二批‘全国高校黄大年式教师团队’","category","The seTeams\' from universities across China focuses on promoting high-quality education.","1","UNKNOWN","unknown_source"\n"1","教育部基础学科拔尖学生培养计划2.0基地","category","The base for the national key discipline of pi under the 2.0 plan focuses on nurturing top students in key disciplines.","0","UNKNOWN","unknown_source"\n"2","Zhengzhou University","organization","Zhengzhou University, also known as ZHENGZHOU UNIVERSITY (简称郑大、Zs located in Zhengzhou, Henan Province, China. Established in 1956, it was the first comprehensive university in New China and became a provincial university in 1958, mainly recruiting students from Henan Province. Zhengzhou University has expanded significantly over the years and now encompasses more than 6100 mu of land across four campuses and one research institute. In 1981, it became the first university in China to grant master\'s degrees, and in 1998, it obtained the authority to grant doctoral degrees in materials processing engineering and chemical engineering. In 2000, the university merged with Zhengzhou Industrial University and Henan Medical University to form the current Zhengzhou University. Zhengzhou University is recognized as a \'Ministry-Province Jointly Built University\' by the Ministry of Education and the Henan Provincial Government, and it is part of the \'Double First-Class\' initiative, with 118 undergraduate programs and 14 national-level distinctive programs. The institution is also a \'211 Engineering\' university and has been selected as part of the \'Middle and Western Regions University Comprehensive Strength Enhancement Project\' in 2012 and as a base for the \'Basis Student Cultivation Plan 2.0\' by the Ministry of Education in 2021. As of March 2024, Zhengzhou University offers 31 doctoral programs, 4 professional doctoral programs, 57 master\'s programs, 37 professional master\'s programs, and 31 postdoctoral research stations, hosting over 43,000 full-time undergraduate and postgraduate students.","9","UNKNOWN","unknown_source"\n"3","North China Electric Power University","organization","North China Electric Power University (NCEPU) is a national key university located in Beijing, under the direct administration of the Ministry of Education and co-built with a council composed of 12 large-scale power companies, including State Grid Corporation of China. It is a \'Double First-Class\' construction university, focusing on key disciplines under the 211 Project and the 985 Project.<SEP>North China Electric Power University is a national key university located in Beijing, under the direct administration of the Ministry of Education, and co-built with a council composed of 12 large-scale power companies, including State Grid Corporation of China. It is a \'Double First-Class\' construction university, focusing on key disciplines under the 211 Project and the 985 Project.","13","UNKNOWN","unknown_source"\n"4","郑州大学大学生创新创业基地(郑州大学众创空间)","organization","The Zhengzhou University Student Entrepreneurship and Innovation Base is a hub fnd innovation among university students.","0","UNKNOWN","unknown_source"\n"5","基础学科拔尖学生培养计划2.0基地","organization","Advanced Base for Talents in Key Basic Disciplines is a national program aimed at nurturingtudents in basic sciences.<SEP>The Advanced Base for Talents in Key Basic Disciplines is a national program aimed at nurturing outstanding students in basic sciences.","0","UNKNOWN","unknown_source"\n"6","教育部","organtion","Ministry of Education is the governing body responsible for approving higher education institutions and educational policies.<SEP>The Ministry of Education of China is responsible for education policies and standards.<SEP>The Ministry of Education supports and promotes the development of Soochow University as part of its broader educational reform efforts.<SEP>教育部于1960年10月将大连工学院确定为直属全国重点大学,并在1980年6月确院校之一。<SEP>教育部在1960年确定大连工学院为直属全国重点大学,并在1980年确定大连理工大学为设立少数民族班、实行定向定点招生的重点院校之一。<SEP>教育部是中国的教育主管部门,负责大连理工大学的管理和共建。<SEP>教育部是中国"211 Project","category","The 211 Project is a national initiative to support the development of first-class universities and disciplines in China.<SEP>The 211 Project is a national university development project under which North China Electric Power University is a key participant.","2","UNKNOWN","unknown_source"\n"8","黄大年式教师团队","organization","Huang Dayuan Model Teacher Teams are recognized national teacher teams for their y teaching and research contributions.","0","UNKNOWN","unknown_source"\n"9","关键金属与先进靶材料教师团队","category","The key metal and advanced target material teacher team focuses on teaching and research in materials science.","2","UNKNOWN","unknown_source"\n"10","化学拔尖学生培养基地","category","The advanced chemistry talent cultivation base focuses on nurturing outstanding chemistry students.","2","UNKNOWN","unknown_source"\n"1"organization","Zhengzhou University is a comprehensive university under the direct management of the Ministry of Education, known for its various disciplines and achievements in education and research.<SEP>Zhengzhou University is a key institution in China, focusing on teaching and research, and has been involved in multiple national-level projects and initiatives.<SEP>Zhengzhou University is a public university in Henan Province, China, known for its academic research and interdisciplinary collaborations.<SEP>郑州大学是一所综合性大学,拥有多个校区和下属学院。<SEP>郑州大学是一所综合性大学,涵盖了多个学科领域,包括理学、工学、哲学、社会科学等。","25985 Project is a national university construction project under which North China Electric Power University is a key participant.","1","UNKNOWN","unknown_source"\n"13","科技部关于印发2020年度国家备案众创空间的通知","orgrom the Ministry of Science and Technology regarding the inclusion of Zhengzhou University\'s student entrepreneurship and innovation base among national technology incubators.","0","UNKNOWN","unknown_source"\n"14","核心学区","location","核心教学区是郑州大学主校区的教学区域。","0","UNKNOWN","unknown_source"\n"15","学科创新引智基地(国家‘111计划’)","category","The discipline innovation and talent introduction bases (‘111 Project’) focu areas.","0","UNKNOWN","unknown_source"\n"16","《核心教学区》","category","《核心教学区》是郑州大学主校区的教学区域。","0","UNKNOWN","unknown_source"\n"17","主校区","geo","主校区是郑州大学的主要校区,位于学校的核心位置。,"Baoding is the current main campus of the university, where the university headquarters is located.","1","UNKNOWN","unknown_source"\n"19","主校区北校园","location","主校区北校园位于郑州市文化路97号,是郑州大学的另一个rce"\n"20","主校区东校园","location","主校区东校园位于郑州市大学北路40号,是郑州大学的另一个校区。","0","UNKNOWN","unknown_source"\n"21","Talent Training Program for Excellent Engineers","category","North China Electric for the Talent Training Program for Excellent Engineers.","1","UNKNOWN","unknown_source"\n"22","樊会涛","person","Professor Fan Huaitao is a Chinese engineering scientist and academician, currently serving as the presit of the Zhengzhou University Luoyang Campus.","0","UNKNOWN","unknown_source"\n"23","State Grid Corporation of China","organization","State Grid Corporation of China is one of the 12 large-scale power companies that co-build the university with the Ministry of Education.","1","UNKNOWN","unknown_source"\n"24","郑州大学理学院","category","The School of Science at Zhengzhou University focuses on research in various scientific discipliness physics, chemistry, and mathematics.","0","UNKNOWN","unknown_source"\n"25","惠灵顿学院","category","The Wellington College at Zhengzhou University focuses on international education and exchange programs.","0","UNKNOWnknown_source"\n"26","Belle II高能物理国际合作组","organization","Belle II is an international collaboration for high-energy physics research, with Zhengzhou University as one of its Chinese participants.","0","UNKNOWN","unknown_source"\n"27","主校区南校园","location","主校区南校园位于郑州市大学北路75号,是郑州大学的另一个校区。","0","UNKNOWN","unknown_source"\n"28","Ministry of Education","organization","The Ministry of Education is nsible for overseeing national education, including the recognition of Dalian University and Dalian University of Technology as key institutions in 1960 and 1980.<SEP>The Ministry of Education is the governmental body responsible for overseeing and supporting universities in China.","1","UNKNOWN","unknown_source"\n"29","郑州大学卓越工程师学院","category","The College of Excellent Engineers at Zhengzhou University focuses on engineerin and training.","0","UNKNOWN","unknown_source"\n"30","原郑州大学","organization","原郑州大学是郑州大学的一个组成部分,现已被合并。","0","UNKNOWN","unknown_source"\n"31","老文科楼","location","老文科楼是郑州大学主校区南校"\n"32","《老文科楼》","location","《老文科楼》是郑州大学主校区南校园内的一处具有历史价值的建筑。","0","UNKNOWN","unknown_source"\n"33","郑州大学体育学院","category","The College of Sports at Zhengzhou University focuses on research in sports sciences and physical education.","0","UNKNOWN","unknown_source"\n"34","学术资源","category","学术资源包括图书馆的纸质和电子图书、期刊、学位论文等资源。","1","UNKNOWN","unknown_source"\n"35","Stanization","The original name of the university, State-Owned Power Corporation, is the former managing authority of the university.","1","UNKNOWN","unknown_source"\n"36","郑州大学主校区","location","郑州大学主校区位于郑州要校区之一。","0","UNKNOWN","unknown_source"\n"37","临床技能中心","location","临床技能中心是郑州大学主校区东校园内的一处教学设施。","0","UNKNOWN","unknown_source"\n"38","卓越工程师学院","category","The College of Excell on engineering education and training.","1","UNKNOWN","unknown_source"\n"39","《基础、临床实验教学平台》","location","《基础、临床实验教学平台》是郑州大学主校区东校园内的一处实验教学场所。","0","UNKNOWN","unknown_sourc园的具体位置。","0","UNKNOWN","unknown_source"\n"41","《临床技能中心》","location","《临床技能中心》是郑州大学主校区东校园内的一处教学设施。","0","UNKNOWN","unknown_source"\n"42","河南医科大学","organization","Henan Medged with Zhengzhou University.<SEP>河南医科大学是郑州大学的前身之一。","0","UNKNOWN","unknown_source"\n"43","Double First-Class","category","Double First-Class is a national initiative to build world-class universities and disciplines in China.<SEP>The Double First-Class is a national university construction project under which North China Electric Power University is a key participant.","2","UNKNOWN","unknown_source"\n"44","Henan Medical University","organization","Henan Medical University is a medical university established in 1952, which is a predecessor of Zhengzhou University.<SEP>Henan Medical University was established in 1952 and is a predecessor of Zhengzhou University.<SEP>Henan Medical University, founded in 1952, is a predecessor of Zhengzhou University.","4","UNKNOWN","unknown_source"\n"45","《老行政楼》","location","《老行政楼》是郑州大学主校区南校园KNOWN","unknown_source"\n"46","教育学院","category","教育学院是郑州大学的一个下属学院,位于主校区。","0","UNKNOWN","unknown_source"\n"47","老行政楼","location","老行政楼是郑州大学主校区南校园内的一处具有历史价值的建筑。"The College of Medicine at Zhengzhou University focuses on research in medical and health sciences.","0","UNKNOWN","unknown_source"\n"49","《牡丹园》","location","《牡丹园》是郑州大学主校区北校园内的一个景点。","0","UN","原郑州工业大学","organization","原郑州工业大学是郑州大学的一个组成部分,现已被合并。","0","UNKNOWN","unknown_source"\n"51","馆藏资源","category","馆藏资源包括图书馆的纸质和电子图书、期刊、学位论文等资源。","0","UNKNOon (WIPO) Technology and Innovation Support Center (TISC)","category","North China Electric Power University is a founding member of the TISC initiative by WIPO.","0","UNKNOWN","unknown_source"\n"53","基础、临床实验教学tion","基础、临床实验教学平台是郑州大学主校区东校园内的一处实验教学场所。","0","UNKNOWN","unknown_source"\n"54","郑州大学图书馆","organization","郑州大学图书馆由原郑州大学图书馆、原郑州工业大学图书馆、原河南医科大学图书校级机构。<SEP>郑州大学图书馆由原郑州大学图书馆、原郑州工业大学图书馆和原河南医科大学图书馆合并组建而成,拥有丰富的馆藏资源和多个分馆。","1","UNKNOWN","unknown_source"\n"55","郑州大学管理学院","category","The School of ocuses on research in business and management disciplines.","0","UNKNOWN","unknown_source"\n"56","牡丹园","location","牡丹园是郑州大学主校区北校园内的一个景点。","0","UNKNOWN","unknown_source"\n"57","原河南医科大学","or分,现已被合并。","0","UNKNOWN","unknown_source"\n"58","商学院","category","商学院是郑州大学的一个下属学院,位于主校区。","0","UNKNOWN","unknown_source"\n"59","郭沫若","person","Guo Moruo is a former president of the Ch the name of Zhengzhou University.","0","UNKNOWN","unknown_source"\n\n ```\n -----Relationships-----\n ```csv\n
"id","source","target","description","keywords","weight","rank","created_at","file_path"\n"0","大连理工大学","教育部","教育部主管大连理工大学。<SEP>教育部于1960年10月将大连工学院确定为直属全国重点大学,并在1980年6月确定大连工学院为最早设立少数民族班、实行定向定点招生的重点院校之一。<SEP>教育部在1980年确定大连理工versity recognition, policy impact<SEP>主管,教育<SEP>管理,教育机构","43.0","54","UNKNOWN","unknown_source"\n"1","教育部","郑州大学","The Ministry of Education has recognized Zhengzhou University as a model university inent recognition, university recognition","10.0","32","UNKNOWN","unknown_source"\n"2","化学拔尖学生培养基地","郑州大学","Zhengzhou University has established a base for nurturing outstanding chemistry students.","base estudent cultivation","10.0","27","UNKNOWN","unknown_source"\n"3","国家超级计算郑州中心","郑州大学","Zhengzhou University has established the National Supercomputing Center in Zhengzhou.","center establishment, high-perfong","10.0","27","UNKNOWN","unknown_source"\n"4","教育部重点实验室、工程研究中心、国际合作联合实验室和医药基础研究创新中心","郑州大学","Zhengzhou University has established key laboratories, engineering research centers,harmaceutical basic research innovation centers.","center establishment, research collaboration","10.0","27","UNKNOWN","unknown_source"\n"5","关键金属与先进靶材料教师团队","郑州大学","Zhengzhou University has a key metad advanced target material teacher team.","team establishment, research focus","9.0","27","UNKNOWN","unknown_source"\n"6","郑州大学","郑州大学附属传染病医院","Zhengzhou University has established an affiliated infectioutal.","hospital establishment, medical research","9.0","27","UNKNOWN","unknown_source"\n"7","卓越工程师学院","郑州大学","Zhengzhou University has established an excellent engineer college.","college establishment, engination","10.0","26","UNKNOWN","unknown_source"\n"8","郑州大学","醇生产的关键技术及开发应用研究","醇生产的关键技术及开发应用研究在郑州大学取得了突破性成果,并获得了国家科技进步奖。","科研成果,学术奖励","9.0","26","UNKNOWNorates with APUS Group for research and development.","collaboration, innovation","8.0","26","UNKNOWN","unknown_source"\n"10","《郑州大学学报(哲学与社会科学版)》","郑州大学","《郑州大学学报(哲学与社会科学版)》是郑州.0","26","UNKNOWN","unknown_source"\n"11","中国气象科学研究院","郑州大学","Zhengzhou University partners with the China Meteorological Science and Technology Institute on research projects.","research collaboration, met0","26","UNKNOWN","unknown_source"\n"12","中国科学院计算技术研究所","郑州大学","Zhengzhou University collaborates with the Institute of Computing Technology of the Chinese Academy of Sciences on smart computing technoloesearch collaboration, smart computing","7.0","26","UNKNOWN","unknown_source"\n"13","郑州大学","黄河水利科学研究院","Zhengzhou University collaborates with the Yellow River Water Science and Technology Institute on watenagement and ecological studies.","water resource management, ecology","7.0","26","UNKNOWN","unknown_source"\n"14","中国铁人三项运动协会","郑州大学","Zhengzhou University collaborates with the Chinese Triathlon Associaton sports and athlete development.","sports collaboration, triathlon","7.0","26","UNKNOWN","unknown_source"\n"15","中国工程院","郑州大学","Zhengzhou University collaborates with the Chinese Academy of Engineering on research and technological advancements.","research collaboration, engineering","7.0","26","UNKNOWN","unknown_source"\n"16","战略支援部队信息工程大学","郑州大学","Zhengzhou University collaborates with the Strategic Supporion Engineering University on information technology and cybersecurity research.","cybersecurity, research collaboration","7.0","26","UNKNOWN","unknown_source"\n"17","中电科第二十七研究所","郑州大学","Zhengzhou Universis with the China Electronics Technology Group Corporation No. 27 Research Institute on information technology and cybersecurity research.","cybersecurity, research collaboration","7.0","26","UNKNOWN","unknown_source"\n"18","人民星云—郑州大学生态环境研究院","郑州大学","Zhengzhou University collaborates with Renmin Star Cloud to focus on environmental science research and development.","environmental science, research collaboration","7.unknown_source"\n"19","三门峡市人民政府","郑州大学","Zhengzhou University collaborates with the Sanmenxia Municipal Government on key metal research and development.","collaboration, research","7.0","26","UNKNOWN","unknown_source"\n"20","教育部办公厅","郑州大学","Zhengzhou University collaborates with the Ministry of Education Office on educational policies and initiatives.","policy collaboration, education","7.0","26","UNKNOWN","unkn"\n"21","郑州大学","非开挖工程技术和装备","非开挖工程技术和装备的研究和应用在郑州大学得到了支持和发展。","技术研发,学术支持","7.0","26","UNKNOWN","unknown_source"\n"22","《郑州大学学报(医学版)》","郑州大学","《郑州大学ce"\n"23","《郑州大学学报(理学版)》","郑州大学","《郑州大学学报(理学版)》是郑州大学主办的理学学术期刊。","理学学术研究,学术期刊","7.0","26","UNKNOWN","unknown_source"\n"24","郑州大学","郑州大学图书馆","郑州大学图书馆ce"\n"25","学术资源","郑州大学","学术资源为郑州大学的学术研究和教学提供了支持。","学术资源,学术支持","6.0","26","UNKNOWN","unknown_source"\n"26","Double First-Class","North China Electric Power University","The Double Fstruction project under which North China Electric Power University is a key participant.","key participant, national project","14.0","15","UNKNOWN","unknown_source"\n"27","211 Project","North China Electric Power University","The 211 Project is a national university development project under which North China Electric Power University is a key participant.","key participant, national project","14.0","15","UNKNOWN","unknown_source"\n"28","Beijing Power Economics College","North China Electric Power University","Beijing Power Economics College merged with North China Electric Power University in 1995 to form the current university.","merger, consolidation","20.0","14","UNKNOWN","unknown_source"\n"29","Beijing","North China Electric Power University","The university was originally founded in Beijing and part of its current campus is in Beijing.","historical connection, main campus","18.0","14","UNKNOWN","unknown_source"\n"30","Baoding","North China Electric Power University","Baoding is the current main campus of the university, where the university headquarters is located.","campus location, administrative center","18.0","14","UNKNOWN","unknown_source"\n"31","Global Energy Internet University Alliance","North China Electric Power University","North China Electric Power University is a founding member of the Global Energy Internet University Alliance.","founding member, member of alliance","18.0","14","UNKNOWN","unknown_source"\n"32","North China Electric Power University","State Grid Corporation of China","State Grid Corporation of China is one of the 12 large-scale power companies that co-build the university with the Ministry of Education.","co-construction, corporate support","16.0","14","UNKNOWN","unknown_source"\n"33","China Association for Science and Technology","North China Electric Power University","China Association for Science and Technology is a member of the Global Energy Internet University Alliance, of which North China Electric Power University is a founding member.","founding member, member of alliance","16.0","14","UNKNOWN","unknown_source"\n"34","North China Electric Power University","World Intellectual Property Organization (WIPO)","North China Electric Power University is a founding member of the TISC initiative by WIPO.","founding member, TISC initiative","16.0","14","UNKNOWN","unknown_source"\n"35","Harbin, Hebei Province","North China Electric Power University","The university was once located in Harbin, Hebei Province before moving to Baoding.","historical connection, former location","14.0","14","UNKNOWN","unknown_source"\n"36","North China Electric Power University","State-Owned Power Corporation","State-Owned Power Corporation is the former managing authority of the university.","historical connection, former administrative authority","14.0","14","UNKNOWN","unknown_source"\n"37","985 Project","North China Electric Power University","The 985 Project is a national university construction project under which North China Electric Power University is a key participant.","key participant, national project","14.0","14","UNKNOWN","unknown_source"\n"38","North China Electric Power University","Talent Training Program for Excellent Engineers","North China Electric Power University is a pilot school for the Talent Training Program for Excellent Engineers.","pilot school, talent training","14.0","14","UNKNOWN","unknown_source"\n"39","教育部","苏州大学","Soochow University benefits from the Ministry of Education\'s initiativresources, contributing to its academic and research endeavors.","government support, higher education","16.0","13","UNKNOWN","unknown_source"\n"40","Henan Medical University","Zhengzhou University","Henan Medical University is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","13","UNKNOWN","unknown_source"\n"41","Zhengzhou University","Zhongshan University","Zhongshan University is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","12","UNKNOWN","unknown_source"\n"42","Central University of Henan","Zhengzhou University","Central University of Henan is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","12","UNKNOWN","unknown_source"\n"43","Henan University of Medicine","Zhengzhou University","Henan University of Medicine is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","11","UNKNOWN","unknown_source"\n"44","Double First-Class","Zhengzhou University","Zhengzhou University is a participant in the \'Double First-Class\' program.","academic excellence, national initiative","9.0","11","UNKNOWN","unknown_source"\n"45","211 Project","Zhengzhou University","Zhengzhou University is a participant in the \'211 Project\' program.","academic excellence, national initiative","9.0","11","UNKNOWN","unknown_source"\n"46","Zhengzhou Industrial University","Zhengzhou University","Zhengzhou Industrial University is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","10","UNKNOWN","unknown_source"\n"47","Henan Provincial Government","Zhengzhou University","Henan Provincial Government collaborates in the construction of Zhengzhou University.","government collaboration, educational support","8.0","10","UNKNOWN","unknown_source"\n"48","大连工学院","教育部","教育部在1960年确定大连工学院为直属全国重点大学。",us, recognition","8.0","10","UNKNOWN","unknown_source"\n"49","Ministry of Education","Zhengzhou University","The Ministry of Education supports and oversees Zhengzhou University.","government support, educational supervision","7.0","10","UNKNOWN","unknown_source"\n"50","化学拔尖学生培养基地","教育部","The Ministry of Education has established a base for nurturing outstanding chemistry students at Zhengzhou University.","government suptablishment","18.0","9","UNKNOWN","unknown_source"\n"51","教育部","教育部重点实验室、工程研究中心、国际合作联合实验室和医药基础研究创新中心","The Ministry of Education has established key laboratories, engineering reseatories, and pharmaceutical basic research innovation centers at Zhengzhou University.","government support, research collaboration","10.0","9","UNKNOWN","unknown_source"\n"52","教育部","第二批‘全国高校黄大年式教师团队’"Education has recognized the second batch of \'National Model Teacher Teams\' at Zhengzhou University.","government recognition, team establishment","19.0","8","UNKNOWN","unknown_source"\n"53","Henan Medical University","Zhongshan University","Zhongshan University is a predecessor of Henan Medical University, which is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","7","UNKNOWN","unknown_source"\n"54","Central University of Henan","Henan Medical University","Henan Medical University is a predecessor of Central University of Henan, which is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","7","UNKNOWN","unknown_source"\n"55","Henan Medical University","Henan University of Medicine","Henan Medical University is a predecessor of Henan University of Medicine, which is a predecessor institution of Zhengzhou University.","historical connection, academic lineage","10.0","6","UNKNOWN","unknown_source"\n"56","何季麟院士","关键金属与先进靶材料教师团队","He Jilin, a professor at Zhengzhs the key metal and advanced target material teacher team.","team leadership, research focus","10.0","3","UNKNOWN","unknown_source"\n\n ```\n
-----Sources-----\n
```csv\n
"id","content"\n"0",".0基地(2021年度通知》,郑州大学化学拔尖学生培养基地入选,这是学校首个教育部基础学科拔尖学生培养计划2.0基地。 [302]2021年12月30日,教育部公布了第二批“全国高校黄大年式教师团队”。其中,郑州大学材料科学与工程学院何季麟院士负责的关键金属与248]2023年12月11日,郑州大学附属传染病医院正式成立。 [304]\n2024年1月7日,郑州大学卓越工程师学院成立。 [305]2024年2月26日,郑州大学附属传染病医院、郑州大学传染病研究院揭牌仪式在郑州市第六人民医院举行。 [306]3月23日,河南式挂牌成立。 [308]5月,郑州大学东盟研究院、中国华侨华人(河南)研究中心揭牌成立。 [309]9月24日,郑州大学惠灵顿学院揭牌。 [320]11月,由郑州大学牵头成立的社会治理河南省协同创新中心成功举办《河南社会治理发展报告》发布会,这31个一级学科博士学位授权点、4个博士专业学位授权点,57个一级学科硕士学位授权点、37个硕士专业学位授权点,31个博士后科研流动站。\n截至2024年3月,学校拥有国家超级计算郑州中心、省部共建食管癌防治国家重点实验室、橡塑模具国家工变防控省部共建协同创新中心、国家领土主权与海洋权益协同创新中心(协同单位)、国家知识产权培训基地。牵头或参与建设中原关键金属实验室、天健先进生物医学实验室、黄河实验室、嵩山实验室、龙门实验室、龙湖现代免疫实验室、平原实验程研究中心、国际合作联合实验室和医药基础研究创新中心,以及8个部委级人文社会科学研究机构。拥有微纳成型技术、细胞与基因治疗、低碳环保材料智能设计、癌症化学预防、地下基础设施非开挖技术、电子材料与系统等6个国家级国际联合研究预防3个学科创新引智基地(国家“111计划”)。\n截至2024年3月,五年来,学校先后承担参与国家重点研发计划、国家科技重大专项等项目课题201项。2023年获批国家自然科学基金、国家社会科学基金项目共计480项。 [1]\n2020年度国家科学技术京东方高世代TFT线,完全可替代进口,解决了关键技术及制造“卡脖子”的问题。 [54]\n学校在1类新药阿兹夫定研发、金刚石光电材料研究、磁约束热核聚变基础理论研究、车用燃料乙醇生产的关键技术及开发应用研究、非开挖工程技术和装备、“一学,英文名ZHENGZHOU UNIVERSITY(简称郑大、ZZU),位于河南省郑州市, [117]是中华人民共和国教育部与河南省人民政府“部省合作共建高校”、 [5]国家“双一流”(一流大学)建设高校 [57-58]、“211工程”建设高校。学校先后被列入国家级卓越改革示范学校、全国创新创业典型经验高校。 [1]\n郑州大学医科教育源于1928年的河南中山大学,1952年河南医学院独立建院;原郑州大学创建于1956年,是新中国创办的第一所综合性大学;郑州工业大学成立于1963年,是原化工部直属的重点院校医科大学三校合并组建新郑州大学。 [1] [70]2012年9月,学校入选国家“中西部高校综合实力提升工程”; [259]2021年11月,学校入选教育部基础学科拔尖学生培养计划2.0基地。 [260]\n截至2024年3月,学校总占地面积6100余亩,有4个校区和1个个一级学科博士学位授权点、4个博士专业学位授权点,57个一级学科硕士学位授权点、37个硕士专业学位授权点,31个博士后科研流动站。\n学校前身\n河南医科大学\n郑州大学医科教育源于1928年的河南中山大学,开启了河南医学高等教育的先河949年6月,以中原大学医学院、教育专业五百余名学员和河南行政学院四百余名学员为基础,河南人民革命大学正式成立。7月,河南省人民政府接回滞留苏州的一千二百余名河南大学师生,并入河南人民革命大学。1950年3月恢复河南大学校名。学校年,中国效法前苏联进行全国高等学校院系调整,拟将一批沿海及东部地区高校迁往中西部,计划将山东大学迁到郑州组建新的河南大学,由于种种原因,山东大学未能落户郑州,而是搬回到济南,同年河南医学院独立建院。 [55] [281]1954年教育教部代表及兄弟院校领导共千余人,共庆郑州大学诞生。1956年2月,中央高等学校规划会议上正式确定,在郑州新建的大学命名为“郑州大学”,设数学、物理、化学3系,由中国科学院学部委员嵇文甫任主任,龚依群、王岳为副主任等成员组成筹建委中国国务院直接任命时任中国科学院学部委员的嵇文甫为郑州大学校长。8月,报教育部批准,郑州大学作为教育部直属大学,数理化三系向全国招生,并由时任中国科学院院长郭沫若先生题写了校名。 [281]\n郑州大学作为新中国创办的第一所综合为“省管”,主要面向省内招生,开始不断进行院系调整,当年就增设了政治、历史、中文3"\n"2","华北电力大学(North China Electric Power University),简称华电(NCEPU), [77]位于北京市,是教育部直属、由国家电网有限公司等12家特大设大学, [45]教育部首批卓越工程师教育培养计划实施学校, [103]全球能源互联网大学联盟首批成员。 [1]\n华北电力大学1958年创建于北京,原名北京电力学院,长期隶属国家电力部门管理。 [45]1969年,学校迁至河北邯郸,1970年迁到保定,公司划转教育部管理,成为教育部直属高校。2005年10月,学校校部变更为设在北京,分设保定校区,两地实行一体化管理。 [39]2017年,学校入选国家“双一流”建设高校行列。2022年,学校顺利通过首轮“双一流”建设评估并进入第二轮建设高校名6个学院(部) [48],开办53个本科专业;有7个博士后科研流动站,10个博士学位一级学科授权点和4个博士专业学位授权点,24个硕士学位一级学科授权点和17个硕士专业学位授权点;有教职工3100余人,在校本科生2.4万余人,研究生1.5万余人 Use markdown formatting with appropriate section headings\n- Please respond in the same language as the user\'s question.\n- Ensure the response maintains continuity with the conversation history.\n- List up to 5 most important reference sources at the end under "References" section. Clearly indicating whether each source is from Knowledge Graph (KG) or Vector Data (DC), and include the file path if available, in the following format: [KG/DC] Source content (File: file_path)\n- If you don\'t know the answer, just say so.\n- Do not make anything up. Do not include information not provided by the Knowledge Base.
<|im_end|>\n
<|im_start|>user\n
华北电力大生??<|im_end|>\n
<|im_start|>assistant\n-
insert
with open("../library/file1.txt", "r", encoding="utf-8") as f:
await rag.ainsert(f.read())ainsert():支持检查点的异步插入文档
async def ainsert():
await self.apipeline_enqueue_documents(input, ids, file_paths)
await self.apipeline_process_enqueue_documents(
split_by_character, split_by_character_only
)apipeline_enqueue_documents()
其中apipeline_enqueue_documents()如下:其主要功能是对文件的内容进行检查,然后初始化文件状态,并更新到系统队列中。
- 输入标准化:将输入的文档、ID和文件路径统一为列表形式,确保后续处理的一致性。
- 文件路径校验:如果提供了文件路径,确保其数量与文档数量一致;否则使用默认占位符unknown_source。
- ID验证或生成:如果提供了ID,验证其唯一性和数量匹配;否则清理文档内容并生成基于MD5哈希的唯一ID。
- 去重:移除重复的文档内容,保留唯一的文档及其对应的ID和文件路径。
- 生成初始状态:为每个唯一文档生成初始状态,包括摘要、长度、创建时间等信息。
- 过滤已处理文档:通过异步方法过滤掉已经处理过的文档,仅保留新文档。
- 存储状态:将新文档的状态异步存储到系统中,并记录日志。
async def apipeline_enqueue_documents():
# 输入标准化检查
if isinstance(input, str):
input = [input]
if isinstance(ids, str):
ids = [ids]
if isinstance(file_paths, str):
file_paths = [file_paths]
# 文件路径校验 If file_paths is provided, ensure it matches the number of documents
if file_paths is not None:
if isinstance(file_paths, str):
file_paths = [file_paths]
if len(file_paths) != len(input):
raise ValueError(
"Number of file paths must match the number of documents"
)
else:
# If no file paths provided, use placeholder
file_paths = ["unknown_source"] * len(input)
# 1. ID验证或生成: Validate ids if provided or generate MD5 hash IDs
if ids is not None:
# Check if the number of IDs matches the number of documents
if len(ids) != len(input):
raise ValueError("Number of IDs must match the number of documents")
# Check if IDs are unique
if len(ids) != len(set(ids)):
raise ValueError("IDs must be unique")
# Generate contents dict of IDs provided by user and documents
contents = {
id_: {"content": doc, "file_path": path}
for id_, doc, path in zip(ids, input, file_paths)
}
else:
# Clean input text and remove duplicates
cleaned_input = [
(clean_text(doc), path) for doc, path in zip(input, file_paths)
]
unique_content_with_paths = {}
# 将文件内容和文件名组成键值对 Keep track of unique content and their paths
for content, path in cleaned_input:
if content not in unique_content_with_paths:
unique_content_with_paths[content] = path
# 生成文件ID,并组成字典 Generate contents dict of MD5 hash IDs and documents with paths
contents = {
compute_mdhash_id(content, prefix="doc-"): {
"content": content,
"file_path": path,
}
for content, path in unique_content_with_paths.items()
}
# 2. 去重 Remove duplicate contents
unique_contents = {}
for id_, content_data in contents.items():
content = content_data["content"]
file_path = content_data["file_path"]
if content not in unique_contents:
unique_contents[content] = (id_, file_path)
# Reconstruct contents with unique content
contents = {
id_: {"content": content, "file_path": file_path}
for content, (id_, file_path) in unique_contents.items()
}
# 3.生成初始状态: Generate document initial status
new_docs: dict[str, Any] = { # 为每个文档生成初始状态,包括摘要、长度、创建时间等信息。
id_: {
"status": DocStatus.PENDING,
"content": content_data["content"],
"content_summary": get_content_summary(content_data["content"]), # 按summary_length进行截断
"content_length": len(content_data["content"]),
"created_at": datetime.now().isoformat(),
"updated_at": datetime.now().isoformat(),
"file_path": content_data[
"file_path"
], # Store file path in document status
}
for id_, content_data in contents.items()
}
# 4.过滤已处理状态 Filter out already processed documents
# Get docs ids
all_new_doc_ids = set(new_docs.keys())
# Exclude IDs of documents that are already in progress
unique_new_doc_ids = await self.doc_status.filter_keys(all_new_doc_ids)
# Log ignored document IDs
ignored_ids = [
doc_id for doc_id in unique_new_doc_ids if doc_id not in new_docs
]
if ignored_ids:
logger.warning(
f"Ignoring {len(ignored_ids)} document IDs not found in new_docs"
)
for doc_id in ignored_ids:
logger.warning(f"Ignored document ID: {doc_id}")
# Filter new_docs to only include documents with unique IDs
new_docs = {
doc_id: new_docs[doc_id]
for doc_id in unique_new_doc_ids
if doc_id in new_docs
}
if not new_docs:
logger.info("No new unique documents were found.")
return
# 5. 存储状态:将新文档的状态异步存储到系统中,并记录日志。 Store status document
await self.doc_status.upsert(new_docs)
logger.info(f"Stored {len(new_docs)} new unique documents")其中clean_text()如下:
def clean_text(text: str) -> str:
return text.strip().replace("\x00", "")其中content的内容如下:
其中upsert()如下:
async def upsert(self, data: dict[str, dict[str, Any]]) -> None:
if not data: # 检查输入数据是否为空,若为空则直接返回。
return
logger.info(f"Inserting {len(data)} records to {self.namespace}")
async with self._storage_lock: # 使用异步锁确保线程安全,更新内部数据存储。
self._data.update(data)
await set_all_update_flags(self.namespace) # 设置指定命名空间的所有更新标志为 True,通知所有工作线程重新加载数据。
await self.index_done_callback() # 索引更新其中set_all_update_flags()的主要目的是遍历 _update_flags[namespace] 中的所有标志位,将其值设置为 True,表示需要重新加载数据。
async def set_all_update_flags(namespace: str):
"""Set all update flag of namespace indicating all workers need to reload data from files"""
global _update_flags
if _update_flags is None: # 检查全局变量 _update_flags 是否为 None,若为 None,抛出异常提示未初始化。
raise ValueError("Try to create namespace before Shared-Data is initialized")
async with get_internal_lock():
if namespace not in _update_flags:
raise ValueError(f"Namespace {namespace} not found in update flags")
# Update flags for both modes
for i in range(len(_update_flags[namespace])):
_update_flags[namespace][i].value = True # 遍历 _update_flags[namespace] 中的所有标志位,将其值设置为 True,表示需要重新加载数据。
其中index_done_callback()首先处理数据,然后调用 write_json 方法将数据写入指定文件'./dickens/kv_store_doc_status.json',然后调用clear_all_update_flags()清除_update_flags[namespace] 中的所有标志位
async def index_done_callback(self) -> None:
async with self._storage_lock:
if self.storage_updated.value:
data_dict = ( # 将 _data 转换为字典格式,若 _data 具有 _getvalue 属性则调用该方法。
dict(self._data) if hasattr(self._data, "_getvalue") else self._data
)
logger.info(
f"Process {os.getpid()} doc status writting {len(data_dict)} records to {self.namespace}"
)
write_json(data_dict, self._file_name) # 写入'./dickens/kv_store_doc_status.json'
await clear_all_update_flags(self.namespace)其中clear_all_update_flags()的主要目的是遍历 _update_flags[namespace] 中的所有标志位,将其值设置为 False,表示不需要重新加载数据。
async def clear_all_update_flags(namespace: str):
"""Clear all update flag of namespace indicating all workers need to reload data from files"""
global _update_flags
if _update_flags is None:
raise ValueError("Try to create namespace before Shared-Data is initialized")
async with get_internal_lock():
if namespace not in _update_flags:
raise ValueError(f"Namespace {namespace} not found in update flags")
# Update flags for both modes
for i in range(len(_update_flags[namespace])):
_update_flags[namespace][i].value = False # # 遍历 _update_flags[namespace] 中的所有标志位,将其值设置为 False,表示不需要重新加载数据。
-
apipeline_process_enqueue_documents()
处理待处理文档,方法是将文档分割成块,对每个块进行实体和关系提取处理,并更新文档状态。
async def apipeline_process_enqueue_documents():
from lightrag.kg.shared_storage import (
get_namespace_data,
get_pipeline_status_lock,
)
# 初始化与锁检查:获取共享数据pipeline_status和锁pipeline_status_lock, Get pipeline status shared data and lock
pipeline_status = await get_namespace_data("pipeline_status")
pipeline_status_lock = get_pipeline_status_lock()
# 确保只有一个工作进程处理文档队列。如果已有进程在处理,则设置请求标志并返回。 Check if another process is already processing the queue
async with pipeline_status_lock:
# Ensure only one worker is processing documents
if not pipeline_status.get("busy", False): # 获取待处理、失败和异常终止的文档列表
processing_docs, failed_docs, pending_docs = await asyncio.gather(
self.doc_status.get_docs_by_status(DocStatus.PROCESSING),
self.doc_status.get_docs_by_status(DocStatus.FAILED),
self.doc_status.get_docs_by_status(DocStatus.PENDING),
)
# 将待处理、失败和异常终止的文档列表,合并为to_process_docs
to_process_docs: dict[str, DocProcessingStatus] = {}
to_process_docs.update(processing_docs)
to_process_docs.update(failed_docs)
to_process_docs.update(pending_docs)
if not to_process_docs:
logger.info("No documents to process")
return
pipeline_status.update(
{
"busy": True,
"job_name": "Default Job",
"job_start": datetime.now().isoformat(),
"docs": 0,
"batchs": 0,
"cur_batch": 0,
"request_pending": False, # Clear any previous request
"latest_message": "",
}
)
# Cleaning history_messages without breaking it as a shared list object
del pipeline_status["history_messages"][:]
else:
# Another process is busy, just set request flag and return
pipeline_status["request_pending"] = True
logger.info(
"Another process is already processing the document queue. Request queued."
)
return
try:
# 处理文档 Process documents until no more documents or requests
while True:
if not to_process_docs:
log_message = "All documents have been processed or are duplicates"
logger.info(log_message)
pipeline_status["latest_message"] = log_message
pipeline_status["history_messages"].append(log_message)
break
# 2. 分批 split docs into chunks, insert chunks, update doc status
docs_batches = [
list(to_process_docs.items())[i : i + self.max_parallel_insert]
for i in range(0, len(to_process_docs), self.max_parallel_insert)
]
log_message = f"Processing {len(to_process_docs)} document(s) in {len(docs_batches)} batches"
logger.info(log_message)
# 更新文档状态 Update pipeline status with current batch information
pipeline_status["docs"] = len(to_process_docs)
pipeline_status["batchs"] = len(docs_batches)
pipeline_status["latest_message"] = log_message
pipeline_status["history_messages"].append(log_message)
# 获取第一个文件 Get first document's file path and total count for job name
first_doc_id, first_doc = next(iter(to_process_docs.items()))
first_doc_path = first_doc.file_path
path_prefix = first_doc_path[:20] + (
"..." if len(first_doc_path) > 20 else ""
)
total_files = len(to_process_docs)
job_name = f"{path_prefix}[{total_files} files]"
pipeline_status["job_name"] = job_name
async def process_document():
"""用于处理单个文档并将其拆分为块(chunks),然后并行执行多个任务以更新状态和存储数据。"""
...
# 3. iterate over batches
total_batches = len(docs_batches)
for batch_idx, docs_batch in enumerate(docs_batches):
current_batch = batch_idx + 1
log_message = (
f"Start processing batch {current_batch} of {total_batches}."
)
logger.info(log_message)
pipeline_status["cur_batch"] = current_batch
pipeline_status["latest_message"] = log_message
pipeline_status["history_messages"].append(log_message)
# 异步处理每个文档
doc_tasks = []
for doc_id, status_doc in docs_batch:
doc_tasks.append(
process_document(
doc_id,
status_doc,
split_by_character,
split_by_character_only,
pipeline_status,
pipeline_status_lock,
)
)
# Process documents in one batch parallelly
await asyncio.gather(*doc_tasks)
await self._insert_done() # 触发多个存储实例的 index_done_callback 方法,并在完成后记录日志信息,同时更新管道状态
log_message = f"Completed batch {current_batch} of {total_batches}."
logger.info(log_message)
pipeline_status["latest_message"] = log_message
pipeline_status["history_messages"].append(log_message)
# Check if there's a pending request to process more documents (with lock)
has_pending_request = False
async with pipeline_status_lock:
has_pending_request = pipeline_status.get("request_pending", False)
if has_pending_request:
# Clear the request flag before checking for more documents
pipeline_status["request_pending"] = False
if not has_pending_request:
break
log_message = "Processing additional documents due to pending request"
logger.info(log_message)
pipeline_status["latest_message"] = log_message
pipeline_status["history_messages"].append(log_message)
# 再次检查文档状态 Check for pending documents again
processing_docs, failed_docs, pending_docs = await asyncio.gather(
self.doc_status.get_docs_by_status(DocStatus.PROCESSING),
self.doc_status.get_docs_by_status(DocStatus.FAILED),
self.doc_status.get_docs_by_status(DocStatus.PENDING),
)
to_process_docs = {}
to_process_docs.update(processing_docs)
to_process_docs.update(failed_docs)
to_process_docs.update(pending_docs)
finally:
log_message = "Document processing pipeline completed"
logger.info(log_message)
# Always reset busy status when done or if an exception occurs (with lock)
async with pipeline_status_lock:
pipeline_status["busy"] = False
pipeline_status["latest_message"] = log_message
pipeline_status["history_messages"].append(log_message)-
process_document()
process_document 是一个异步方法,用于处理单个文档,将其拆分为块(chunks),并并行执行多个任务以更新状态和存储数据。
- 获取文件路径:从 status_doc 中提取文件路径。
- 拆分文档:使用 chunking_func 方法将文档内容拆分为块,并为每个块生成唯一标识符。
- 并行任务:创建多个异步任务,分别处理文档状态、块存储、实体关系图、完整文档和文本块的存储。
- 更新状态:所有任务完成后,更新文档状态为已处理。
- 异常处理:如果发生异常,记录错误日志,取消未完成的任务,并将文档状态更新为失败。
async def process_document( # 用于处理单个文档并将其拆分为块(chunks),然后并行执行多个任务以更新状态和存储数据。
doc_id: str,
status_doc: DocProcessingStatus,
split_by_character: str | None,
split_by_character_only: bool,
pipeline_status: dict,
pipeline_status_lock: asyncio.Lock,
) -> None:
"""Process single document"""
try:
# 从文档状态对象中获取文件路径。Get file path from status document
file_path = getattr(status_doc, "file_path", "unknown_source") # 从文档状态对象中获取文件路径。
# 使用 chunking_func 方法将文档内容拆分为块 Generate chunks from document
chunks: dict[str, Any] = { # 使用 chunking_func 方法将文档内容拆分为块,并为每个块生成唯一的标识符。
compute_mdhash_id(dp["content"], prefix="chunk-"): {
**dp,
"full_doc_id": doc_id,
"file_path": file_path, # Add file path to each chunk
}
for dp in self.chunking_func(
status_doc.content,
split_by_character,
split_by_character_only,
self.chunk_overlap_token_size,
self.chunk_token_size,
self.tiktoken_model_name,
)
}
# 并行执行多个任务 Process document (text chunks and full docs) in parallel
# Create tasks with references for potential cancellation
doc_status_task = asyncio.create_task(
self.doc_status.upsert(
{
doc_id: {
"status": DocStatus.PROCESSING,
"chunks_count": len(chunks),
"content": status_doc.content,
"content_summary": status_doc.content_summary,
"content_length": status_doc.content_length,
"created_at": status_doc.created_at,
"updated_at": datetime.now().isoformat(),
"file_path": file_path,
}
}
)
) # 创建多个异步任务,分别处理文档状态、块存储、实体关系图、完整文档和文本块的存储。
chunks_vdb_task = asyncio.create_task(
self.chunks_vdb.upsert(chunks)
)
entity_relation_task = asyncio.create_task(
self._process_entity_relation_graph(
chunks, pipeline_status, pipeline_status_lock
)
)
full_docs_task = asyncio.create_task(
self.full_docs.upsert(
{doc_id: {"content": status_doc.content}}
)
)
text_chunks_task = asyncio.create_task(
self.text_chunks.upsert(chunks)
)
tasks = [
doc_status_task,
chunks_vdb_task,
entity_relation_task,
full_docs_task,
text_chunks_task,
]
await asyncio.gather(*tasks)
await self.doc_status.upsert( # 更新状态:所有任务完成后,更新文档状态为已处理。
{
doc_id: {
"status": DocStatus.PROCESSED,
"chunks_count": len(chunks),
"content": status_doc.content,
"content_summary": status_doc.content_summary,
"content_length": status_doc.content_length,
"created_at": status_doc.created_at,
"updated_at": datetime.now().isoformat(),
"file_path": file_path,
}
}
)
except Exception as e: # 如果发生异常,记录错误日志,取消未完成的任务,并将文档状态更新为失败。
# Log error and update pipeline status
error_msg = f"Failed to process document {doc_id}: {str(e)}"
logger.error(error_msg)
async with pipeline_status_lock:
pipeline_status["latest_message"] = error_msg
pipeline_status["history_messages"].append(error_msg)
# Cancel other tasks as they are no longer meaningful
for task in [
chunks_vdb_task,
entity_relation_task,
full_docs_task,
text_chunks_task,
]:
if not task.done():
task.cancel()
# Update document status to failed
await self.doc_status.upsert(
{
doc_id: {
"status": DocStatus.FAILED,
"error": str(e),
"content": status_doc.content,
"content_summary": status_doc.content_summary,
"content_length": status_doc.content_length,
"created_at": status_doc.created_at,
"updated_at": datetime.now().isoformat(),
"file_path": file_path,
}
}
)其中chunking_func(),即chunking_by_token_size()如下:这段代码的功能是根据指定的分词大小和重叠大小对输入字符串进行分割,返回一个包含分词数量、内容和顺序索引的字典列表。如果未设置 split_by_character,则直接按 tokens 长度和重叠大小分割整个字符串。
def chunking_by_token_size():
tokens = encode_string_by_tiktoken(content, model_name=tiktoken_model) # 将输入字符串编码为 tokens。
results: list[dict[str, Any]] = []
if split_by_character: # 如果设置了 split_by_character,则按指定字符分割字符串,并根据 split_by_character_only 的值决定是否进一步分割超长分块。
...
else: # 如果未设置 split_by_character,则直接按 tokens 长度和重叠大小分割整个字符串。
for index, start in enumerate(
range(0, len(tokens), max_token_size - overlap_token_size)
):
chunk_content = decode_tokens_by_tiktoken(
tokens[start : start + max_token_size], model_name=tiktoken_model
)
results.append(
{
"tokens": min(max_token_size, len(tokens) - start),
"content": chunk_content.strip(),
"chunk_order_index": index,
}
)
return results其中chunk如下
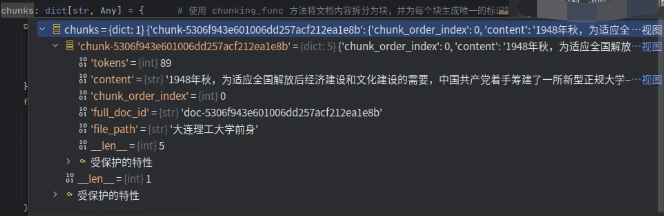
-
-
总结
LightRAG是一种基于图结构和双层检索机制的检索增强生成(Retrieval-Augmented Generation, RAG)系统,旨在通过优化检索效率和知识表示,提升自然语言处理任务的性能。
LightRAG的架构分为两个主要部分:基于图的索引阶段和基于图的检索阶段。在索引阶段,系统利用大型语言模型(LLM)从文本块中提取实体和关系,并构建知识图谱。该图谱通过去重和LLM增强分析,生成高效的索引键值对,便于后续检索。在检索阶段,LightRAG采用双层检索范式,包括低级检索(针对特定实体及其关系)和高级检索(涵盖更广泛的主题和概念),通过结合局部和全局关键词,提高检索的准确性和效率。
LightRAG的核心特点在于其轻量化设计和高效的检索机制。与传统的RAG系统相比,LightRAG专注于检索实体和关系,而非整个文本块,显著降低了检索开销。此外,LightRAG支持增量更新算法,能够快速适应新数据的加入,而无需重建整个知识图谱。这种设计使得LightRAG在资源受限的环境中表现出色,例如移动设备或实时交互系统。
总体而言,LightRAG通过优化检索机制和知识表示,为检索增强生成任务提供了一种高效、轻量化的解决方案,具有广泛的应用前景。
如果你喜欢我的内容,记得点赞、关注、收藏哦!你的支持是我不断进步的动力,也让我更有信心继续创作。点赞是对我努力的认可,关注是对我持续分享的信任,收藏则是方便你随时回顾。感谢有你,让我们一起成长!🎉💖📚

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









