






Patch-Wise Graph Contrastive Learning for Image Translation
图像翻译中的逐块图对比学习
Chanyong Jung,Gihyun Kwon,Jong Chul Ye 1, 2
Abstract 摘要 Patch-Wise Graph Contrastive Learning for Image Translation
Recently, patch-wise contrastive learning is drawing attention for the image translation by exploring the semantic correspondence between the input and output images. To further explore the patch-wise topology for high-level semantic understanding, here we exploit the graph neural network to capture the topology-aware features. Specifically, we construct the graph based on the patch-wise similarity from a pretrained encoder, whose adjacency matrix is shared to enhance the consistency of patch-wise relation between the input and the output. Then, we obtain the node feature from the graph neural network, and enhance the correspondence between the nodes by increasing mutual information using the contrastive loss. In order to capture the hierarchical semantic structure, we further propose the graph pooling. Experimental results demonstrate the state-of-art results for the image translation thanks to the semantic encoding by the constructed graphs.
近年来,块式对比学习通过探索输入图像和输出图像之间的语义对应关系,在图像翻译中引起了人们的关注。为了进一步探索用于高级语义理解的分片拓扑,在这里我们利用图神经网络来捕获拓扑感知特征。具体地说,我们从一个预训练的编码器,其邻接矩阵是共享的,以提高块之间的输入和输出的关系的一致性的补丁式的相似性的基础上构建的图。然后从图神经网络中提取节点特征,利用对比损失增加互信息,增强节点间的对应性。为了捕捉层次语义结构,我们进一步提出了图池。实验结果表明,由于所构造的图的语义编码的图像翻译的最先进的结果。
Introduction 介绍
Image-to-image translation task is a conditional image generation task in which the model converts the input image into target domain while preserving the content structure of the given input image. The seminar works of image translation models used paired training setting (Isola et al. 2017), or cycle-consistency training (Zhu et al. 2017) for content preservation. However, the models have disadvantages in that they require paired dataset or need complex training procedure with additional networks. To overcome the problems, later works introduced one-sided image translation by removing the cycle-consistency (Fu et al. 2019; Benaim and Wolf 2017).
图像到图像翻译任务是一种有条件的图像生成任务,其中模型将输入图像转换到目标域,同时保留给定输入图像的内容结构。图像翻译模型的研讨会工作使用配对训练设置(Isola et al. 2017)或循环一致性训练(Zhu et al. 2017)进行内容保存。然而,这些模型的缺点在于它们需要成对的数据集或需要使用额外的网络进行复杂的训练过程。为了克服这些问题,后来的研究通过去除周期一致性引入了单侧图像平移(Fu et al. 2019; Benaim and Wolf 2017)。
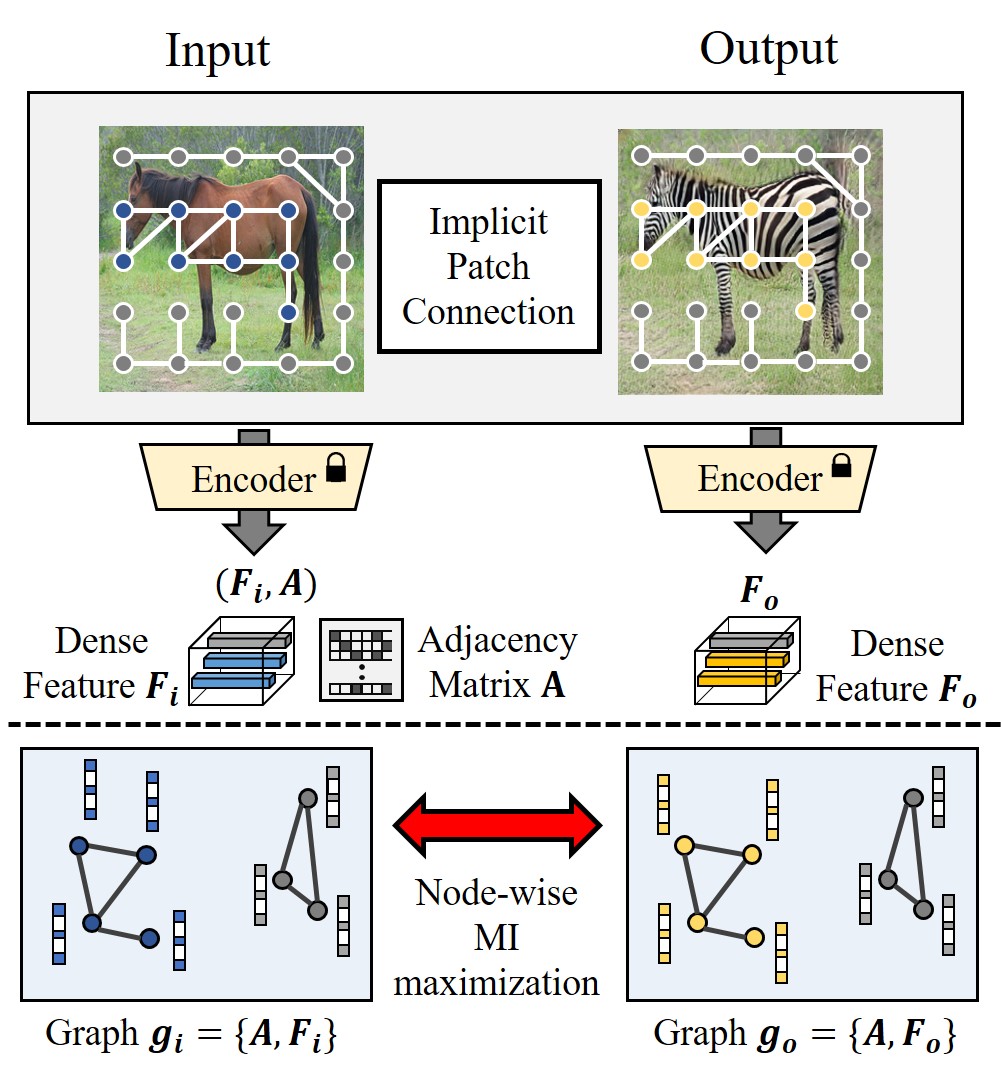
Figure 1: The semantic connectivity of input is extracted by the encoder, and shared to construct the graph network. We maximize the mutual information between the nodes.
图1:编码器提取输入的语义连接,并共享以构建图网络。我们最大化节点之间的互信息。
Recently, inspired by the success of contrastive learning strategies, Contrastive Unpaired Translation (CUT) (Park et al. 2020) is proposed to enhance the correspondence between the input and the output images by the patch-wise contrastive learning. The patch-wise contrastive learning is further improved by exploring patch-wise relation such as adversarial hard negative samples (Wang et al. 2021), patch-wise similarity map (Zheng, Cham, and Cai 2021), or consistency regularization combined with hard negative mining by patch-wise relation (Jung, Kwon, and Ye 2022). Although these methods show meaningful improvement in the performance, they still have a limitation in that the previous works focused only on the individual point-wise matching for each pair, which does not consider the topology with the neighbors (Zhou et al. 2021).
最近,受对比学习策略成功的启发,提出了对比非配对翻译(CUT)(Park et al. 2020),通过分块对比学习来增强输入和输出图像之间的对应关系。通过探索分块关系,如对抗性硬负样本(Wang et al. 2021),分块相似性图(Zheng,Cham和Cai 2021),或通过分块关系与硬负挖掘相结合的一致性正则化(Jung,Kwon和Ye 2022),进一步改进了分块对比学习。尽管这些方法在性能上显示出有意义的改进,但它们仍然存在局限性,因为以前的工作仅关注每个对的单独逐点匹配,而没有考虑与邻居的拓扑(Zhou等人,2021)。
To further explore the semantic relationship between the patches, this paper considers image translation tasks as topology-aware representation learning as shown in Fig. 1. Specifically, we propose a novel framework based on the patch-wise graph constrastive learning using the Graph Neural Network (GNN) which is commonly used to extract the feature considering the topological structure.
为了进一步探索补丁之间的语义关系,本文将图像翻译任务视为拓扑感知表示学习,如图1所示。具体来说,我们提出了一种新的框架,基于补丁明智的图形学习使用图神经网络(GNN),这是常用的提取考虑拓扑结构的功能。
Several existing works have utilized GNN to capture topology-aware features for various tasks. Hierarchical representation with graph partitioning is proposed for the unsupervised segmentation (Melas-Kyriazi et al. 2022; Wang et al. 2022), and topology-aware representations (Han et al. 2022) are extracted based on semantic connectivity between image regions. For knowledge distillation, claimed the holistic knowledge (Zhou et al. 2021) between the data points is claimed, verifying its effectiveness to encode the topological knowledge of the teacher model.
一些现有的作品已经利用GNN来捕获各种任务的拓扑感知功能。针对无监督分割提出了具有图划分的分层表示(Melas—Kyriazi et al. 2022;Wang et al. 2022),并且基于图像区域之间的语义连接性提取拓扑感知表示(Han et al. 2022)。对于知识蒸馏,声称数据点之间的整体知识(Zhou et al. 2021),验证了其对教师模型拓扑知识编码的有效性。
Despite the great performance in various vision tasks, none of researches have explored the topology-aware features considering the implicit patch-wise semantic connection for the image-to-image translation tasks. Accordingly, here we employ GNN to utilize the patch-wise connection of input image as a prior knowledge for patch-wise contrastive learning. Specifically, we use a pre-trained network to extract the patch-wise features for the input and the output images. Then, we obtain the adjacency matrix calculated by the semantic relation between the patches of the input image, and share it for output image graph. We construct two graphs for the input and the output by the adjacency matrix and the patch features, and obtain the node features by the graph convolution. By maximize the mutual information (MI) between the nodes of input graph and output graph through the contrastive loss, we can enhance the correspondence of patches for the image translation task. Furthermore, to extract the semantic correspondence in a hierarchical manner, we propose to use the graph pooling technique that resembles the attention mechanism.
尽管在各种视觉任务中表现出色,但还没有研究探索考虑图像到图像翻译任务的隐式块式语义连接的拓扑感知特征。因此,在这里,我们采用GNN利用输入图像的分块连接作为分块对比学习的先验知识。具体来说,我们使用一个预先训练好的网络来提取输入和输出图像的分块特征。然后,我们得到的邻接矩阵计算的输入图像的补丁之间的语义关系,并共享它的输出图像图。通过邻接矩阵和分片特征构造输入和输出的两个图,并通过图卷积获得节点特征。通过对比度损失最大化输入图和输出图节点之间的互信息,可以增强图像翻译任务中块的对应性。 此外,为了以分层方式提取语义对应,我们建议使用类似于注意力机制的图池技术。
Our contributions can be summarized as follows:
我们的贡献可归纳如下:
- •
We propose a GNN-based framework to capture topology-aware semantic representation by exploiting the patch-wise consistency between the input and translated output images.
·我们提出了一个基于GNN的框架,通过利用输入和翻译输出图像之间的分片一致性来捕获拓扑感知的语义表示。 - •
We suggest a method to share the adjacency matrix in order to utilize the patch-wise connection of input image as a prior knowledge for the contrastive learning.
·我们提出了一种共享邻接矩阵的方法,以便利用输入图像的分块连接作为对比学习的先验知识。 - •
To further exploit the hierarchical semantic relationship, we propose to use the graph pooling which provides a focused view for the graph.
·为了进一步利用分层语义关系,我们建议使用图池,它为图提供了一个集中的视图。 - •
Experimental results in five different datasets demonstrates the state-of-the-art performance by producing semantically meaningful graphs.
·在五个不同数据集上的实验结果通过生成语义上有意义的图形来展示最先进的性能。
Related Works 相关作品
Patch-Wise Contrastive Learning for Images
图像的分块对比学习
In patch-level view, the image has diverse local semantics. The relational knowledge between the patches embodies the correlation between each region, and is utilized for various image generation tasks.
在块级视图中,图像具有多样的局部语义。块之间的关系知识体现了每个区域之间的相关性,并用于各种图像生成任务。
For example, patch-wise contrastive relation (Park et al. 2020; Wang et al. 2021) is utilized for the image translation. Similarly, patch similarity map obtained from pretrained encoder (Zheng, Cham, and Cai 2021) is suggested. Recently, patch-level self-correlation map (Zhan et al. 2022a), query selection module based on patch-wise similarity (Hu et al. 2022), optimal transport plan by patch-wise cost matrix (Zhan et al. 2022b) are suggested. Also, semantic relation consistency (Jung, Kwon, and Ye 2022) is proposed for the image translation tasks. Especially, for style transfer, patch-level relation extracted by vision transformer is recently proposed (Tumanyan et al. 2022; Bar-Tal et al. 2022). The methods utilized the relation between image tokens to preserve the regional correspondence. Recently, the consistency of the patch-wise semantic relation between the input and the output images was exploited to further improve the correspondence between the input and the output image (Jung, Kwon, and Ye 2022). For style transfer, the consistency of patch-level relation extracted by vision transformer was also studied (Tumanyan et al. 2022; Bar-Tal et al. 2022).
例如,分片对比关系(Park et al. 2020;Wang et al. 2021)用于图像平移。类似地,建议从预训练的编码器(Zheng,Cham和Cai 2021)获得补丁相似性图。最近,提出了块级自相关映射(Zhan et al.2022a)、基于块级相似性的查询选择模块(Hu et al.2022)、基于块级代价矩阵的最优运输计划(Zhan et al.2022b)。此外,语义关系一致性(Jung,Kwon和Ye 2022)被提出用于图像翻译任务。特别是,对于风格转移,最近提出了通过视觉Transformer提取的补丁级关系(Tumanyan et al. 2022;Bar—Tal et al. 2022)。该方法利用图像标记之间的关系来保持区域对应性。 最近,利用输入和输出图像之间的分块语义关系的一致性来进一步提高输入和输出图像之间的对应性(Jung,Kwon和Ye 2022)。对于风格转移,还研究了视觉Transformer提取的斑块级关系的一致性(Tumanyan et al. 2022; Bar-Tal et al. 2022)。
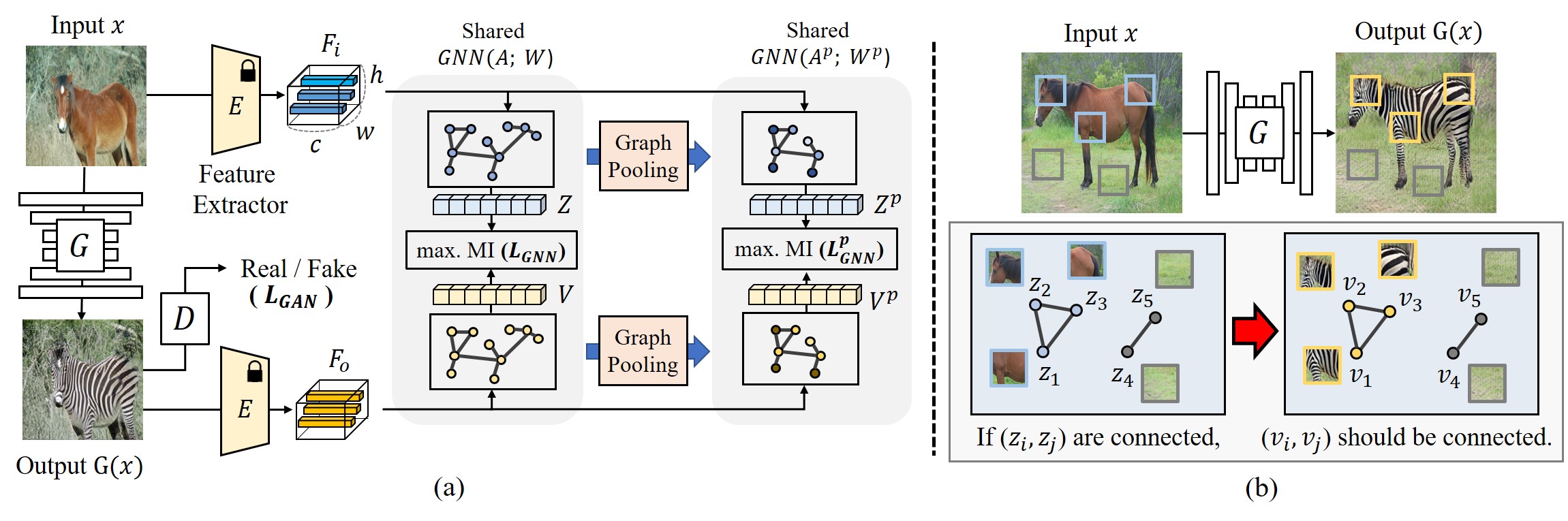
Figure 2:(a) Overall framework of the proposed method. We impose patch-wise regularization by the GNN constructed by the encoder 𝐸. We extract the node feature 𝑍,𝑉 and maximize 𝐼(𝑍;𝑉). Pooled graphs are utilized to focus on task-relevant nodes. (b) The motivation of the proposed approach to use patch-wise connection of input image as the prior knowledge.
图2:(a)拟议方法的总体框架。我们通过由编码器 𝐸 构造的GNN来施加分片正则化。我们提取节点特征 𝑍,𝑉 并最大化 𝐼(𝑍;𝑉) 。池化图用于关注与任务相关的节点。(b)所提出的方法的动机,使用分块连接的输入图像作为先验知识。
Graph Neural Network 图神经网络
Graph neural network(GNN) learns the representation considering the connectivity of a graph-structured data (Kipf and Welling 2017; Du et al. 2017). Each node feature models the individual data and its relation to the other data points, aggregating the information from the neighbor nodes.
图神经网络(GNN)考虑图结构数据的连接性来学习表示(Kipf和Welling 2017;Du et al. 2017)。每个节点特征对单个数据及其与其他数据点的关系进行建模,从而聚合来自邻居节点的信息。
Thanks to the successes of the GNN to capture the topology-aware features (Xie, Xu, and Ji 2022; Wu et al. 2022; Yuan and Ji 2020), the GNN is actively used in various computer vision tasks. For example, the GNN is utilized to capture the local features to find image correspondence (Sarlin et al. 2020), and multi-modal feature for action segmentation in videos (Zhang, Tsai, and Tsai 2022). Especially, knowledge distillation method through GNN (Zhou et al. 2021; Lassance et al. 2020) is proposed, which is claimed better than conventional contrastive loss, by transferring an additional knowledge on the instance-wise relations.
由于GNN成功捕获了拓扑感知特征(Xie,Xu和Ji 2022;Wu et al. 2022;Yuan和Ji 2020),GNN被积极用于各种计算机视觉任务。例如,GNN用于捕获局部特征以找到图像对应关系(Sarlin et al. 2020),以及用于视频中动作分割的多模态特征(Zhang,Tsai和Tsai 2022)。特别是,通过GNN(Zhou et al. 2021;Lassance et al. 2020)提出了知识蒸馏方法,该方法通过转移实例关系上的额外知识,比传统的对比损失更好。
Recently, the graph constructed by the patch-wise relation was suggested to capture the visual features. The graph partitioning methods are employed for the unsupervised segmentation (Melas-Kyriazi et al. 2022; Wang et al. 2022), where the graph is obtained by the token-wise similarity from the vision transformer. Vision GNN (Han et al. 2022) is introduced, which have GCN-based architecture to extract the topology-aware representation, and showed its superior performance to the widely used models such as the CNN and the vision transformers.
最近,提出了由分片关系构造的图来捕获视觉特征。图分割方法用于无监督分割(Melas-Kyriazi et al. 2022; Wang et al. 2022),其中图是通过视觉Transformer的标记相似性获得的。介绍了Vision GNN(Han et al. 2022),它具有基于GCN的架构来提取拓扑感知表示,并显示出其上级性能优于广泛使用的模型,如CNN和视觉变换器。
Method 方法
Inspired by the previous works, we are interested in exploiting patch-wise relation that represents semantic topology of the image. In particular, we focus on the topology-aware features using graph formed by the semantic relation of patches, and explore how the features improve the task performance.
受以前的作品的启发,我们有兴趣利用补丁明智的关系,代表语义拓扑的图像。特别是,我们专注于拓扑感知的功能,使用由补丁的语义关系形成的图,并探讨如何提高任务性能的功能。
Specifically, our method is motivated by the consistency of the patch-wise semantic connection of the input and the output images, as shown in Fig. 2(b). If the patch features (𝑧𝑖,𝑧𝑗) have semantic connection in the input image, then the patches (𝑣𝑖,𝑣𝑗) for the corresponding location of the output should also have the connection. From the motivation, we present a method that utilizes the topology of patch-wise connection of the input image as a prior knowledge.
具体地说,我们的方法是由输入和输出图像的逐块语义连接的一致性激发的,如图2(b)所示。如果块特征( 𝑧𝑖,𝑧𝑗 )在输入图像中具有语义连接,则用于输出的对应位置的块( 𝑣𝑖,𝑣𝑗 )也应当具有该连接。从动机,我们提出了一种方法,利用拓扑结构的分块连接的输入图像作为先验知识。
More specifically, we capture the topology-aware patch features by a GNN, where the patch-wise connection is given by the shared adjacency matrix 𝐴. We then obtain the node features 𝑍={𝑧𝑖}𝑖=1𝑁 and 𝑉={𝑣𝑖}𝑖=1𝑁 and maximize node-wise MI by the contrastive loss. We also utilize the graph pooling, to maximize the MI within the task-relevant focused view of the graph. More details follows.
更具体地说,我们通过GNN捕获拓扑感知的补丁特征,其中补丁连接由共享邻接矩阵 𝐴 给出。然后,我们获得节点特征 𝑍={𝑧𝑖}𝑖=1𝑁 和 𝑉={𝑣𝑖}𝑖=1𝑁 ,并通过对比损失来最大化节点MI。我们还利用图池,以最大化图的任务相关聚焦视图内的MI。更多细节如下。
Graph Representation for Image Translation
图像平移的图表示
We first construct the graph for input image 𝑔𝑖={𝐴,𝐹𝑖}, where 𝐴 is adjacency matrix and 𝐹𝑖’s are node features that represent the image patches. Specifically, we randomly sample 𝑁 patch features 𝑓𝑛∈ℝ𝑐 from the dense feature 𝐹=𝐸(𝑥)∈ℝ𝑐×ℎ×𝑤 which is obtained from the intermediate layer of model 𝐸, where 𝑐,ℎ,𝑤 denote the number of color channel, height, and width, respectively. We set the 𝑁 features as the nodes for the graph 𝑔𝑖 (i.e. 𝐹𝑖=[𝑓1,…,𝑓𝑁]).
我们首先为输入图像 𝑔𝑖={𝐴,𝐹𝑖} 构建图,其中 𝐴 是邻接矩阵, 𝐹𝑖 是表示图像块的节点特征。具体地,我们从从模型 𝐸 的中间层获得的密集特征 𝐹=𝐸(𝑥)∈ℝ𝑐×ℎ×𝑤 中随机采样 𝑁 块特征 𝑓𝑛∈ℝ𝑐 ,其中 𝑐,ℎ,𝑤 分别表示颜色通道的数量、高度和宽度。我们将 𝑁 特征设置为图 𝑔𝑖 (即 𝐹𝑖=[𝑓1,…,𝑓𝑁] )的节点。
Then, we obtain the adjacency matrix 𝐴∈ℝ𝑁×𝑁 according to the cosine similarity of the patch features. We connect the patches if the similarity is above the predefined threshold 𝑡, and disconnect them in otherwise. Specifically, the connectivity 𝐴𝑖𝑗 for features 𝑓𝑖,𝑓𝑗 is computed by
然后,我们根据斑块特征的余弦相似度获得邻接矩阵 𝐴∈ℝ𝑁×𝑁 。如果相似性高于预定义的阈值 𝑡 ,则连接补丁,否则断开它们。具体地,特征 𝑓𝑖,𝑓𝑗 的连接性 𝐴𝑖𝑗 通过以下公式计算:
| 𝐴𝑖𝑗≔{1 if cos(𝑓𝑖,𝑓𝑗)≥𝑡0 if cos(𝑓𝑖,𝑓𝑗)<𝑡 | (1) |
We construct the output graph 𝑔𝑜={𝐴,𝐹𝑜} in similar way. We sample 𝑁 features 𝑓𝑛′∈ℝ𝑐 from the corresponding location of the dense feature 𝐹’=𝐸∘𝐺(𝑥)∈ℝ𝑐×ℎ×𝑤, and set as the nodes for the graph 𝑔𝑜 (i.e. 𝐹𝑜=[𝑓1′,…,𝑓𝑁′] ). To retain the topological correspondency between the patches, the output graph inherits the adjacency matrix 𝐴 from the input graph as shown in Fig. 3.
我们以类似的方式构造输出图 𝑔𝑜={𝐴,𝐹𝑜} 。我们从密集特征 𝐹’=𝐸∘𝐺(𝑥)∈ℝ𝑐×ℎ×𝑤 的对应位置采样 𝑁 特征 𝑓𝑛′∈ℝ𝑐 ,并设置为图 𝑔𝑜 (即 𝐹𝑜=[𝑓1′,…,𝑓𝑁′] )的节点。为了保持片之间的拓扑对应性,输出图从输入图继承邻接矩阵 𝐴 ,如图3所示。
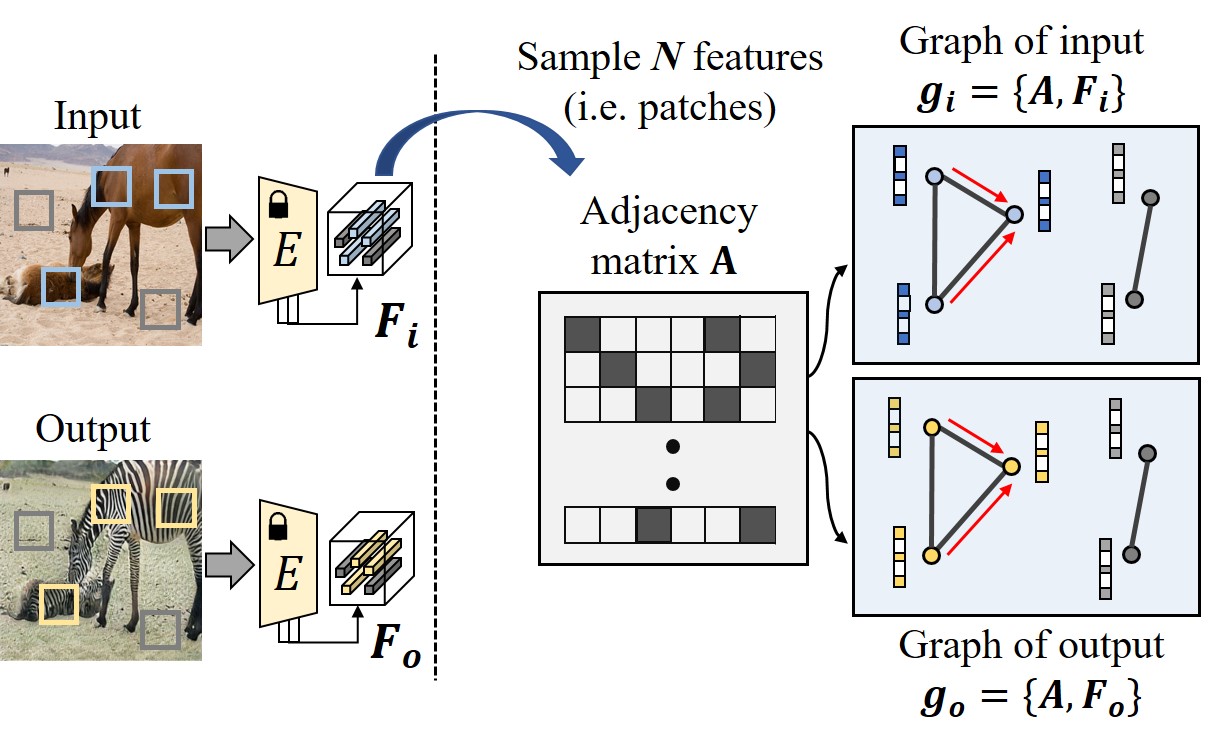
Figure 3:The construction of graphs 𝑔𝑜,𝑔𝑖 with shared adjacency matrix 𝐴. Each graph extracts 𝑙-hop features 𝑍,𝑉 from the given node 𝐹𝑖,𝐹𝑜.
图3:具有共享邻接矩阵 𝐴 的图 𝑔𝑜,𝑔𝑖 的构造。每个图从给定节点 𝐹𝑖,𝐹𝑜 提取 𝑙 -跳特征 𝑍,𝑉 。
Next, we obtain the graph representation 𝑍,𝑉 using Topology Adaptive Graph Convolution Network (Du et al. 2017) by the graph 𝑔𝑜,𝑔𝑖 as follows:
接下来,我们通过图 𝑔𝑜,𝑔𝑖 使用拓扑自适应图卷积网络(Du et al. 2017)获得图表示 𝑍,𝑉 ,如下所示:
| 𝑍=∑𝑙=0𝐿(𝐴¯)𝑙𝐹𝑖𝑊𝑙 | (2) | ||
| 𝑉=∑𝑙=0𝐿(𝐴¯)𝑙𝐹𝑜𝑊𝑙 | (3) |
where 𝐴¯ is the normalized adjacency matrix, and 𝑊𝑙 is the shared parameter for the 𝑙-th hop. We obtain 2-hop representation from the graph (i.e. 𝐿=2).
其中 𝐴¯ 是归一化邻接矩阵, 𝑊𝑙 是第#2跳的共享参数。我们从图中获得2跳表示(即 𝐿=2 )。
Finally, to enforce the topological correspondence between input 𝑋 and output 𝐺(𝑋) for a given generator 𝐺, we maximize the mutual information between the nodes 𝑍,𝑉 by the infoNCE loss (Oord, Li, and Vinyals 2018) as follows:
最后,为了强制给定生成器 𝐺 的输入 𝑋 和输出 𝐺(𝑋) 之间的拓扑对应关系,我们通过infoNCE损失最大化节点 𝑍,𝑉 之间的互信息(Oord,Li和Vinyals 2018)如下:
| 𝐿𝐺𝑁𝑁(𝑋,𝐺(𝑋))=−1𝑁∑𝑖=1𝑁[logexp(𝑧𝑖⊤𝑣𝑖)∑𝑗=1𝑁exp(𝑧𝑖⊤𝑣𝑗)] | (4) |
where 𝑧𝑖,𝑣𝑖 are the 𝑖-th node features from 𝑍 and 𝑉 from 𝑋 and 𝐺(𝑋), respectively.
其中 𝑧𝑖,𝑣𝑖 分别是来自 𝑋 和 𝐺(𝑋) 的 𝑍 和 𝑉 的第 𝑖 个节点特征。
When 𝐿=0, the proposed method shrinks to the conventional patch-wise contrastive learning with the projector network 𝑊0. In this perspective, our method utilizes the higher-ordered features by the graph aggregation (i.e. 𝐿>0), which generalizes the conventional contrastive learning.
当 𝐿=0 时,所提出的方法收缩到具有投影仪网络 𝑊0 的常规逐块对比学习。从这个角度来看,我们的方法通过图聚合(即 𝐿>0 )利用高阶特征,这概括了传统的对比学习。
Graph Pooling for Focused Attention
用于集中注意力的图形池
We pool the graph nodes to utilize task-relevant focused attention of the graph. In other words, we downsample the nodes by its relevancy to the task, and construct the graph with fewer nodes to focus on the task-relevant nodes.
我们将图节点池化以利用图的任务相关集中注意力。换句话说,我们根据节点与任务的相关性对节点进行下采样,并使用更少的节点来构建图,以关注与任务相关的节点。
Specifically, following the top-𝐾 pooling (Gao and Ji 2019), we select 𝐾 nodes from the 𝑁 nodes 𝑍=[𝑧1,…,𝑧𝑁] by the similarity score 𝑠𝑖=𝑝⊤𝑧𝑖, where 𝑝 is the learnable pooling vector. Accordingly, the adjacency matrix 𝐴𝑝∈ℝ𝐾×𝐾 for the pooled graph is constructed, by excluding the connections with non-selected nodes from the original matrix 𝐴. Then, the nodes are weighted by the score followed by sigmoid funcion 𝜎 as:
具体来说,在前 𝐾 池化(Gao和Ji 2019)之后,我们通过相似性得分 𝑠𝑖=𝑝⊤𝑧𝑖 从 𝑁 节点 𝑍=[𝑧1,…,𝑧𝑁] 中选择 𝐾 节点,其中 𝑝 是可学习的池化向量。因此,通过从原始矩阵 𝐴 中排除与未选择的节点的连接,构造用于池化图的邻接矩阵 𝐴𝑝∈ℝ𝐾×𝐾 。然后,节点通过分数加权,然后是sigmoid函数 𝜎 ,如下所示:
| 𝑍𝑝,𝑖𝑛 | =𝜎(𝑆)𝑍 | (5) | ||
| 𝑉𝑝,𝑖𝑛 | =𝜎(𝑆)𝑉 | (6) |
which becomes the input nodes for the pooled graphs. Then, the 𝐿-hop features are obtained as:
其成为池化图的输入节点。然后,第0#跳特征被获得为:
| 𝑍𝑝 | =∑𝑙=0𝐿(𝐴𝑝¯)𝑙𝑍𝑝,𝑖𝑛𝑊𝑝,𝑙 | (7) | ||
| 𝑉𝑝 | =∑𝑙=0𝐿(𝐴𝑝¯)𝑙𝑉𝑝,𝑖𝑛𝑊𝑝,𝑙 | (8) |
where 𝑊𝑝,𝑙 is the parameter of the pooled GNN. By constructing the pooled graphs 𝑔𝑖𝑝={𝐴𝑝,𝑍𝑝}, 𝑔𝑜𝑝={𝐴𝑝,𝑉𝑝} and obtaining the 𝑙-hop node feature, we also employ the infoNCE loss to maximize the MI between the nodes in the pooled graph as follows:
其中 𝑊𝑝,𝑙 是池化GNN的参数。通过构建池化图 𝑔𝑖𝑝={𝐴𝑝,𝑍𝑝} 、 𝑔𝑜𝑝={𝐴𝑝,𝑉𝑝} 并获得 𝑙 跳节点特征,我们还采用infoNCE损失来最大化池化图中的节点之间的MI,如下所示:
| 𝐿𝐺𝑁𝑁𝑝(𝑋,𝐺(𝑋))=−1𝐾∑𝑖=1𝐾[logexp(𝑧𝑝,𝑖⊤𝑣𝑝,𝑖)∑𝑗=1𝑁exp(𝑧𝑝,𝑖⊤𝑣𝑝,𝑗)] | (9) |
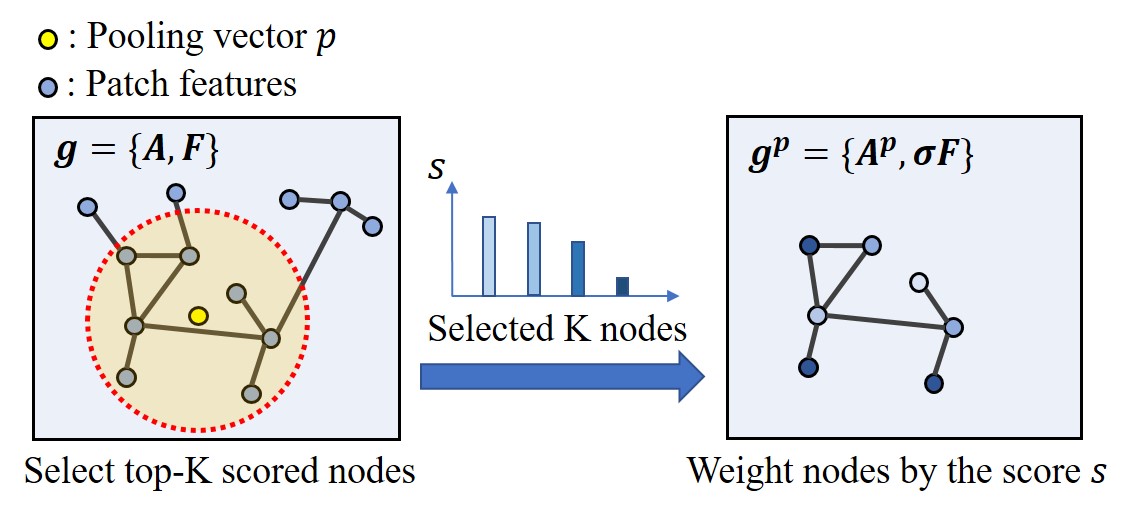
Figure 4:The top-𝐾 graph pooling (Gao and Ji 2019). The pooling vector 𝑝 provides the focused view of the graph for the given task. The final node feature is also weighted by 𝑝.
图4:顶部-0#图池(Gao和Ji 2019)。池化向量 𝑝 提供了给定任务的图形的聚焦视图。最终节点特征也由 𝑝 加权。
Here, it is remarkable how the graph pooling contributes to the improvement. As shown in Fig. 4, the vector 𝑝 learns to focus on the important nodes, which is determined by the task-relevancy of the nodes. It is analogous to the conventional attention methods (Woo et al. 2018; Park et al. 2018) shown in Fig. 5. Therefore, the graph pooling can be viewed as the node-wise attention, which imposes more regularization for the important nodes to enhance the correspondence for the image translation task.
在这里,值得注意的是图池如何有助于改进。如图4所示,向量 𝑝 学习关注重要节点,这由节点的任务相关性确定。它类似于图5所示的传统注意力方法(Woo et al. 2018; Park et al. 2018)。因此,图池化可以被视为节点级注意力,其对重要节点施加更多的正则化以增强图像翻译任务的对应性。
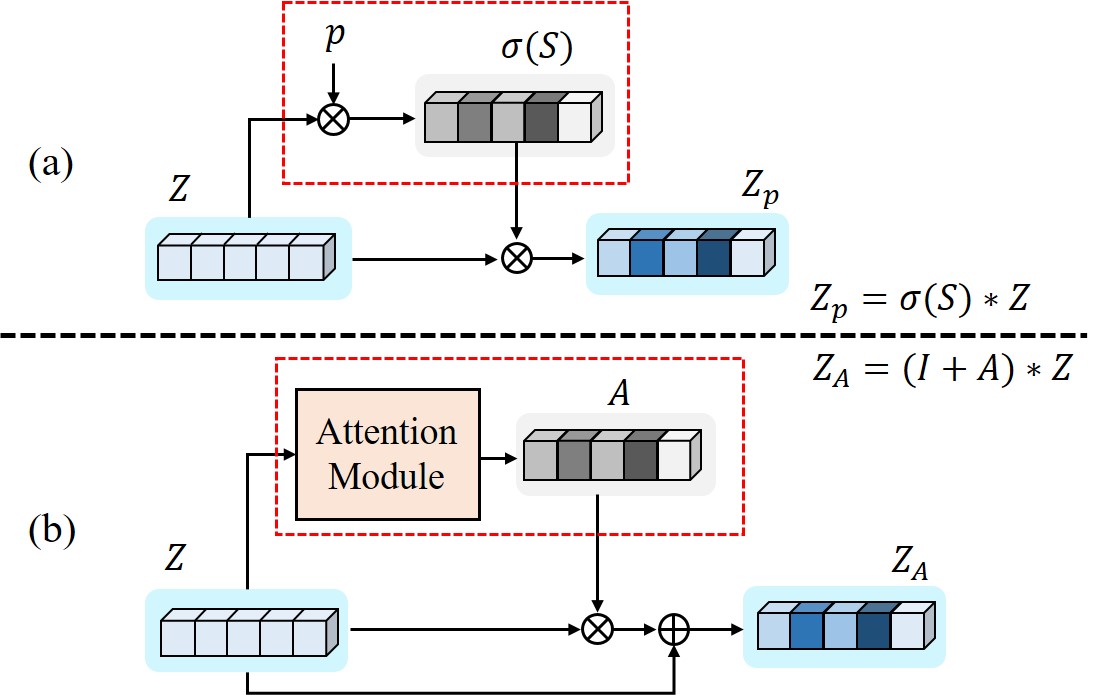
Figure 5:Top-𝐾 graph pooling allocates higher weights to the informative nodes, similarly to the attention mechanism. (a) Top-𝐾 graph pooling. (b) Attention method.
图5:Top- 𝐾 图池为信息节点分配更高的权重,类似于注意力机制。(a)Top- 𝐾 图池。(b)注意方法。
Overall Loss Function 重试 错误原因
Our method is one-sided image translation model without cycle-consistency, inspired by the related works based on the patch-wise contrastive learning (Jung, Kwon, and Ye 2022; Park et al. 2020; Wang et al. 2021; Zheng, Cham, and Cai 2021). Specifically, the overall loss is given as follows: 重试 错误原因
| 𝐿𝑡𝑜𝑡𝑎𝑙 | =𝐿𝐺𝐴𝑁(𝐺,𝐷)+𝜆𝑔∑𝑝=0𝑃𝐿𝐺𝑁𝑁𝑝(𝑋,𝐺(𝑋)) | (10) | ||
| +𝜆𝑔∑𝑝=0𝑃𝐿𝐺𝑁𝑁𝑝(𝑌,𝐺(𝑌)) |
with generator 𝐺 and discriminator 𝐷 shown in Fig. 2(a). 𝐿𝐺𝐴𝑁 is LSGAN loss (Mao et al. 2017) given as: 重试 错误原因
| 𝐿𝐺𝐴𝑁=𝐸𝑦∼𝑝𝑌[‖𝐷(𝑦)‖22]+𝐸𝑥∼𝑝𝑋[‖1−𝐷(𝐺(𝑥))‖22] | (11) |
with the distributions 𝑝𝑋,𝑝𝑌 for source and target domain. Additionally, we utilize the identity term 𝐿𝐺𝑁𝑁𝑝(𝑌,𝐺(𝑌)) to stabilize the training using the target domain images 𝑌, as suggested in (Park et al. 2020). 𝐿𝐺𝑁𝑁𝑝=0 refers the graph loss without the pooling. 重试 错误原因

Figure 6:Qualitative comparison with related methods. Our result shows enhanced input-output correspondence, compared to the previous methods.
图6:与相关方法的定性比较。我们的结果表明,增强的输入输出对应,与以前的方法相比。
Experimental Results 实验结果
Implementation Details 实现细节
We first verify our method for unpaired image translation task. We verify our method using the five datasets as follows: horse→zebra, Label→Cityscape, map→satellite, summer→winter, and apple→orange. All images are resized into 256×256 for training and testing. Then, we also present our method for single image translation with high resolution, following the previous work (Park et al. 2020).
我们首先验证我们的方法不成对的图像翻译任务。我们使用以下五个数据集验证我们的方法:马 → 斑马,标签 → 城市景观,地图 → 卫星,夏天 → 冬天,和苹果 → 橙子。所有图像都调整为256 × 256,用于训练和测试。然后,我们还提出了我们的方法,用于高分辨率的单个图像翻译,遵循以前的工作(Park等人。2020)。
For the graph construction, we randomly sampled 256 different patches from the pre-trained VGG16 (Simonyan and Zisserman 2014) network in both of input and output images. We extract the dense feature from the three different layers (relu3-1, relu4-1, relu4-3layer) inside of the network. For the graph operation, we set the number of GNN hops as 2, and pooling number as 1. For the graph pooling, we downsampled nodes by 1/4. In other words, we have 256 nodes in the initial graph, and 64 nodes for the pooled graph. More details are provided in the supplementary materials.
为了构建图形,我们从输入和输出图像中的预训练VGG16(Simonyan和Zisserman 2014)网络中随机抽取了256个不同的补丁。我们从网络内部的三个不同层(relu3—1,relu4—1,relu4—3层)中提取稠密特征。对于图操作,我们将GNN跳数设置为2,池数设置为1。对于图池,我们将节点的采样减少了1/4。换句话说,我们在初始图中有256个节点,在池图中有64个节点。补充材料中提供了更多细节。
Image-to-Image Translation
We compare our method with the two-sided domain translation models, CycleGAN (Zhu et al. 2017) and MUNIT (Huang et al. 2018). Also, we selected the one-sided image translation models, DistanceGAN (Benaim and Wolf 2017) and GcGAN (Fu et al. 2019). Especially, since our method is based on the patch-wise contrastive learning, we present the comparison with the recent contrastive learning based methods. We compare our method with CUT (Park et al. 2020) as baseline model, and the improved model of NEGCUT (Wang et al. 2021), SeSim (Zheng, Cham, and Cai 2021) and Hneg-SRC (Jung, Kwon, and Ye 2022).
我们将我们的方法与双边域翻译模型CycleGAN(Zhu et al. 2017)和MUNIT(Huang et al. 2018)进行了比较。此外,我们选择了单侧图像转换模型DistanceGAN(Benaim和Wolf 2017)和GcGAN(Fu等人2019)。特别是,由于我们的方法是基于块明智的对比学习,我们提出了与最近的对比学习为基础的方法的比较。我们将我们的方法与CUT(Park et al. 2020)作为基线模型,以及NEGCUT(Wang et al. 2021),SeSim(Zheng,Cham和Cai 2021)和Hong-SRC(Jung,Kwon和Ye 2022)的改进模型进行了比较。
Results 结果

Figure 7:Closer views of the output images. Our method enhances the spatial-specific information given in the input.
图7:输出图像的更近视图。我们的方法增强了输入中给定的空间特定信息。
The results in Fig. 6 verifies that the proposed method generates the images with better visual quality than the other methods, by enhancing the correspondence between the input and the output images. Compared to the other methods, our methods preserves the structural information of the input images, by using the patch-wise connection of the input as the prior knowledge.
图6中的结果验证了所提出的方法通过增强输入和输出图像之间的对应性来生成具有比其他方法更好的视觉质量的图像。与其他方法相比,我们的方法保留了输入图像的结构信息,通过使用块式连接的输入作为先验知识。
Moreover, we further compare our method with the HnegSRC which also utilizes the patch-wise semantic relation of the input. As shown in Fig. 7, our method enhances the spatial-specific information considering the patch-wise semantic neighborhood by the graph operation, compared with the HnegSRC which only imposed the consistency regularization for the patch-wise similarity. Specifically, our method in Fig. 7(a) outputs more realistic zebra by showing the spatial-specific patterns(e.g. dark colored mouth), which is not in the compared result. Also, our result in Fig. 7(b) shows the tree branches with the coherent shapes to the input, which are distorted in the compared method.
此外,我们进一步比较我们的方法与HSPINESS SRC,它也利用了补丁明智的语义关系的输入。如图7所示,与仅对分块相似性施加一致性正则化的HSPINESS SRC相比,我们的方法通过图操作考虑分块语义邻域来增强空间特定信息。具体地,我们在图7(a)中的方法通过示出空间特定的图案(例如,深色嘴)来输出更真实的斑马,这不在比较结果中。此外,我们在图7(B)中的结果显示了具有与输入相关的形状的树枝,这些树枝在比较方法中被扭曲。
The results in Table 1 also supports the outperformance of the proposed method. Specifically, in horse→zebra and Label→Cityscape datasets, we similar FID scores with the HnegSRC, but higher scores by KID. For summer→winter and apple→orange datasets, our model outperformed the others by large margins, which demonstrates the effectiveness of the proposed model.
表1中的结果也支持所提出的方法的优越性。具体来说,在马 → 斑马和标签 → 城市景观数据集,我们类似的FID分数与HALCOST SRC,但更高的分数KID。对于夏季 → 冬季和苹果 → 橙子数据集,我们的模型的性能大大优于其他人,这表明了所提出的模型的有效性。
| Method | Horse→Zebra 马 → 斑马 | Label→Cityscape 标签 → Cityscape | Map→Satellite 地图 → 卫星 | Summer→Winter 夏季 → 冬季 | Apple→Orange 苹果 → 橙子 | |||||
| FID↓ FID编号0# | KID↓ 儿童编号0# | FID↓ FID编号0# | KID↓ 儿童编号0# | FID↓ FID编号0# | KID↓ 儿童编号0# | FID↓ FID编号0# | KID↓ 儿童编号0# | FID↓ FID编号0# | KID↓ 儿童编号0# | |
| CycleGAN | 77.2 | 1.957 | 76.3 | 3.532 | 54.6 | 3.430 | 84.9 | 1.022 | 174.6 | 10.051 |
| MUNIT | 133.8 | 3.790 | 91.4 | 6.401 | 181.7 | 12.03 | 115.4 | 4.901 | 207.0 | 12.853 |
| DistanceGAN | 72.0 | 1.856 | 81.8 | 4.410 | 98.1 | 5.789 | 97.2 | 2.843 | 181.9 | 11.362 |
| GCGAN | 86.7 | 2.051 | 105.2 | 6.824 | 79.4 | 5.153 | 97.5 | 2.755 | 178.4 | 10.828 |
| \hdashlineCUT | 45.5 | 0.541 | 56.4 | 1.611 | 56.1 | 3.301 | 84.3 | 1.207 | 171.5 | 9.642 |
| NEGCUT | 39.6 | 0.477 | 48.5 | 1.432 | 51.0 | 2.338 | 82.7 | 1.352 | 154.1 | 7.876 |
| LSeSIM | 38.0 | 0.422 | 49.7 | 2.867 | 52.4 | 3.205 | 83.9 | 1.230 | 168.6 | 10.386 |
| HnegSRC | 34.4 | 0.438 | 46.4 | 0.662 | 49.2 | 2.531 | 81.8 | 1.181 | 158.3 | 8.434 |
| \hdashlineOurs \hdashlineOurs文件 | 34.5 | 0.271 | 46.8 | 0.605 | 45.9 | 2.112 | 75.8 | 0.845 | 139.1 | 7.134 |
Table 1:Quantitative results. Our model outperforms the baselines in both of FID and KID×100 metrics.
表1:定量结果。我们的模型在FID和KID × 100指标上都优于基线。

Figure 8:Qualitative comparison on single image translation.
图8:单个图像翻译的定性比较。
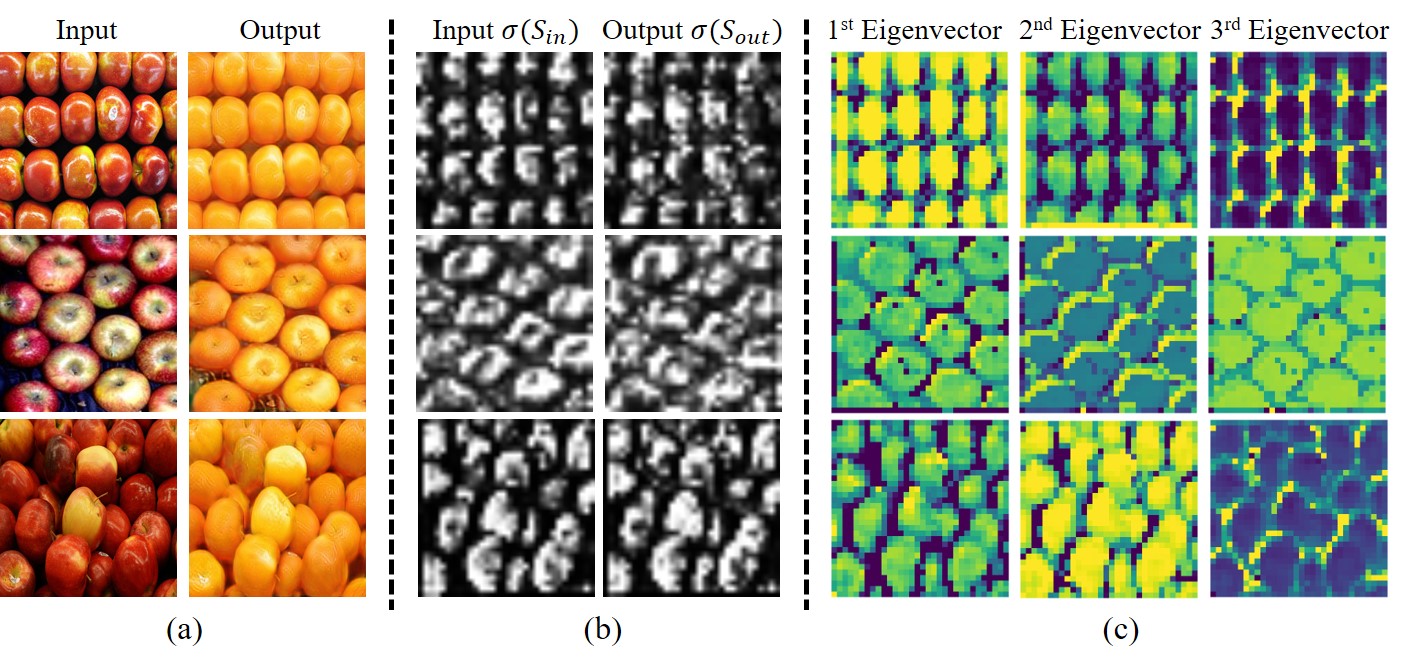
Figure 9:Analysis of the proposed method: (a) Input and the output images. (b) Visualization of 𝜎(𝑆𝑖𝑛),𝜎(𝑆𝑜𝑢𝑡). The vector 𝑝 allocates higher weights for the object parts which are task-relevant. Similar appearance refers the correspondence between input and output. (c) Eigenvectors of the Laplacian matrix of 𝐴, which are coherent to the semantics of the image. 重试 错误原因
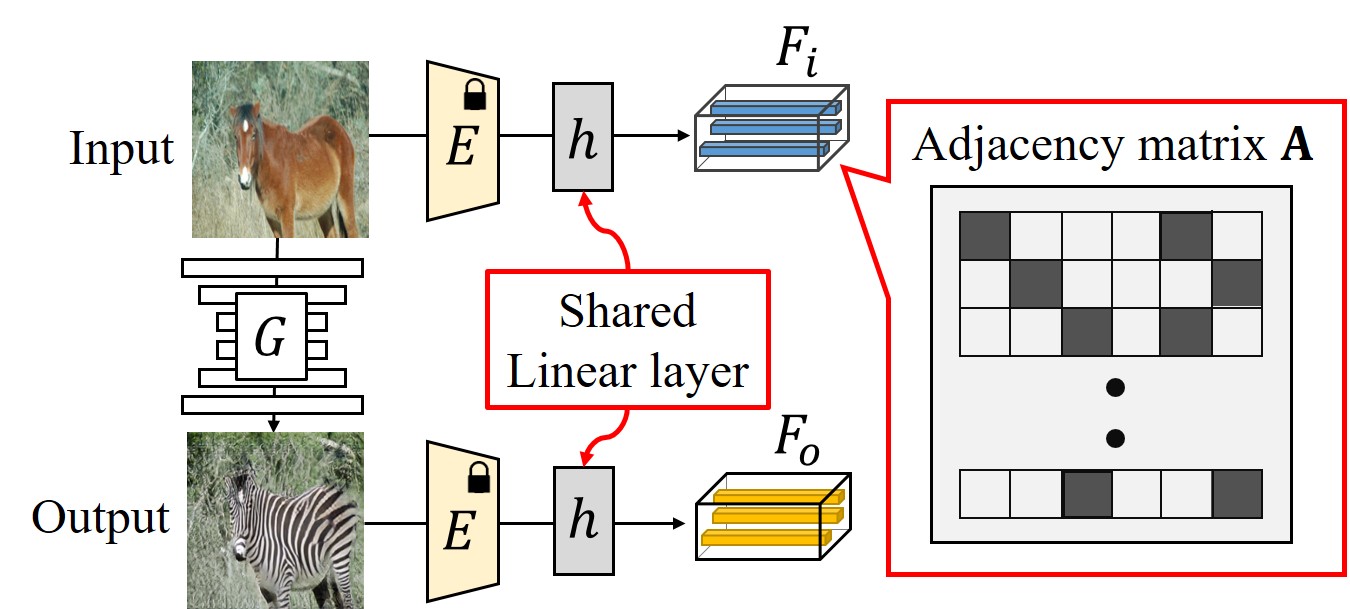
Figure 10:The adjacency matrix 𝐴 is constructed from 𝐹𝑖 which is the output of learnable ℎ. Here, ℎ is updated by the gradient from the 𝐹𝑜 similar to CUT (Park et al. 2020).
图10:邻接矩阵 𝐴 是从 𝐹𝑖 构造的, 𝐹𝑖 是可学习的 ℎ 的输出。这里,与CUT类似, ℎ 由 𝐹𝑜 的梯度更新(Park等人,2020)。


















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











