






Unsupervised Image-to-Image Translation Networks
无监督图像到图像翻译网络
刘明玉,Thomas Breuel,Jan Kautz
NVIDIA {mingyul,tbreuel,jkautz}@nvidia.com
NVIDIA {mingyul,tbreuel,jkautz}@ nvidia.com(NVIDIA)
Abstract 摘要 [1703.00848] Unsupervised Image-to-Image Translation Networks
Unsupervised image-to-image translation aims at learning a joint distribution of images in different domains by using images from the marginal distributions in individual domains. Since there exists an infinite set of joint distributions that can arrive the given marginal distributions, one could infer nothing about the joint distribution from the marginal distributions without additional assumptions. To address the problem, we make a shared-latent space assumption and propose an unsupervised image-to-image translation framework based on Coupled GANs. We compare the proposed framework with competing approaches and present high quality image translation results on various challenging unsupervised image translation tasks, including street scene image translation, animal image translation, and face image translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on benchmark datasets. Code and additional results are available in GitHub - mingyuliutw/UNIT: Unsupervised Image-to-Image Translation.
无监督图像到图像翻译的目的是通过使用来自各个域中的边缘分布的图像来学习不同域中的图像的联合分布。由于存在一个无限多的联合分布集,可以到达给定的边缘分布,人们不能推断出任何关于联合分布的边缘分布没有额外的假设。为了解决这个问题,我们提出了一个共享潜在空间假设,并提出了一个基于耦合GAN的无监督图像到图像翻译框架。我们将所提出的框架与竞争方法进行比较,并在各种具有挑战性的无监督图像翻译任务上呈现高质量的图像翻译结果,包括街景图像翻译,动物图像翻译和人脸图像翻译。我们还将所提出的框架应用于域自适应,并在基准数据集上实现了最先进的性能。 代码和其他结果可在https://github.com/mingyuliutw/unit上找到。
1Introduction 1介绍
Many computer visions problems can be posed as an image-to-image translation problem, mapping an image in one domain to a corresponding image in another domain. For example, super-resolution can be considered as a problem of mapping a low-resolution image to a corresponding high-resolution image; colorization can be considered as a problem of mapping a gray-scale image to a corresponding color image. The problem can be studied in supervised and unsupervised learning settings. In the supervised setting, paired of corresponding images in different domains are available [8, 15]. In the unsupervised setting, we only have two independent sets of images where one consists of images in one domain and the other consists of images in another domain—there exist no paired examples showing how an image could be translated to a corresponding image in another domain. Due to lack of corresponding images, the UNsupervised Image-to-image Translation (UNIT) problem is considered harder, but it is more applicable since training data collection is easier.
许多计算机视觉问题可以被视为图像到图像的转换问题,将一个域中的图像映射到另一个域中的相应图像。例如,超分辨率可以被认为是将低分辨率图像映射到对应的高分辨率图像的问题;彩色化可以被认为是将灰度图像映射到对应的彩色图像的问题。这个问题可以在监督和无监督学习环境中进行研究。在监督设置中,不同域中的对应图像配对可用[ 8,15]。在无监督设置中,我们只有两个独立的图像集,其中一个由一个域中的图像组成,另一个由另一个域中的图像组成-没有配对的例子显示如何将图像转换为另一个域中的相应图像。 由于缺乏相应的图像,无监督的图像到图像翻译(UNIT)问题被认为是困难的,但它更适用,因为训练数据收集更容易。
When analyzing the image translation problem from a probabilistic modeling perspective, the key challenge is to learn a joint distribution of images in different domains. In the unsupervised setting, the two sets consist of images from two marginal distributions in two different domains, and the task is to infer the joint distribution using these images. The coupling theory [16] states there exist an infinite set of joint distributions that can arrive the given marginal distributions in general. Hence, inferring the joint distribution from the marginal distributions is a highly ill-posed problem. To address the ill-posed problem, we need additional assumptions on the structure of the joint distribution.
当从概率建模的角度分析图像翻译问题时,关键的挑战是学习图像在不同域中的联合分布。在无监督设置中,这两个集合由来自两个不同域中的两个边缘分布的图像组成,并且任务是使用这些图像来推断联合分布。耦合理论[ 16]指出,存在一组无限的联合分布,它们通常可以达到给定的边缘分布。因此,从边缘分布推断联合分布是一个高度不适定的问题。为了解决不适定问题,我们需要对联合分布的结构进行额外的假设。
To this end we make a shared-latent space assumption, which assumes a pair of corresponding images in different domains can be mapped to a same latent representation in a shared-latent space. Based on the assumption, we propose a UNIT framework that are based on generative adversarial networks (GANs) and variational autoencoders (VAEs). We model each image domain using a VAE-GAN. The adversarial training objective interacts with a weight-sharing constraint, which enforces a shared-latent space, to generate corresponding images in two domains, while the variational autoencoders relate translated images with input images in the respective domains. We applied the proposed framework to various unsupervised image-to-image translation problems and achieved high quality image translation results. We also applied it to the domain adaptation problem and achieved state-of-the-art accuracies on benchmark datasets. The shared-latent space assumption was used in Coupled GAN [17] for joint distribution learning. Here, we extend the Coupled GAN work for the UNIT problem. We also note that several contemporary works propose the cycle-consistency constraint assumption [29, 10], which hypothesizes the existence of a cycle-consistency mapping so that an image in the source domain can be mapped to an image in the target domain and this translated image in the target domain can be mapped back to the original image in the source domain. In the paper, we show that the shared-latent space constraint implies the cycle-consistency constraint.
为此,我们做了一个共享潜在空间的假设,它假设一对相应的图像在不同的域可以映射到一个相同的潜在表示在共享潜在空间。基于这一假设,我们提出了一个基于生成对抗网络(GAN)和变分自编码器(VAE)的UNIT框架。我们使用VAE-GAN对每个图像域进行建模。对抗训练目标与权重共享约束相互作用,该约束强制执行共享潜在空间,以在两个域中生成相应的图像,而变分自编码器将翻译图像与相应域中的输入图像相关联。我们将所提出的框架应用于各种无监督图像到图像的翻译问题,并取得了高质量的图像翻译结果。我们还将其应用于域自适应问题,并在基准数据集上实现了最先进的精度。 共享潜在空间假设在耦合GAN [ 17]中用于联合分布学习。在这里,我们扩展耦合GAN工作的单位问题。我们还注意到,一些当代作品提出了循环一致性约束假设[29,10],该假设存在循环一致性映射,使得源域中的图像可以映射到目标域中的图像,并且目标域中的该翻译图像可以映射回源域中的原始图像。在本文中,我们证明了共享潜在空间约束意味着循环一致性约束。
2Assumptions 2假设
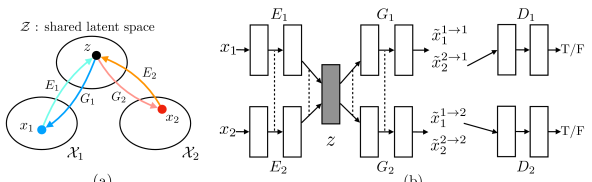
Figure 1:(a) The shared latent space assumption. We assume a pair of corresponding images (𝑥1,𝑥2) in two different domains 𝒳1 and 𝒳2 can be mapped to a same latent code 𝑧 in a shared-latent space 𝒵. 𝐸1 and 𝐸2 are two encoding functions, mapping images to latent codes. 𝐺1 and 𝐺2 are two generation functions, mapping latent codes to images. (b) The proposed UNIT framework. We represent 𝐸1 𝐸2 𝐺1 and 𝐺2 using CNNs and implement the shared-latent space assumption using a weight sharing constraint where the connection weights of the last few layers (high-level layers) in 𝐸1 and 𝐸2 are tied (illustrated using dashed lines) and the connection weights of the first few layers (high-level layers) in 𝐺1 and 𝐺2 are tied. Here, 𝑥~11→1 and 𝑥~22→2 are self-reconstructed images, and 𝑥~11→2 and 𝑥~22→1 are domain-translated images. 𝐷1 and 𝐷2 are adversarial discriminators for the respective domains, in charge of evaluating whether the translated images are realistic.
图1:(a)共享潜在空间假设。我们假设两个不同域 𝒳1 和 𝒳2 中的一对对应图像 (𝑥1,𝑥2) 可以映射到共享潜在空间 𝒵 中的相同潜在码 𝑧 。 𝐸1 和 𝐸2 是两个编码函数,将图像映射到潜码。 𝐺1 和 𝐺2 是两个生成函数,将潜在代码映射到图像。(b)拟议的联检组框架。我们使用CNN表示 𝐸1 、 𝐸2 、 𝐺1 和 𝐺2 ,并使用权重共享约束来实现共享潜在空间假设,其中 𝐸1 和 𝐸2 中的最后几层(高级层)的连接权重是绑定的(使用虚线示出),并且 𝐺1 和 𝐺2 中的前几层(高级层)的连接权重是绑定的。这里, 𝑥~11→1 和 𝑥~22→2 是自重构图像, 𝑥~11→2 和 𝑥~22→1 是域平移图像。 𝐷1 和 𝐷2 是各自领域的对抗鉴别器,负责评估翻译后的图像是否真实。 Table 1:Interpretation of the roles of the subnetworks in the proposed framework.
表1:对拟议框架中各子网络作用的解释。
| Networks | {𝐸1,𝐺1} | {𝐸1,𝐺2} | {𝐺1,𝐷1} | {𝐸1,𝐺1,𝐷1} | {𝐺1,𝐺2,𝐷1,𝐷2} |
|---|---|---|---|---|---|
| Roles | VAE for 𝒳1 重试 错误原因 | Image Translator 𝒳1→𝒳2 重试 错误原因 | GAN for 𝒳1 重试 错误原因 | VAE-GAN [14] 重试 错误原因 | CoGAN [17] 重试 错误原因 |
Let 𝒳1 and 𝒳2 be two image domains. In supervised image-to-image translation, we are given samples (𝑥1,𝑥2) drawn from a joint distribution 𝑃𝒳1,𝒳2(𝑥1,𝑥2). In unsupervised image-to-image translation, we are given samples drawn from the marginal distributions 𝑃𝒳1(𝑥1) and 𝑃𝒳2(𝑥2). Since an infinite set of possible joint distributions can yield the given marginal distributions, we could infer nothing about the joint distribution from the marginal samples without additional assumptions.
假设 𝒳1 和 𝒳2 是两个图像域。在有监督的图像到图像的翻译中,我们被给予从联合分布 𝑃𝒳1,𝒳2(𝑥1,𝑥2) 中提取的样本 (𝑥1,𝑥2) 。在无监督图像到图像的翻译中,我们从边缘分布 𝑃𝒳1(𝑥1) 和 𝑃𝒳2(𝑥2) 中提取样本。由于可能的联合分布的无限集合可以产生给定的边缘分布,因此在没有额外假设的情况下,我们无法从边缘样本中推断出任何关于联合分布的信息。
We make the shared-latent space assumption. As shown Figure 1, we assume for any given pair of images 𝑥1 and 𝑥2, there exists a shared latent code 𝑧 in a shared-latent space, such that we can recover both images from this code, and we can compute this code from each of the two images. That is, we postulate there exist functions 𝐸1∗, 𝐸2∗, 𝐺1∗, and 𝐺2∗ such that, given a pair of corresponding images (𝑥1,𝑥2) from the joint distribution, we have 𝑧=𝐸1∗(𝑥1)=𝐸2∗(𝑥2) and conversely 𝑥1=𝐺1∗(𝑧) and 𝑥2=𝐺2∗(𝑧). Within this model, the function 𝑥2=𝐹1→2∗(𝑥1) that maps from 𝒳1 to 𝒳2 can be represented by the composition 𝐹1→2∗(𝑥1)=𝐺2∗(𝐸1∗(𝑥1)). Similarly, 𝑥1=𝐹2→1∗(𝑥2)=𝐺1∗(𝐸2∗(𝑥2)). The UNIT problem then becomes a problem of learning 𝐹1→2∗ and 𝐹2→1∗. We note that a necessary condition for 𝐹1→2∗ and 𝐹2→1∗ to exist is the cycle-consistency constraint [29, 10]: 𝑥1=𝐹2→1∗(𝐹1→2∗(𝑥1)) and 𝑥2=𝐹1→2∗(𝐹2→1∗(𝑥2)). We can reconstruct the input image from translating back the translated input image. In other words, the proposed shared-latent space assumption implies the cycle-consistency assumption (but not vice versa).
我们假设共享潜在空间。如图1所示,我们假设对于任何给定的一对图像 𝑥1 和 𝑥2 ,在共享潜在空间中存在共享潜在代码 𝑧 ,使得我们可以从该代码恢复两个图像,并且我们可以从两个图像中的每一个计算该代码。也就是说,我们假设存在函数 𝐸1∗ 、 𝐸2∗ 、 𝐺1∗ 和 𝐺2∗ ,使得给定来自联合分布的一对对应图像 (𝑥1,𝑥2) ,我们有 𝑧=𝐸1∗(𝑥1)=𝐸2∗(𝑥2) ,反之有 𝑥1=𝐺1∗(𝑧) 和 𝑥2=𝐺2∗(𝑧) 。在该模型中,从 𝒳1 映射到 𝒳2 的函数 𝑥2=𝐹1→2∗(𝑥1) 可以由组合 𝐹1→2∗(𝑥1)=𝐺2∗(𝐸1∗(𝑥1)) 表示。 𝑥1=𝐹2→1∗(𝑥2)=𝐺1∗(𝐸2∗(𝑥2)) 也一样。然后,UNIT问题变成了学习 𝐹1→2∗ 和 𝐹2→1∗ 的问题。我们注意到 𝐹1→2∗ 和 𝐹2→1∗ 存在的必要条件是循环一致性约束[29,10]: 𝑥1=𝐹2→1∗(𝐹1→2∗(𝑥1)) 和 𝑥2=𝐹1→2∗(𝐹2→1∗(𝑥2)) 。我们可以通过将翻译后的输入图像翻译回来重建输入图像。 换句话说,提出的共享潜在空间假设意味着循环一致性假设(但反之亦然)。
To implement the shared-latent space assumption, we further assume a shared intermediate representation ℎ such that the process of generating a pair of corresponding images admits a form of
为了实现共享潜在空间假设,我们进一步假设共享中间表示 ℎ ,使得生成一对对应图像的过程允许以下形式:
| 𝑧→ℎ↗𝑥1↘𝑥2. | (1) |
Consequently, we have 𝐺1∗≡𝐺𝐿,1∗∘𝐺𝐻∗ and 𝐺2∗≡𝐺𝐿,2∗∘𝐺𝐻∗ where 𝐺𝐻∗ is a common high-level generation function that maps 𝑧 to ℎ and 𝐺𝐿,1∗ and 𝐺𝐿,2∗ are low-level generation functions that map ℎ to 𝑥1 and 𝑥2, respectively. In the case of multi-domain image translation (e.g., sunny and rainy image translation), 𝑧 can be regarded as the compact, high-level representation of a scene ("car in front, trees in back"), and ℎ can be considered a particular realization of 𝑧 through 𝐺𝐻∗ ("car/tree occupy the following pixels"), and 𝐺𝐿,1∗ and 𝐺𝐿,2∗ would be the actual image formation functions in each modality ("tree is lush green in the sunny domain, but dark green in the rainy domain"). Assuming ℎ also allow us to represent 𝐸1∗ and 𝐸2∗ by 𝐸1∗≡𝐸𝐻∗∘𝐸𝐿,1∗ and 𝐸2∗≡𝐸𝐻∗∘𝐸𝐿,2∗.
因此,我们有 𝐺1∗≡𝐺𝐿,1∗∘𝐺𝐻∗ 和 𝐺2∗≡𝐺𝐿,2∗∘𝐺𝐻∗ ,其中 𝐺𝐻∗ 是将 𝑧 映射到 ℎ 的公共高级生成函数,而 𝐺𝐿,1∗ 和 𝐺𝐿,2∗ 是分别将 ℎ 映射到 𝑥1 和 𝑥2 的低级生成函数。在多域图像平移的情况下(例如,晴天和雨天的图像转换), 𝑧 可以被视为场景的紧凑、高级表示(“车在前,树在后”),而 ℎ 可以被认为是 𝑧 到 𝐺𝐻∗ 的特定实现(“汽车/树占据随后的像素”),并且 𝐺𝐿,1∗ 和 𝐺𝐿,2∗ 将是每个模态中的实际图像形成功能(“树在阳光下是郁郁葱葱的绿色,但在下雨的领域是黑暗的绿色”)。假设 ℎ 也允许我们用 𝐸1∗≡𝐸𝐻∗∘𝐸𝐿,1∗ 和 𝐸2∗≡𝐸𝐻∗∘𝐸𝐿,2∗ 表示 𝐸1∗ 和 𝐸2∗ 。
In the next section, we discuss how we realize the above ideas in the proposed UNIT framework.
在下一节中,我们将讨论如何在建议的UNIT框架中实现上述想法。
3Framework 3框架
Our framework, as illustrated in Figure 1, is based on variational autoencoders (VAEs) [13, 22, 14] and generative adversarial networks (GANs) [6, 17]. It consists of 6 subnetworks: including two domain image encoders 𝐸1 and 𝐸2, two domain image generators 𝐺1 and 𝐺2, and two domain adversarial discriminators 𝐷1 and 𝐷2. Several ways exist to interpret the roles of the subnetworks, which we summarize in Table 1. Our framework learns translation in both directions in one shot.
如图1所示,我们的框架基于变分自编码器(VAE)[13,22,14]和生成对抗网络(GAN)[6,17]。它由6个子网络组成:包括两个域图像编码器 𝐸1 和 𝐸2 ,两个域图像生成器 𝐺1 和 𝐺2 ,以及两个域对抗鉴别器 𝐷1 和 𝐷2 。有几种方法可以解释子网络的作用,我们在表1中总结了这些方法。我们的框架一次学习两个方向的翻译。
VAE. The encoder–generator pair {𝐸1,𝐺1} constitutes a VAE for the 𝒳1 domain, termed VAE1. For an input image 𝑥1∈𝒳1, the VAE1 first maps 𝑥1 to a code in a latent space 𝒵 via the encoder 𝐸1 and then decodes a random-perturbed version of the code to reconstruct the input image via the generator 𝐺1. We assume the components in the latent space 𝒵 are conditionally independent and Gaussian with unit variance. In our formulation, the encoder outputs a mean vector 𝐸𝜇,1(𝑥1) and the distribution of the latent code 𝑧1 is given by 𝑞1(𝑧1|𝑥1)≡𝒩(𝑧1|𝐸𝜇,1(𝑥1),𝐼) where 𝐼 is an identity matrix. The reconstructed image is 𝑥~11→1=𝐺1(𝑧1∼𝑞1(𝑧1|𝑥1)). Note that here we abused the notation since we treated the distribution of 𝑞1(𝑧1|𝑥1) as a random vector of 𝒩(𝐸𝜇,1(𝑥1),𝐼) and sampled from it. Similarly, {𝐸2,𝐺2} constitutes a VAE for 𝒳2: VAE2 where the encoder 𝐸2 outputs a mean vector 𝐸𝜇,2(𝑥2) and the distribution of the latent code 𝑧2 is given by 𝑞2(𝑧2|𝑥2)≡𝒩(𝑧2|𝐸𝜇,2(𝑥2),𝐼). The reconstructed image is 𝑥~22→2=𝐺2(𝑧2∼𝑞2(𝑧2|𝑥2)).
VAE。编码器—生成器对 {𝐸1,𝐺1} 构成用于 𝒳1 域的VAE,称为VAE 1 。对于输入图像 𝑥1∈𝒳1 ,VAE 1 首先经由编码器 𝐸1 将 𝑥1 映射到潜在空间 𝒵 中的码,然后经由生成器 𝐺1 解码该码的随机扰动版本以重构输入图像。我们假设潜在空间 𝒵 中的分量是条件独立的,并且是具有单位方差的高斯分布。在我们的公式中,编码器输出平均向量 𝐸𝜇,1(𝑥1) ,并且潜码 𝑧1 的分布由 𝑞1(𝑧1|𝑥1)≡𝒩(𝑧1|𝐸𝜇,1(𝑥1),𝐼) 给出,其中 𝐼 是单位矩阵。重建图像为 𝑥~11→1=𝐺1(𝑧1∼𝑞1(𝑧1|𝑥1)) 。类似地, {𝐸2,𝐺2} 构成了 𝒳2 的VAE:VAE 2 ,其中编码器 𝐸2 输出平均向量 𝐸𝜇,2(𝑥2) ,并且潜码 𝑧2 的分布由 𝑞2(𝑧2|𝑥2)≡𝒩(𝑧2|𝐸𝜇,2(𝑥2),𝐼) 给出。重建图像为 𝑥~22→2=𝐺2(𝑧2∼𝑞2(𝑧2|𝑥2)) 。
Utilizing the reparameterization trick [13], the non-differentiable sampling operation can be reparameterized as a differentiable operation using auxiliary random variables. This reparameterization trick allows us to train VAEs using back-prop. Let 𝜂 be a random vector with a multi-variate Gaussian distribution: 𝜂∼𝒩(𝜂|0,𝐼). The sampling operations of 𝑧1∼𝑞1(𝑧1|𝑥1) and 𝑧2∼𝑞2(𝑧2|𝑥2) can be implemented via 𝑧1=𝐸𝜇,1(𝑥1)+𝜂 and 𝑧2=𝐸𝜇,2(𝑥2)+𝜂, respectively.
利用重新参数化技巧[ 13],不可微采样操作可以使用辅助随机变量重新参数化为可微操作。这个重新参数化的技巧允许我们使用反向传播来训练VAE。让 𝜂 是一个具有多变量高斯分布的随机向量: 𝜂∼𝒩(𝜂|0,𝐼) 。 𝑧1∼𝑞1(𝑧1|𝑥1) 和 𝑧2∼𝑞2(𝑧2|𝑥2) 的采样操作可以分别通过 𝑧1=𝐸𝜇,1(𝑥1)+𝜂 和 𝑧2=𝐸𝜇,2(𝑥2)+𝜂 来实现。
Weight-sharing. Based on the shared-latent space assumption discussed in Section 2, we enforce a weight-sharing constraint to relate the two VAEs. Specifically, we share the weights of the last few layers of 𝐸1 and 𝐸2 that are responsible for extracting high-level representations of the input images in the two domains. Similarly, we share the weights of the first few layers of 𝐺1 and 𝐺2 responsible for decoding high-level representations for reconstructing the input images.
体重分担基于第2节中讨论的共享潜在空间假设,我们强制执行权重共享约束来关联两个VAE。具体来说,我们共享 𝐸1 和 𝐸2 的最后几层的权重,这两层负责提取两个域中输入图像的高级表示。类似地,我们共享负责解码用于重建输入图像的高级表示的 𝐺1 和 𝐺2 的前几层的权重。
Note that the weight-sharing constraint alone does not guarantee that corresponding images in two domains will have the same latent code. In the unsupervised setting, no pair of corresponding images in the two domains exists to train the network to output a same latent code. The extracted latent codes for a pair of corresponding images are different in general. Even if they are the same, the same latent component may have different semantic meanings in different domains. Hence, the same latent code could still be decoded to output two unrelated images. However, we will show that through adversarial training, a pair of corresponding images in the two domains can be mapped to a common latent code by 𝐸1 and 𝐸2, respectively, and a latent code will be mapped to a pair of corresponding images in the two domains by 𝐺1 and 𝐺2, respectively.
注意,单独的权重共享约束不能保证两个域中的对应图像将具有相同的潜码。在无监督设置中,两个域中不存在对应的图像对来训练网络以输出相同的潜码。针对一对对应图像提取的潜码通常是不同的。即使它们是相同的,同一个潜在成分在不同的领域也可能有不同的语义。因此,相同的潜码仍然可以被解码以输出两个不相关的图像。然而,我们将证明,通过对抗训练,两个域中的一对对应图像可以分别通过 𝐸1 和 𝐸2 映射到公共潜码,并且潜码将分别通过 𝐺1 和 𝐺2 映射到两个域中的一对对应图像。
The shared-latent space assumption allows us to perform image-to-image translation. We can translate an image 𝑥1 in 𝒳1 to an image in 𝒳2 through applying 𝐺2(𝑧1∼𝑞1(𝑧1|𝑥1)). We term such an information processing stream as the image translation stream. Two image translation streams exist in the proposed framework: 𝒳1→𝒳2 and 𝒳2→𝒳1. The two streams are trained jointly with the two image reconstruction streams from the VAEs. Once we could ensure that a pair of corresponding images are mapped to a same latent code and a same latent code is decoded to a pair of corresponding images, (𝑥1,𝐺2(𝑧1∼𝑞1(𝑧1|𝑥1))) would form a pair of corresponding images. In other words, the composition of 𝐸1 and 𝐺2 functions approximates 𝐹1→2∗ for unsupervised image-to-image translation discussed in Section 2, and the composition of 𝐸2 and 𝐺1 function approximates 𝐹2→1∗.
共享潜在空间假设允许我们执行图像到图像的转换。我们可以通过应用 𝐺2(𝑧1∼𝑞1(𝑧1|𝑥1)) 将 𝒳1 中的图像 𝑥1 转换为 𝒳2 中的图像。我们将这样的信息处理流称为图像翻译流。在所提出的框架中存在两个图像翻译流: 𝒳1→𝒳2 和 𝒳2→𝒳1 。这两个流与来自VAE的两个图像重建流联合训练。一旦我们可以确保一对对应的图像被映射到相同的潜码,并且相同的潜码被解码为一对对应的图像, (𝑥1,𝐺2(𝑧1∼𝑞1(𝑧1|𝑥1))) 将形成一对对应的图像。换句话说,对于第2节中讨论的无监督图像到图像转换, 𝐸1 和 𝐺2 函数的组合近似于 𝐹1→2∗ ,并且 𝐸2 和 𝐺1 函数的组合近似于 𝐹2→1∗ 。
GANs. Our framework has two generative adversarial networks: GAN1={𝐷1,𝐺1} and GAN2={𝐷2,𝐺2}. In GAN1, for real images sampled from the first domain, 𝐷1 should output true, while for images generated by 𝐺1, it should output false. 𝐺1 can generate two types of images: 1) images from the reconstruction stream 𝑥~11→1=𝐺1(𝑧1∼𝑞1(𝑧1|𝑥1)) and 2) images from the translation stream 𝑥~22→1=𝐺1(𝑧2∼𝑞2(𝑧2|𝑥2)). Since the reconstruction stream can be supervisedly trained, it is suffice that we only apply adversarial training to images from the translation stream, 𝑥~22→1. We apply a similar processing to GAN2 where 𝐷2 is trained to output true for real images sampled from the second domain dataset and false for images generated from 𝐺2.
GAN我们的框架有两个生成对抗网络: GAN1={𝐷1,𝐺1} 和 GAN2={𝐷2,𝐺2} 。在 GAN1 中,对于从第一域采样的真实的图像, 𝐷1 应该输出真,而对于由 𝐺1 生成的图像,它应该输出假。 𝐺1 可以生成两种类型的图像:1)来自重建流 𝑥~11→1=𝐺1(𝑧1∼𝑞1(𝑧1|𝑥1)) 的图像和2)来自转换流 𝑥~22→1=𝐺1(𝑧2∼𝑞2(𝑧2|𝑥2)) 的图像。由于重建流可以被监督训练,所以我们只对来自翻译流的图像应用对抗训练就足够了, 𝑥~22→1 。我们对 GAN2 应用类似的处理,其中 𝐷2 被训练为对于从第二域数据集采样的真实的图像输出真,并且对于从 𝐺2 生成的图像输出假。
Cycle-consistency (CC). Since the shared-latent space assumption implies the cycle-consistency constraint (See Section 2), we could also enforce the cycle-consistency constraint in the proposed framework to further regularize the ill-posed unsupervised image-to-image translation problem. The resulting information processing stream is called the cycle-reconstruction stream.
循环一致性(CC)。由于共享潜在空间假设隐含了循环一致性约束(见第2节),我们还可以在所提出的框架中强制执行循环一致性约束,以进一步正则化不适定的无监督图像到图像翻译问题。所得到的信息处理流被称为循环重构流。
Learning. We jointly solve the learning problems of the VAE1, VAE2, GAN1 and GAN2 for the image reconstruction streams, the image translation streams, and the cycle-reconstruction streams:
学习我们共同解决了图像重建流、图像平移流和循环重建流的VAE 1 、VAE 2 、GAN 1 和GAN 2 的学习问题:
| min𝐸1,𝐸2,𝐺1,𝐺2max𝐷1,𝐷2 | ℒVAE1(𝐸1,𝐺1)+ℒGAN1(𝐸2,𝐺1,𝐷1)+ℒCC1(𝐸1,𝐺1,𝐸2,𝐺2) | |||
| ℒVAE2(𝐸2,𝐺2)+ℒGAN2(𝐸1,𝐺2,𝐷2)+ℒCC2(𝐸2,𝐺2,𝐸1,𝐺1). | (2) |
VAE training aims for minimizing a variational upper bound In (2), the VAE objects are
VAE训练旨在最小化变分上界。在(2)中,VAE对象是
| ℒVAE1(𝐸1,𝐺1)= | 𝜆1KL(𝑞1(𝑧1|𝑥1)||𝑝𝜂(𝑧))−𝜆2𝔼𝑧1∼𝑞1(𝑧1|𝑥1)[log𝑝𝐺1(𝑥1|𝑧1)] | (3) | ||
| ℒVAE2(𝐸2,𝐺2)= | 𝜆1KL(𝑞2(𝑧2|𝑥2)||𝑝𝜂(𝑧))−𝜆2𝔼𝑧2∼𝑞2(𝑧2|𝑥2)[log𝑝𝐺2(𝑥2|𝑧2)]. | (4) |
where the hyper-parameters 𝜆1 and 𝜆2 control the weights of the objective terms and the KL divergence terms penalize deviation of the distribution of the latent code from the prior distribution. The regularization allows an easy way to sample from the latent space [13]. We model 𝑝𝐺1 and 𝑝𝐺2 using Laplacian distributions, respectively. Hence, minimizing the negative log-likelihood term is equivalent to minimizing the absolute distance between the image and the reconstructed image. The prior distribution is a zero mean Gaussian 𝑝𝜂(𝑧)=𝒩(𝑧|0,𝐼).
其中超参数 𝜆1 和 𝜆2 控制目标项的权重,并且KL发散项惩罚潜在码的分布与先验分布的偏差。正则化允许一种简单的方法从潜在空间中采样[13]。我们分别使用拉普拉斯分布对 𝑝𝐺1 和 𝑝𝐺2 进行建模。因此,最小化负对数似然项相当于最小化图像与重建图像之间的绝对距离。先验分布是零均值高斯分布 𝑝𝜂(𝑧)=𝒩(𝑧|0,𝐼) 。
In (2), the GAN objective functions are given by
在(2)中,GAN目标函数由下式给出:
| ℒGAN1 | (𝐸2,𝐺1,𝐷1)=𝜆0𝔼𝑥1∼𝑃𝒳1[log𝐷1(𝑥1)]+𝜆0𝔼𝑧2∼𝑞2(𝑧2|𝑥2)[log(1−𝐷1(𝐺1(𝑧2)))] | (5) | ||
| ℒGAN2 | (𝐸1,𝐺2,𝐷2)=𝜆0𝔼𝑥2∼𝑃𝒳2[log𝐷2(𝑥2)]+𝜆0𝔼𝑧1∼𝑞1(𝑧1|𝑥1)[log(1−𝐷2(𝐺2(𝑧1)))]. | (6) |
The objective functions in (5) and (6) are conditional GAN objective functions. They are used to ensure the translated images resembling images in the target domains, respectively. The hyper-parameter 𝜆0 controls the impact of the GAN objective functions.
(5)和(6)中的目标函数是条件GAN目标函数。它们分别用于确保翻译后的图像与目标域中的图像相似。超参数 𝜆0 控制GAN目标函数的影响。
We use a VAE-like objective function to model the cycle-consistency constraint, which is given by
我们使用类似VAE的目标函数来模拟循环一致性约束,其由下式给出:
| ℒCC1(𝐸1,𝐺1,𝐸2,𝐺2)= | 𝜆3KL(𝑞1(𝑧1|𝑥1)||𝑝𝜂(𝑧))+𝜆3KL(𝑞2(𝑧2|𝑥11→2))||𝑝𝜂(𝑧))− | |||
| 𝜆4𝔼𝑧2∼𝑞2(𝑧2|𝑥11→2)[log𝑝𝐺1(𝑥1|𝑧2)] | (7) | |||
| ℒCC2(𝐸2,𝐺2,𝐸1,𝐺1)= | 𝜆3KL(𝑞2(𝑧2|𝑥2)||𝑝𝜂(𝑧))+𝜆3KL(𝑞1(𝑧1|𝑥22→1))||𝑝𝜂(𝑧))− | |||
| 𝜆4𝔼𝑧1∼𝑞1(𝑧1|𝑥22→1)[log𝑝𝐺2(𝑥2|𝑧1)]. | (8) |
where the negative log-likelihood objective term ensures a twice translated image resembles the input one and the KL terms penalize the latent codes deviating from the prior distribution in the cycle-reconstruction stream (Therefore, there are two KL terms). The hyper-parameters 𝜆3 and 𝜆4 control the weights of the two different objective terms.
其中,负对数似然目标项确保两次平移的图像类似于输入图像,并且KL项惩罚偏离循环重构流中的先验分布的潜码(因此,存在两个KL项)。超参数 𝜆3 和 𝜆4 控制两个不同目标项的权重。
Inheriting from GAN, training of the proposed framework results in solving a mini-max problem where the optimization aims to find a saddle point. It can be seen as a two player zero-sum game. The first player is a team consisting of the encoders and generators. The second player is a team consisting of the adversarial discriminators. In addition to defeating the second player, the first player has to minimize the VAE losses and the cycle-consistency losses. We apply an alternating gradient update scheme similar to the one described in [6] to solve (2). Specifically, we first apply a gradient ascent step to update 𝐷1 and 𝐷2 with 𝐸1, 𝐸2, 𝐺1, and 𝐺2 fixed. We then apply a gradient descent step to update 𝐸1, 𝐸2, 𝐺1, and 𝐺2 with 𝐷1 and 𝐷2 fixed.
继承自GAN,所提出的框架的训练结果是解决最小-最大问题,其中优化的目的是找到鞍点。这可以看作是一个两个玩家的零和游戏。第一个玩家是一个由编码器和生成器组成的团队。第二个参与者是一个由对抗性鉴别者组成的团队。除了击败第二个玩家之外,第一个玩家还必须最小化VAE损失和循环一致性损失。我们应用类似于[ 6]中描述的交替梯度更新方案来求解(2)。具体来说,我们首先应用梯度上升步骤来更新 𝐷1 和 𝐷2 ,其中 𝐸1 、 𝐸2 、 𝐺1 和 𝐺2 固定。然后,我们应用梯度下降步骤来更新 𝐸1 , 𝐸2 , 𝐺1 和 𝐺2 ,其中 𝐷1 和 𝐷2 固定。
Translation: After learning, we obtain two image translation functions by assembling a subset of the subnetworks. We have 𝐹1→2(𝑥1)=𝐺2(𝑧1∼𝑞1(𝑧1|𝑥1)) for translating images from 𝒳1 to 𝒳2 and 𝐹2→1(𝑥2)=𝐺1(𝑧2∼𝑞2(𝑧2|𝑥2)) for translating images from 𝒳2 to 𝒳1.
翻译:在学习之后,我们通过组装子网络的子集来获得两个图像翻译函数。我们使用 𝐹1→2(𝑥1)=𝐺2(𝑧1∼𝑞1(𝑧1|𝑥1)) 将图像从 𝒳1 转换为 𝒳2 ,使用 𝐹2→1(𝑥2)=𝐺1(𝑧2∼𝑞2(𝑧2|𝑥2)) 将图像从 𝒳2 转换为 𝒳1 。
















 5284
5284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











