import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
# Download data from open datasetsfrom download import download
url ="https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url,"./", kind="zip", replace=True)
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(),1e-2)# 1. Define forward functiondefforward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)return loss, logits
# 2. Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn,None, optimizer.parameters, has_aux=True)# 3. Define function of one-step trainingdeftrain_step(data, label):(loss, _), grads = grad_fn(data, label)
optimizer(grads)return loss
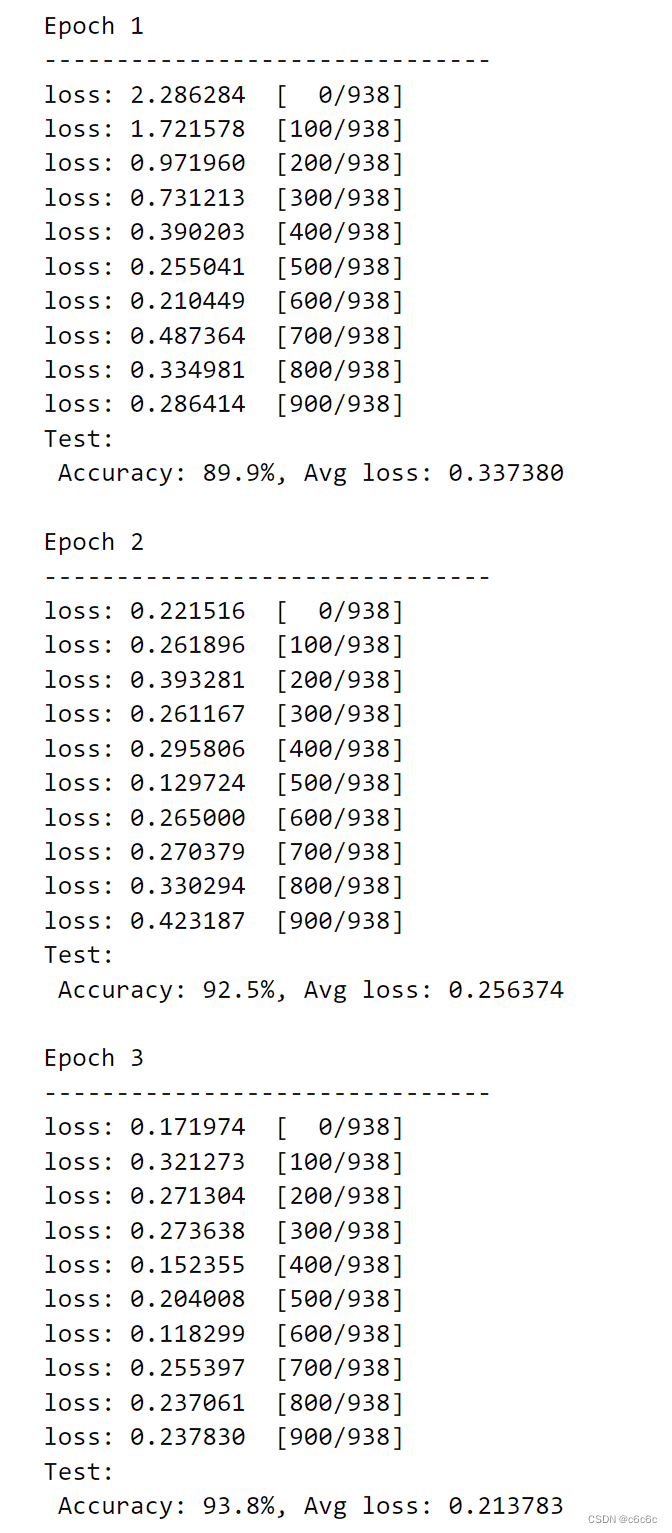
deftrain(model, dataset):
size = dataset.get_dataset_size()
model.set_train()for batch,(data, label)inenumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)if batch %100==0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")deftest(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct =0,0,0for data, label in dataset.create_tuple_iterator():
pred = model(data)
total +=len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct +=(pred.argmax(1)== label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs =3for t inrange(epochs):print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)print("Done!")
保存模型
mindspore.save_checkpoint(model,"model.ckpt")
加载模型
mindspore.save_checkpoint(model,"model.ckpt")# Instantiate a random initialized model
model = Network()# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)#为空时代表所有参数均加载成功print(param_not_load)
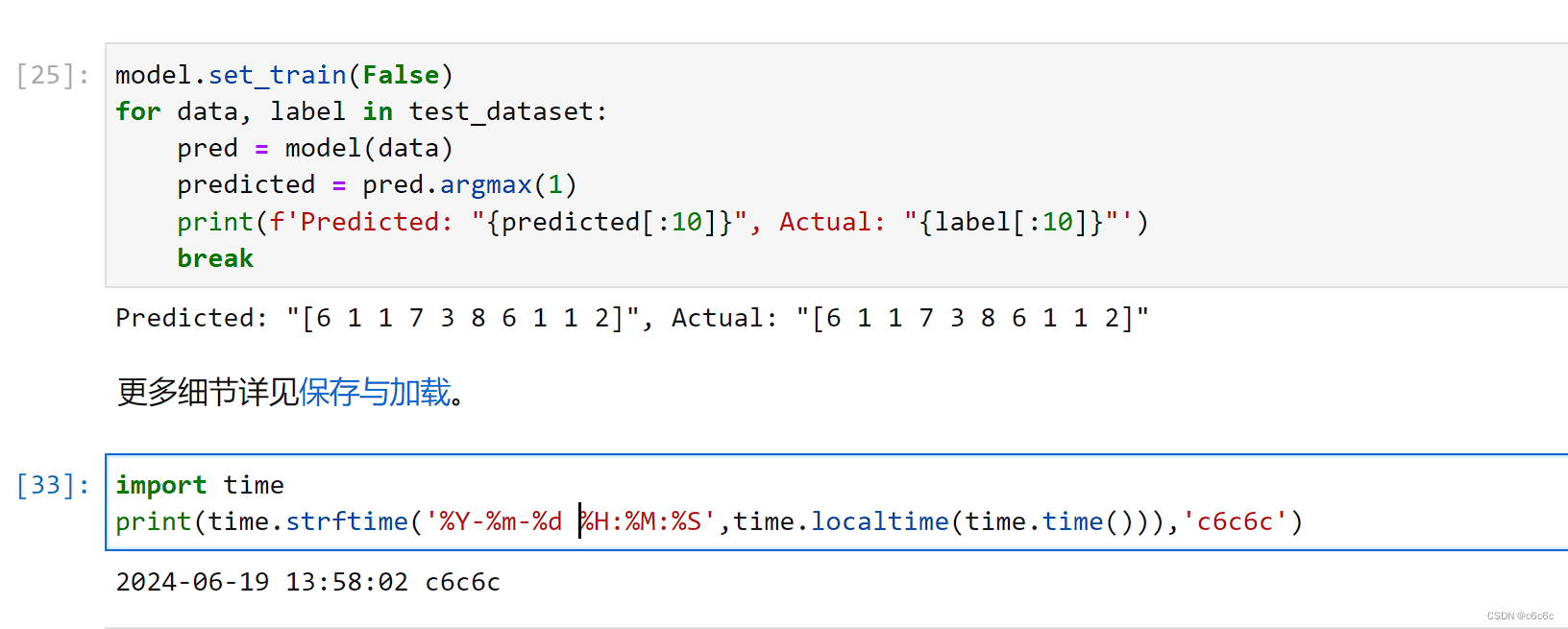
使用模型推理
model.set_train(False)for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')break























 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









