







 本文介绍了 Transformer 变体的发展,包括 Transformer-XL 的 segment-level recurrence 和相对位置编码,以及一系列优化复杂度的模型:Explicit Sparse Transformer、Longformer、Switch Transformer、Routing Transformer 和 Linformer。这些模型旨在处理长序列、提高注意力机制的效率和集中度,降低了计算复杂度。
本文介绍了 Transformer 变体的发展,包括 Transformer-XL 的 segment-level recurrence 和相对位置编码,以及一系列优化复杂度的模型:Explicit Sparse Transformer、Longformer、Switch Transformer、Routing Transformer 和 Linformer。这些模型旨在处理长序列、提高注意力机制的效率和集中度,降低了计算复杂度。

©PaperWeekly 原创 · 作者|上杉翔二
单位|悠闲会
研究方向|信息检索
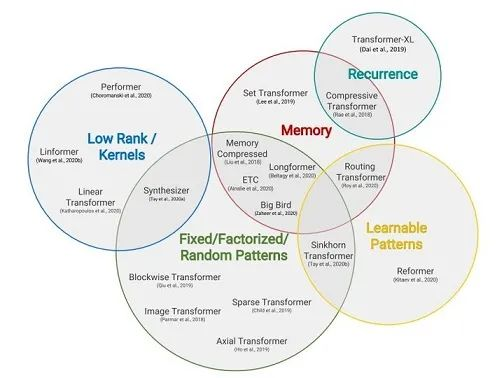
不知不觉 Transformer 已经逐步渗透到了各个领域,就其本身也产生了相当多的变体,如上图。本篇文章想大致按照这个图,选一些比较精彩的变体整理,话不多说直接开始。

Transformer-XL

论文标题:
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
收录会议:
ACL 2019
论文链接:
https://arxiv.org/abs/1901.02860
代码链接:
https://github.com/kimiyoung/transformer-xl
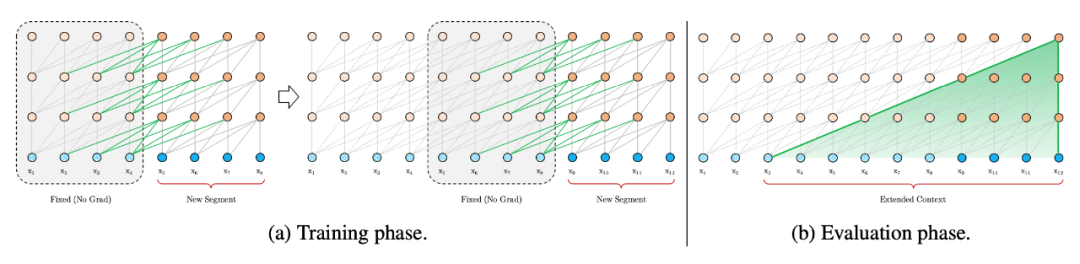
上图上标的是“Recurrence”,首先看看这篇文章聚焦的 2 个问题:
虽然 Transformer 可以学习到输入文本的长距离依赖关系和全局特性,但是!需要事先设定输入长度,这导致了其对于长程关系的捕捉有了一定限制。
出于效率的考虑,需要对输入的整个文档进行分割(固定的),那么每个序列的计算相互独立,所以只能够学习到同个序列内的语义联系,整体上看,这将会导致文档语意上下文的碎片化(context fragmentation)。
那么如何学习更长语义联系?
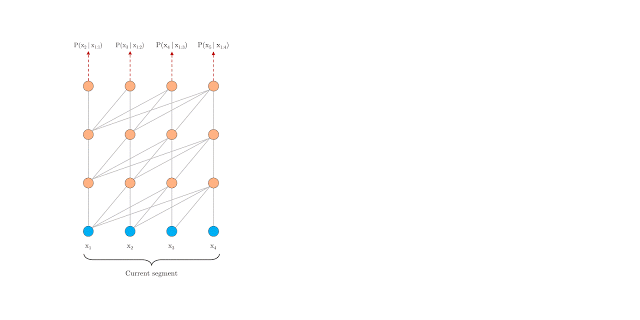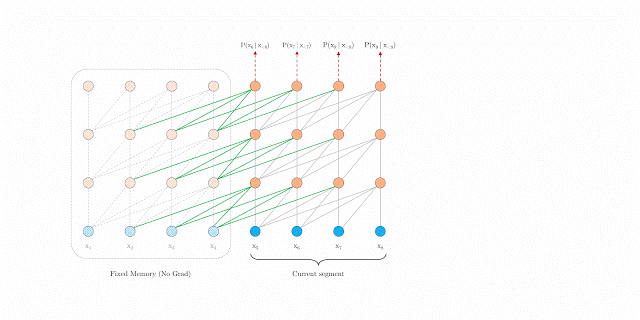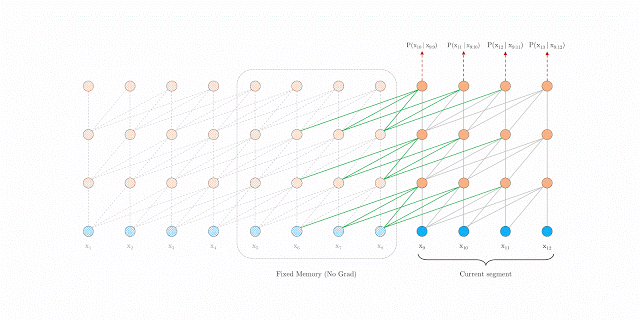
segment-level Recurrence
segment-level 循环机制。如上图左边为原始 Transformer,右边为 Transformer-XL,Transformer-XL 模型的计算当中加入绿色连线,使得当层的输入取决于本序列和上一个序列前一层的输出。这样每个序列计算后的隐状态会参与到下一个序列的计算当中,使得模型能够学习到跨序列的语义联系(看动图可能更好理解)。
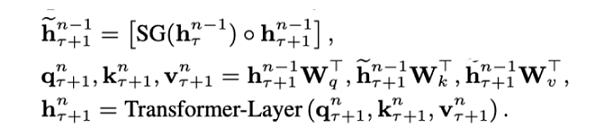
是第 个 segment 的第 n 层隐向量,那么第 r+1 个的第 n 层的隐向量的计算,就是上面这套公式。
其中 SG 是是 stop-gradient,不再对 的隐向量做反向传播(这样虽然在计算中运用了前一个序列的计算结果,但是在反向传播中并不对其进行梯度的更新,毕竟前一个梯度肯定不受影响)。
是对两个隐向量序列沿长度 L 方向的拼接 。3 个 W 分别对应 query,key 和 value 的转化矩阵,需要注意的是!k 和 v 的 W 用的是 ,而 q 是用的 ,即 kv 是用的拼接之后的 h,而 q 用的是原始序列的信息。感觉可以理解为以原始序列查拼接序列,这样可以得到一些前一个序列的部分信息以实现跨语义。
最后的公式是标准的 Transformer。
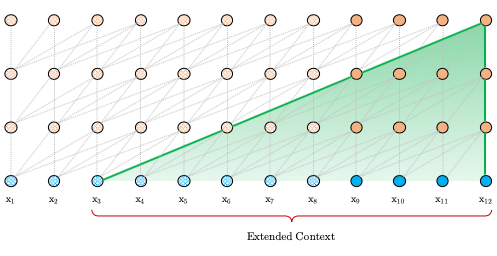
还有一点设计是,在评估预测模型的时候它是会连续计算前 L 个长度的隐向量的(训练的时候只有前一个,缓存在内存中)。
即每一个位置的隐向量,除了自己的位置,都跟下一层中前(L-1)个位置的 token 存在依赖关系,而且每往下走一层,依赖关系长度会增加(L-1),这样能使跨语义更加的深入。
只看看 XL 多头注意力的 forward 的不同地方吧。
def forward(self, w, r, r_w_bias, r_r_bias, attn_mask=None, mems=None):
#w是上一层的输出,r是相对位置嵌入(在下一节),r_w_bias是u,r_r_bias是v向量
qlen, rlen, bsz = w.size(0), r.size(0), w.size(1)
if mems is not None: #mems就是前一些序列的向量,不为空
cat = torch.cat([mems, w], 0) #就拼起来
if self.pre_lnorm: #如果有正则化
w_heads = self.qkv_net(self.layer_norm(cat)) #这个net是nn.Linear,即qkv的变换矩阵W参数
else:
w_heads = self.qkv_net(cat)#没有正则就直接投影一下
r_head_k = self.r_net(r)#也是nn.Linear
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1) #复制3份
w_head_q = w_head_q[-qlen:] #q的W不要拼接的mems
else:#没有mems,就正常的计算
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
klen = w_head_k.size(0)
#qlen是序列长度,bsz是batch size,n_head是注意力头数,d_head是每个头的隐层维度
w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head)  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5537
5537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









