







©作者|朝言
单位|阿里云人工智能实验室
研究方向|计算机视觉
在行人重识别领域,如何获取海量标注数据,提高实际场景的重识别能力是工业界非常关注的一个问题。通常在学术界上公开数据集如 Maket1501 上训练出来的模型在实际场景上基本是没法用的,都需要在实际场景中采集数据并进行标注。标注需要人工成本和时间周期,在项目比较急的时候重新标注根本来不及,因此无监督的行人重识别方法成为了目前研究的一个热点。
无监督行人重识别已经有很多人在研究了,目前最好的方法是 SPCL(葛艺潇:NeurIPS 2020 | 自步对比学习: 充分挖掘无监督学习样本), 在使用了 Generalized Mean Pooling (GEM) 之后,在 Market1501 数据集上达到了 rank-1 89.5% 的效果,效果很好,但是和有监督的方法,如 Resnet50 + Circle loss [1] rank-1 92.13% 或者 OSNet [2] 94.2% rank-1 相比仍然有一些差距。
SPCL 提供了一个很强的 unsupervised reid pipeline,可以启发我们去进行更深一步的探索。基于此,我们提出了无监督 Cluster Contrast ReID,在 Market1501 上跑到了 rank-1 94.6%,已经超越了很多有监督的算法。在其他行人重识别数据集如 Duke 和 MSMT17 数据集上,也比最先进无监督 re-ID 方法 mAP 提高了 7.5%,6.6%。

论文标题:
Cluster Contrast for Unsupervised Person Re-Identification
论文地址:
https://arxiv.org/abs/2103.11568
代码地址:
https://github.com/alibaba/cluster-contrast-reid

方法
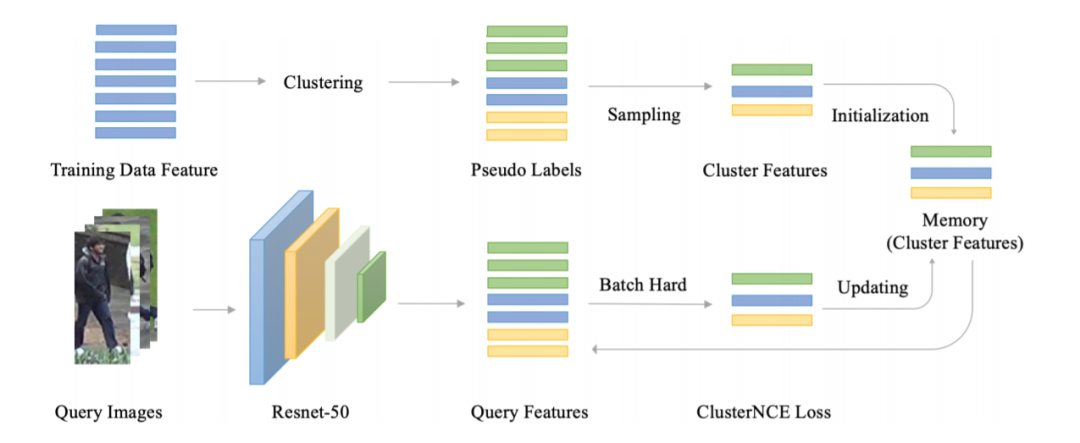
unsupervised reid pipeline
首先来看一下整个无监督 reid 的 pipeline, 大致可以分成三个部分。第一个部分就是特征提取,在每一个 epoch 开始的时候,通过网络将训练数据集中图片的特征都提取出来。第二部分是聚类,通过传统的聚类方法如 DBScan, KNN 通过特征把图片聚成不同的类别,每个类别给一个标签,就是用来训练的伪标签。一开始的伪标签是很不准的,在训练的过程中,随着网络的精度越来越高,伪标签也会越来越接近真实标签。第三部分就是图片特征的存储和更新,在网络训练的过程中,随着网络参数的变化,图片的特征也需要进行对应的更新。
在训练的时候,我们因为有了伪标签,就能够通过类似于 softmax 的分类函数来对网络进行训练。因为伪标签在每次聚类的时候都会发生变化,所以无监督 reid 用的是 non-parametric softmax loss。我们用的是 moco 用的里面的 InfoNCE loss 来进行训练。
我们发现,图片特征的存储和更新对于网络的训练影响很大。一个最简单的直觉就是,在一个行人重识别数据集中,不同的人拥有的图片数量是不一样的,如果按照训练的图片来更新 feature 的话,拥有大量图片的人的 feature 将会滞后更新,从而有害网络优化。
所以 ClusterContrast 的核心思想就是,我们不再是从图片的层面上去更新特征和计算 loss,而是从人的维度去更新和计算 loss。无论一个人有多少张图片,对于网络训练来说,他们都是一视同仁的,都是用同一个速度去更新特征。在无监督 reid 中,每个人都被聚类成一个 cluster,所以我们的方法叫做 ClusterContrast。具体可以参加下图:
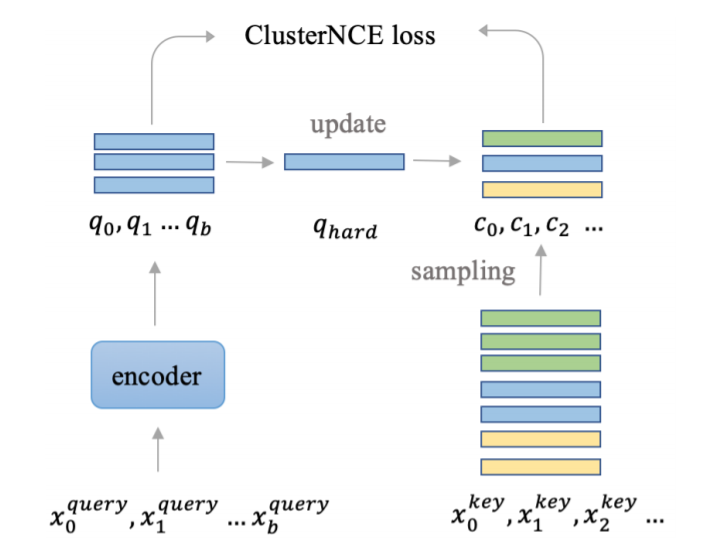
Cluster Contrast
在这张图中,相同颜色的图片是属于同一个人的。对于一个人,不管他有多少张图片,我们只会从里面选一张图片的 feature 存起来。怎么选这一张图片也是有很大的讲究的?就像 batch hard triplet loss 一样,我们发现选择和之前存起来的 feature 最不相似的 feature 效果最好,这样能够让网络去挖掘一些难样本。和之前的方法的对比可以参见下图:
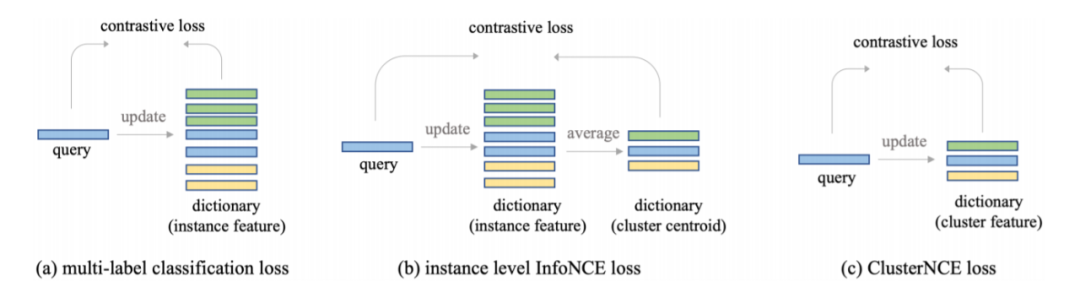
我们可以看到 ClusterContrast 非常简洁,使用了最少的显存,取得了最好的效果。

结果
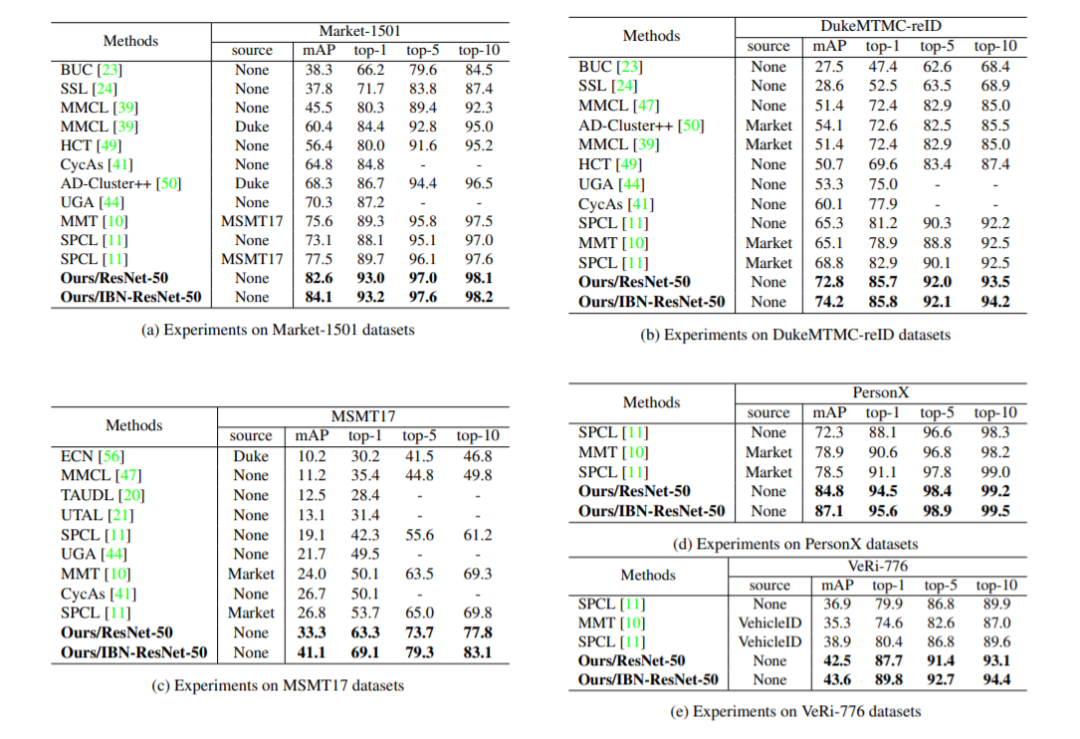
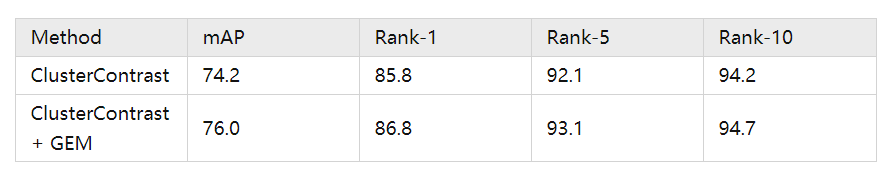
我们在各个数据集上,包括车辆重识别数据集上都大大超越了现有的无监督重识别方法。为了公平比较,我们在图表中并没有使用一些常见的提点方法如 Generalized Mean Pooling (GEM), reranking。用了 GEM 之后网络性能能进一步提升,能够超越很多有监督的方法:
Market1501

DukeMTMC

总结
我们提出了 Cluster Contrast 方法,核心就是在人的维度上去进行特征的提取和更新,从而将特征的更新速度与图片数量进行解耦,让算法工程师能够在 ID 的层面对模型进行调优。Custer Contrast 超越了现有的所有无监督行人重识别方法,无监督域自适应行人重识别方法和相当一部分有监督的方法。Cluster Contrast 简洁且效果好,代码已经开源,希望我们的方法能够带给广大重识别研究者一些启发,让行人重识别更好的落地在实际场景中。

团队招聘
阿里巴巴人工智能实验室 2022 届校园招聘火热进行中。待遇丰厚,成长潜力大,特别优秀的同学可推阿里星,算法开发都要,找工作的同学抓紧投递!

参考文献
[1] https://github.com/layumi/Person_reID_baseline_pytorch#trained-model
[2]. https://kaiyangzhou.github.io/deep-person-reid/MODEL_ZOO
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



















 3104
3104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









