







©作者 | 机器之心编辑部
来源 | 机器之心
来自清华大学的研究者王鑫、陈禹东、朱文武撰写了一篇名为《A Survey on Curriculum Learning》的课程学习综述论文,该论文已被TPAMI 2021收录,本文对其展开介绍。

原文地址:
https://ieeexplore.ieee.org/document/9392296
论文地址:
https://arxiv.org/pdf/2010.13166.pdf
课程学习是一种训练策略,它模仿了人类课程中有意义的学习顺序,从较容易的数据开始训练机器学习模型,并逐步加入较难的数据。课程学习策略作为一个易于使用的插件,在计算机视觉和自然语言处理等广泛的场景中,提高了模型的泛化能力和收敛速度。
本文从动机、定义、理论和应用等各个方面全面回顾了课程学习。研究者在一个通用的课程学习框架中讨论课程学习方法,详细阐释如何设计一个预定义的课程或自动的课程。具体来说,研究者基于 “难度评分器 + 训练调度器” 的总体框架,总结了现有的课程学习设计,并进一步将自动课程学习的方法分为四类,即自步学习、基于迁移教师的课程学习、基于强化教师的课程学习、其他自动课程学习。最后,研究者简要讨论了课程学习与机器学习概念的联系,并指出了未来值得进一步研究的潜在方向。
绪论
课程学习(Curriculum Learning)是一种模仿人类课程的训练策略,它一开始在较简单的数据子集上训练模型,并逐渐拓展到更大更困难的数据子集,直到在整个数据集上训练。这种 “由易到难” 的训练策略在人类教育中很常见,例如,一个孩子要从最简单的加减乘除概念入手,逐步学习方程、求导等,才能学会微积分。然而,传统机器学习算法往往采用随机的训练数据,忽略了样本的难度与模型的当前状态。课程学习正是希望从 “设计一个更好的训练课程” 的角度,改进机器学习的训练策略。
一个课程学习的例子如图 1 所示。以图像分类为例,训练初始阶段,课程学习算法在一个更简单(清晰、典型、易识别)的数据子集上训练模型;随着训练的进行,算法逐渐加入了更多更困难(较复杂、难识别)的图像样本到当前训练集中,这就好比人类课程里学习材料难度的增加;最后,算法在完整的原始训练集上进行训练。

图 1:课程学习概念示意图
理论推导和广泛的实践证明,好的课程学习算法可以带来更佳的模型表现,以及更快的收敛速度。例如,[1]中的课程帮助神经机器翻译模型在减少 70% 训练时间的同时提升了 2.2 的 BLEU 分数,[2]中的课程相比常规批(batch)训练,在多媒体事件检测任务中相对提升了 45.8% 的 MAP 分数并显著加速收敛。为了填补系统性课程学习综述的空缺,本文总结了课程学习的主要方法,并回答了如下问题:(1)课程学习如何定义?(2)为何课程学习有效,以及为何要用课程学习?(3)如何设计一个课程?(4)课程学习与其他机器学习概念的关系?(5)课程学习可能的未来发展方向?
课程学习的定义
课程学习的概念最早由 Bengio 提出[3],其形式化定义如下。
课程学习。一个课程是指在 T 步机器学习训练过程中的一系列训练标准:C=<Q_1,…,Q_t,…,Q_T>,其中每个标准 Q_t 是训练分布 P(z)的一个重新加权,即 Q_t(z)∝W_t(z)P(z),z=(x,y)是训练集 D 中的任一样本,且 Qt 满足以下三个条件:
(1)当前训练集的熵会不断增加,即 H(Q_t)<H(Q_(t+1));
(2)任意一个样本的权重会不断增加,即:W_t(z)≤W_(t+1)(z);
(3)Q_T(z)=P(z)。
课程学习即使用这样的课程训练机器学习模型的一种训练策略。
上述的三个条件具有如下的含义:条件(1)意味着当前训练集的多样性和信息量在增加,也即训练后期的时候Q_t会增大采样更困难样本的权重;条件(2)说明训练集中的样本数在不断增加;条件(3)说明最终算法将在完整训练集里均匀采样用于训练。本文归类的预定义课程学习、自步学习、基于迁移教师的课程学习符合上述定义。
在课程学习的文献中,上述定义的三个约束条件(1)(2)(3)有时会被舍弃,得到数据级别广义课程学习的定义:训练分布 P(z)的一个重新加权序列。此时课程学习的定义事实上涵盖了样本选择与重新加权,即在每轮训练中动态调整训练样本的采样策略或样本权重。本文归类的基于强化教师的课程学习以及多种其他自动课程学习方法符合此定义。
除此之外,部分课程学习文献进一步舍弃了 “训练标准 Q_t 必须是训练数据重加权” 的限制,采用了广义课程学习的定义:一个训练标准的序列。这里的训练标准可以采用损失函数、监督信号的生成、模型容量等。这些文献进一步拓宽了课程学习思想所涉及的范畴。
课程学习的有效性分析与适用场景
课程学习的理论分析主要从优化的角度和数据分布的角度分析了课程学习在提升模型测试集表现和收敛速度为何有效。从优化角度,课程学习是连续法(continuation method)的一个特例,它在初始阶段松弛了优化目标并逐渐收紧,这有利于模型逃离较差的局部最优点。从数据分布角度,课程学习是一种去噪的策略,这是由于在大数据场景中,困难样本往往包含更多噪声,因此由易到难的策略可以缓解模型在初始学习阶段受到的噪声干扰。
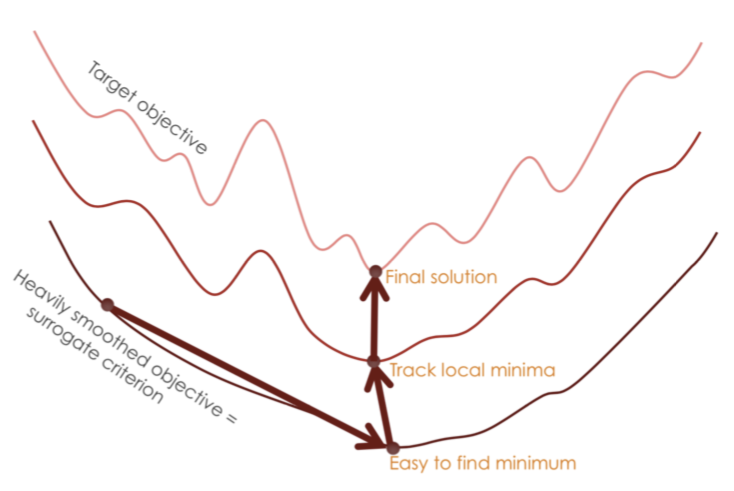
图 2:课程学习是一种特殊的连续法
基于上述理论分析的两个角度,课程学习的适用场景可以包含计算机视觉[]、自然语言处理、强化学习、多任务学习等广泛的任务。从监督信息的视角而言,课程学习被广泛应用于监督学习、弱监督(或半监督)学习和无监督学习任务。

表 1:课程学习的主要作用及其对应的常见适用场景
课程学习方法的基本类别
由课程学习的定义,本位提出设计一个 “课程” 的两个关键模块:(1)难度评分器,用于决定什么样本更简单(或者什么样本更适合当前的采样);(2)训练调度器,用于决定何时增加多少更困难的样本到当前训练集。依据这两个模块设计的不同,本文把主流的课程学习方法归结为如下的四类:预定义的课程学习、自步学习、基于迁移教师的课程学习、基于强化教师的课程学习(以及一些其他的自动课程学习方法),示意图如图 3(a)~(d)所示。
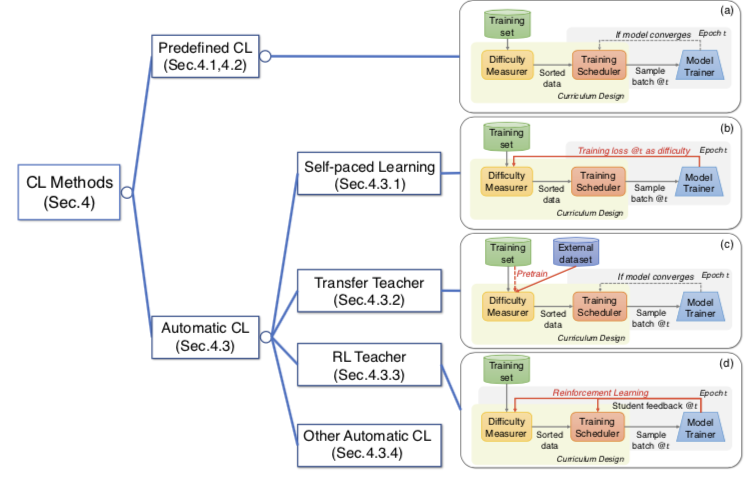
图 3:课程学习方法的基本类别示意图
预定义的课程学习
此类课程完全由人类专家的先验设计得到,而不采用任何数据驱动的算法和模型来决定课程的两个模块,也不动态调整(图 3(a))。与之相对应的概念是自动课程学习,即采用了数据驱动的算法和模型来决定难度评分器、训练调度器中的任何一个的设计(图 3(b)~(d))。
预定义的难度评分器主要从复杂度、多样性、噪声估计等角度,利用特定领域的知识来评判样本的难度。例如,从单个样本的复杂度角度,机器翻译中更长的句子对常被认为是更困难的训练样本[1][4],而图像语义分割任务中物体数目更多的图片会更困难[5];从一组数据的分布多样性角度,机器翻译中含有更多更生僻的单词的句子会被认为更困难[6];从样本的噪声估计角度,语音识别中的信噪比越低的样本会被认为更困难[7]。也有文献利用其它领域知识(如医学等)来预定义难度评分器。
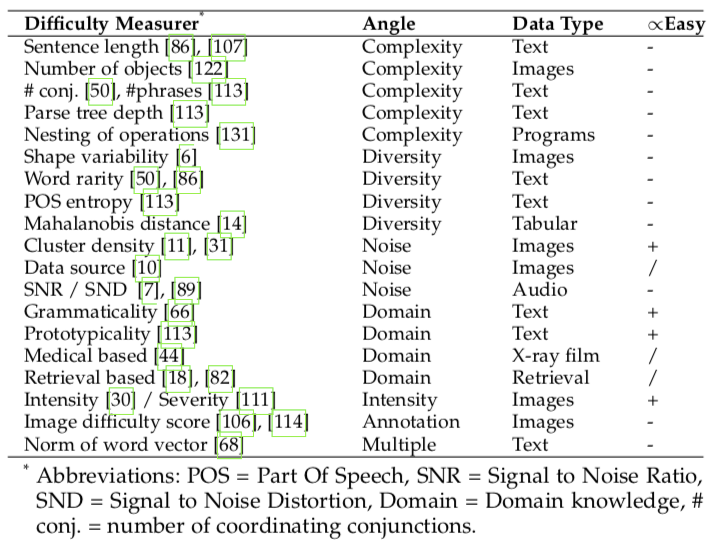
表 2:预定义的难度评分器
预定义的训练调度器本质是一个函数 h(t),将当前的训练轮数 t 映射为一个比例λt,表示先按照难度评分器的打分将训练集样本由易到难排序后,在第 t 轮将选择λt 比例的最简单的样本作为当前采样的训练集。最典型的训练调度器为 “小步前进(Baby Step)” 调度器,它首先将按照难度排序后的样本分为 K 个桶,首先在第 1 桶样本上采样训练固定的轮数或至模型收敛,然后将第 2 桶更困难的样本加入训练集训练,以此类推,直到把所有样本加入当前训练集。还有另一类连续调度器,它们利用线性或根式函数曲线作为 h(t),在每一轮都按照λ_t 往训练集里加入更多更困难的样本。相比离散的小步前进调度器,连续调度器往往能取得更好的效果。
预定义的课程学习存在许多局限性,最主要的局限性包括:(1)忽略了模型的状态和反馈,导致算法不够灵活,无法根据数据和模型动态调整以达到更好的效果;(2)需要人为决定样本难度,不仅耗时、不在更广的领域普适,且人工认定的难度并不一定有利于模型的学习。为弥补这些局限性,学者们提出了多种自动课程学习方法。
自步学习
自步学习(Self-paced learning)[8]让机器学习模型本身作为难度评分器,将当前模型损失较高的样本作为更困难的样本。这种策略与人类自学很相似:学生可以根据自己的学习进度(模型状态)来调整自己的学习节奏(先学更简单的学习材料)。自步学习是一个相对独立的研究领域,这里本文把它归类为自动课程学习的一大类方法。自步学习的形式化定义如下:
自步学习赋予每个样本 (x,y) 一个损失权重 v,并优化下列目标函数:
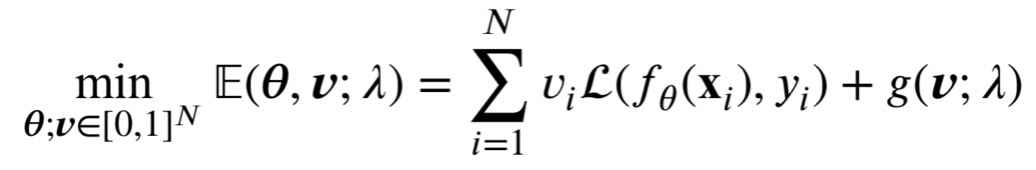
其中 N 为训练集样本数,θ是机器学习模型 f 的参数,L 是损失函数,λ是一个动态调整的阈值,每轮训练都会增大一点。g(v; λ)是对于样本权重向量 v 的正则化项,用于自动调控不同样本的权重。
自步学习算法通常采用交替优化策略,每轮先固定θ优化 v(这一步通常可以直接计算解析解),再固定 v 优化θ。
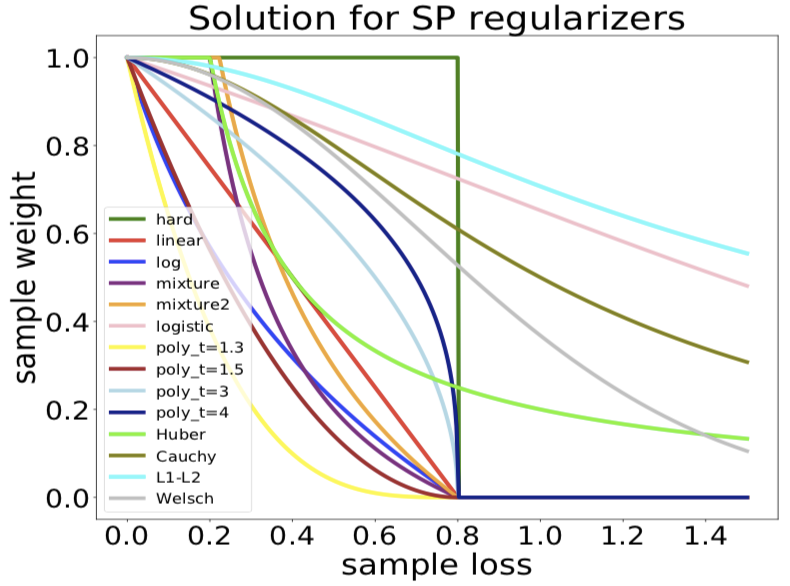
图 4:不同正则项 g(v; λ)设计下,自步学习中样本损失(横轴)与样本权重(纵轴)的函数关系图
随着自步学习方法的发展,更多的 g 被设计出来,使得样本加权的策略 v 更加灵活多样,以适应于不同的应用需求[9-11]。也有工作引入一些先验知识到自步学习中,使得模型对于样本难度的判断更加准确,以达到更好的效果[12-14]。自步学习被广泛应用于计算机视觉、传统机器学习等领域。
基于迁移教师的课程学习
此类方法用一个较强大的教师模型作为难度评分器,教师模型预先在当前数据集或其他大规模数据集预训练好,并将它的知识迁移到学生模型(即待训练的机器学习模型)的课程设计中。相比自步学习,这类方法弥补了 “训练初始阶段机器学习模型本身尚不成熟,导致难以判断难度” 的缺陷,转而选用一个成熟的教师模型来评估样本的难度。在训练调度器上,此类方法与自步学习相同,依旧采用预定义的训练调度器。
相比待训练的学生模型,教师模型既可以是一个更复杂的模型,也可以与学生模型相同。例如,Weinshall 等 [15] 采用了一个复杂的深度模型作为教师模型,在 ImageNet 上对其进行预训练后,再固定其参数,计算它在每个训练样本上的预测损失,作为课程设计的依据。Hacohen 等 [16] 则采用了与学生模型相同的教师模型,在同一个训练集上对其做预训练后,计算它在训练样本上的损失。
基于强化教师的课程学习
此类方法采用强化学习框架作为教师,以基于学生模型的反馈来动态选择训练数据(或决定训练数据权重)。此类方法属于数据级别广义课程学习方法,它模拟了人类教育中最理想的 “教学相长” 现象:学生基于教师为其量身定制的学习材料而获得最大的进步,同时教师也可以通过学生的反馈来动态调整教学策略,提升教学水平。
从思想上,强化学习框架的要素在课程学习中的对应如下:强化学习的动作即为在训练集里挑选数据(或给予数据权重);强化学习的状态为学生模型当前的状态反馈、以及其他训练状态信息(如训练轮数);强化学习的奖励可根据优化目标定义为与学习效率或效果有关的函数(如模型在验证集上的准确率增量)。基于这样的框架,传统强化学习算法(如多臂老虎机)[17-19]和深度强化学习算法 [20-21] 均被用于动态生成数据选择的课程,以达到多种不同的奖励最大化。相比其他的课程学习方法,此类方法的设计更具灵活性,但其缺点在于深度强化学习框架计算开销大,且较难训练。
课程学习的相关讨论
(1)实战中如何设计一个课程。本文总结了现有文献课程学习算法设计的一些实践经验与规律,讨论了不同课程学习类别混合使用的方法与原则,以及不同类别课程学习算法所带来的额外计算复杂度。
(2)“由易到难”v.s.“由难到易”。与狭义课程学习的 “由易到难” 思想相反,还有一系列研究关注困难样本挖掘对于机器学习的帮助,这类文章提倡每轮训练都选取最困难的样本进行学习。事实上,困难样本挖掘属于数据级别广义课程学习的范畴。理论上,狭义课程学习与困难样本挖掘两种策略均可以在不同场景辅助提升模型性能。
(3)课程学习与其他机器学习模式的联系。本文从数据分布的视角对比和阐释了课程学习与传统机器学习、迁移学习、多任务学习、元学习、持续学习、主动学习等机器学习概念的联系,其对比示意图如图 5 所示。
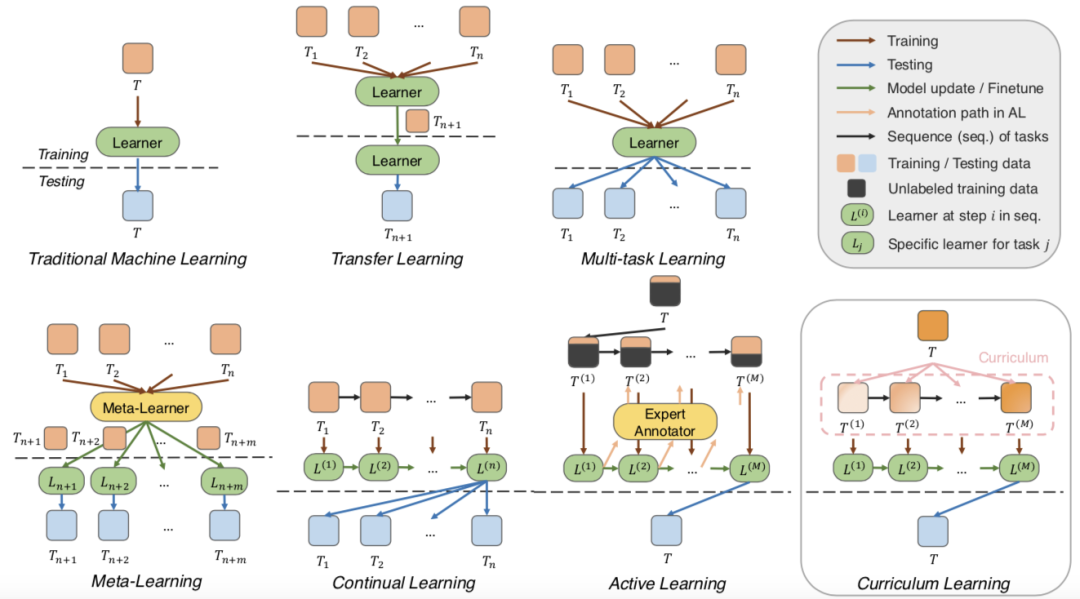
图 5:课程学习与其他机器学习模式的联系示意图
课程学习的未来方向
(1)评价基准
目前还很少有工作利用一套统一的基准来评价不同的课程学习算法。由于应用范围广泛,现有课程学习工作采用的数据集与评价指标较为多样。制作一套统一的课程学习算法评价基准面临如下挑战:①构建具有不同稀疏度、异构性、噪声级别的数据集;②设定统一的模型效果和收敛速率的评价指标;③构造 “真实值课程” 以比较不同的算法构建出的课程。
(2)更多的理论探究
例如:如果数据没有噪音,课程学习算法是否有效?原始课程学习定义中三个条件各自的实际效果是什么?自动课程学习方法是否也具备理论保障?更本质的理论研究还包括揭示数据分布、任务目标与最优训练策略之间的关联。
(3)更多的课程学习算法设计以及更广泛的应用场景
自动课程学习将是未来的一个重要研究方向,它的本质是对 “课程” 进行优化,因此,课程学习算法的改进可以考虑引入更多优化算法(如 bandit 算法、元学习、超参优化等)以及优化目标(如数据权重、损失函数、模型假设空间等)。同时,课程学习也可以被应用与更加广泛的前沿场景问题中(如元学习、持续学习、图神经网络学习、自监督学习等),以寻求更多的突破。
参考文献:
[1] E. Platanios, et al. Competence-based curriculum learning for neural machine translation. In NAACL-HLT, 2019.
[2] L Jiang, et al. Self-paced learning with diversity. In NeurIPS, 2078–2086, 2014.
[3] Y. Bengio, et al. Curriculum learning. In ICML, 41–48, 2009.
[4] V. Spitkovsky, et al. From baby steps to leapfrog: How “less is more” in unsupervised dependency parsing. In NAACL-HLT, 751–759, 2010.
[5] Y. Wei, et al. Stc: A simple to complex framework for weakly-supervised semantic segmentation. TPAMI, 39(11):2314–2320, 2016.
[6] T. Kocmi, et al. Curriculum learning and minibatch bucketing in neural machine translation. In RANLP, 2017.
[7] S. Ranjan, et al. Curriculum learning based approaches for noise robust speaker recognition. TASLP, 26(1):197–210, 2017.
[8] M. Kumar, et al. Self-paced learning for latent variable models. In NeurIPS, 1189–1197, 2010.
[9] L Jiang, et al. Easy samples first: Self-paced reranking for zero-example multimedia search. In MM, 547–556, 2014.
[10] Q. Zhao, et al. Self-paced learning for matrix factorization. In AAAI, volume 3, page 4, 2015.
[11] C. Xu, et al. Multi-view self-paced learning for clustering. In IJCAI, 2015.
[12] L Jiang, et al. Self-paced learning with diversity. In NeurIPS, 2078–2086, 2014.
[13] L Jiang, et al. Self-paced curriculum learning. In AAAI, volume 2, page 6, 2015.
[14] D. Zhang, et al. Leveraging prior-knowledge for weakly supervised object detection under a collaborative self-paced curriculum learning framework. IJCV, 127(4):363–380, 2019.
[15] D. Weinshall, et al. Curriculum learning by transfer learning: Theory and experiments with deep networks. In ICML, 2018.
[16] G. Hacohen, et al. On the power of curriculum learning in training deep networks. ICML, 2019.
[17] A. Graves, et al. Automated curriculum learning for neural networks. ICML, 2017.
[18] T. Matiisen, et al. Teacher-student curriculum learning. TNNLS, 2019.
[19] Y. Fan, et al. Learning to teach. ICLR, 2018.
[20] G. Kumar, et al. Reinforcement learning based curriculum optimization for neural machine translation. In NAACL-HLT, 2019.
[21] M. Zhao, et al. Reinforced curriculum learning on pre-trained neural machine translation models. In AAAI, 2020.
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



















 3655
3655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









