








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
自 SimCLR [1] 在视觉无监督学习大放异彩以来,对比学习逐渐在 CV 乃至 NLP 中流行了起来,相关研究和工作越来越多。标准的对比学习的一个广为人知的缺点是需要比较大的 batch_size(SimCLR 在 batch_size=4096 时效果最佳),小 batch_size 的时候效果会明显降低,为此,后续工作的改进方向之一就是降低对大 batch_size 的依赖。那么,一个很自然的问题是:标准的对比学习在小 batch_size 时效果差的原因究竟是什么呢?
近日,一篇名为 Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE 对此问题作出了回答:因为浮点误差。看起来真的很让人难以置信,但论文的分析确实颇有道理,并且所提出的改进 FlatNCE 确实也工作得更好,让人不得不信服。

论文标题:
Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE
论文作者:
Junya Chen, Zhe Gan, Xuan Li, Qing Guo, Liqun Chen, Shuyang Gao, Tagyoung Chung, Yi Xu, Belinda Zeng, Wenlian Lu, Fan Li, Lawrence Carin, Chenyang Tao
论文链接:
https://arxiv.org/abs/2107.01152

细微之处
接下来,笔者将按照自己的理解和记号来介绍原论文的主要内容。对比学习(Contrastive Learning)就不帮大家详细复习了,大体上来说,对于某个样本 x,我们需要构建 K 个配对样本 ,其中 是正样本而其余都是负样本,然后分别给每个样本对 打分,分别记为 ,对比学习希望拉大正负样本对的得分差,通常直接用交叉熵作为损失:
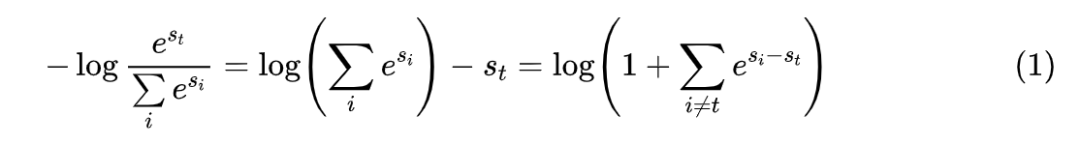
简单起见,后面都记
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









