







©作者 | 曲昌博
单位 | 西蒙菲莎大学

近日,IEEE 数据工程新星奖王健楠团队论文《Are We Ready for Learned Cardinality Estimation?》夺得数据库顶会 VLDB 2021 年度的 EA&B 最佳论文奖。
数据库是企业管理和查询数据的复杂软件系统。
近年来随着机器学习以及深度学习方面技术的进步以及在其它领域内被成功应用的先例,ML for DB 这个课题变得越来越火,但是大多数方法尚局限于学术圈的探索阶段。
如果把目光放到 5-10 年之后的该课题的发展,一种可能性是大家发现这些模型并不能被真正的使用在生产环境中,从而渐渐的对这个课题失去兴趣。
而另一个可能的结果是主流的数据库系统正式开始采用这些机器学习模型,并且性能有了很大的提升。
因此回答「能否把基于 ML 的某模块 X(Learned X)落地于数据库产品中?」这个问题至关重要。
近期,SFU(西蒙菲莎大学)的数据库团队发表了一篇实验分析论文,从「Cardinality Estimation(基数估计)」这个角度对问题进行了回答。
论文发表于数据库顶级会议 VLDB 上,并获得会议的 EA&B (Experiment, Analysis and Benchmark) 最佳论文。

论文标题:
Are We Ready For Learned Cardinality Estimation?
论文链接:
http://www.vldb.org/pvldb/vol14/p1640-wang.pdf
Github:
https://github.com/sfu-db/AreCELearnedYet

引言
数据库优化器(Query Optimizer)是数据库最重要的模块之一,他决定了 SQL 语句的查询计划(Query Plan)的选择,并直接影响甚至决定查询速度。
简单来说,基数估计(Cardinality Estimation)的目的是在不用执行 SQL 查询的情况下,预测查询可能返回的行数。
例如:一个简单的 SQL 语句:
SELECT * FROM DB WHERE A = 1;
基数估计就是在估计下列查询的结果:
SELECT COUNT(*) FROM DB WHERE A = 1;
查询优化器使用基数估计结果来生成最佳查询计划。通过更准确的估计,查询优化器通常可以更好地生成更优查询计划。
但是基数估计却是数据库优化器的「阿喀琉斯之踵」,也是本文的研究重点。这个问题已经被研究了超过三十年,却依旧没有被完全解决。
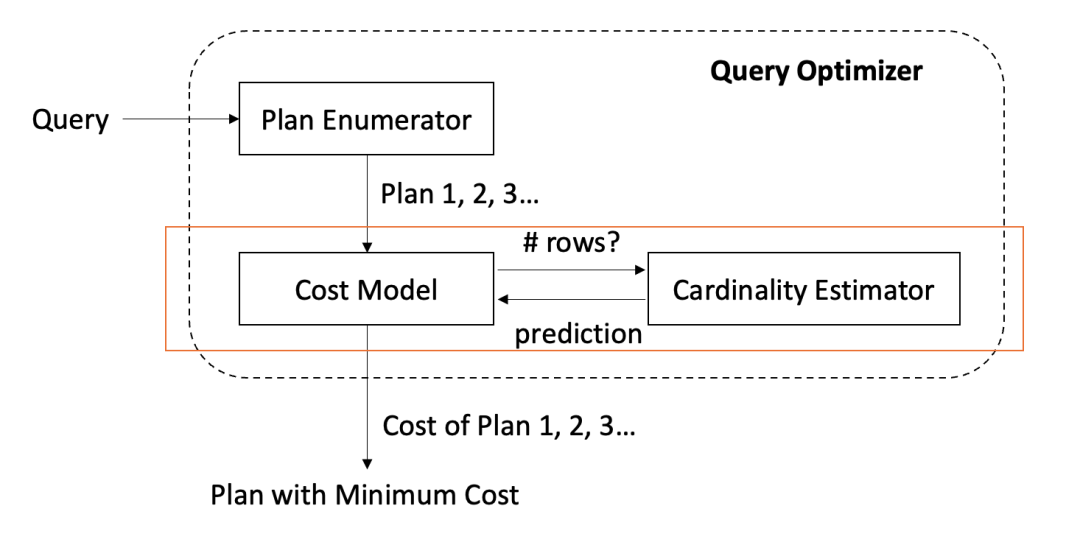
Query Optimizer的原理

研究目的和贡献
近年来,有越来越多的研究开始采用机器学习或深度模型学习来预测基数,并且在准确度上展现了超越传统数据库中基数估计方法的极大潜能。
但是,能否把 Learned Cardinality Estimation 方法应用到数据库的生产环境中?
答案并不明确。
为此,本文从三个角度回答了上面提出的问题:
1. Are Learned Methods Ready For Static Environments?
2. Are Learned Methods Ready For Dynamic Environments?
3. When Do Learned Methods Go Wrong?
本文全面比较了近年来 Learned Cardinality Estimation 方法。统一了不同方法的实验环境,详尽的回答了以上问题,并指出了未来的研究方向。

主要实验
3.1 实验方法分类
本文调研了近年来发表在数据库顶级会议中的 7 种机器学习方法,并把这些方法分为两类:
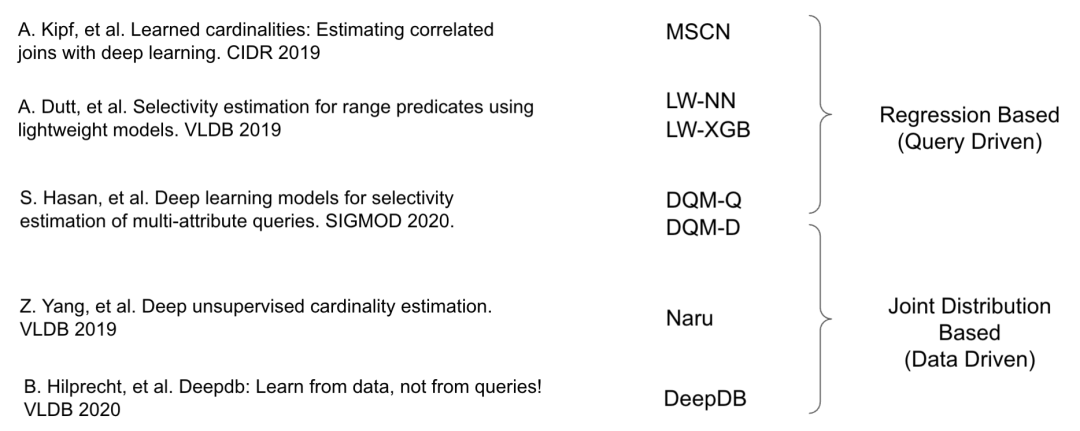
Learned Cardinality Estimation 方法分类
(1)Query Driven (Regression) Models: 这类方法把基数估计问题理解为回归问题,通过建立回归模型预测基数。
在训练集中,把特征化的 SQL 语句和其查询结果分别作为特征和标签,从而获得模型。在预测时,输入特征化的 SQL 语句即可获得预测的结果。
(2)Data Driven (Joint Distribution) Models: 这类方法把基数估计理解为对数据本身的联合概率分布的估计。
在训练时,估计数据的联合概率分布。在预测时,SQL query 是针对该分布的查询,从而给出预测结果。
3.2 数据集的选择
由于现有的不同的方法,在不同的数据集上进行比较,没有统一标准。本文选择了 4 个真实数据集,他们大小、行数、列数均不相同,且至少被上述论文引用一次。

数据集具体信息
3.3 查询生成框架
由于不同的论文用不同的方式生成查询,本文综合考虑后,提出了统一的生成框架。(# predicate 是 SQL where 中的断言数量,Operators 是 where 中是否考虑了“=”和“区间”,OOD 是指查询是否会查数据中不存在的数据)。
其中,统一的 test set 是 10K 个查询。对于 Query Driven Models,training set 的大小是 100K。
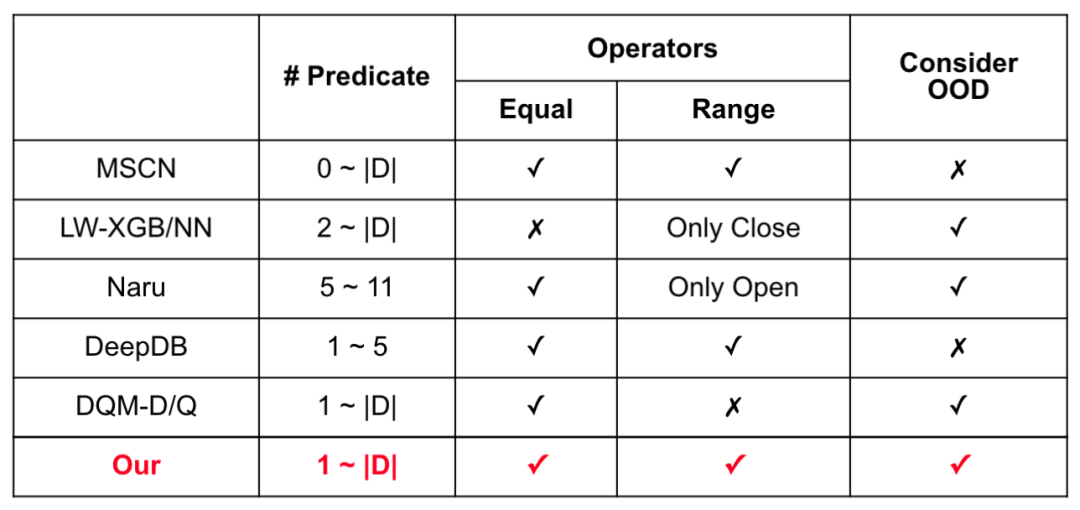
查询负载的区别
3.4 实验度量(metric)
实验中采用基数估计常用的 metric——Q_error。
也就是实际值和估计值的最大值和最小值的比。越接近 1,说明估计越准确。
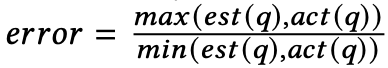
Q_error

Are Learned Methods Ready For Static Environments?
作者在静态环境(数据库中的数据不更新)中从准确度以及效率(包括训练时间和推断时间)两个方面对基于学习的基数估计方法以及传统方法进行了比较。
本文选取了 3 个广泛应用的数据库产品和 6 个常用以及最新的传统基数估计方法作为基准。
并且选择了上述 4 个常用的且具有不同属性的数据集和统一的查询负载生成框架,并通过它来生成需要的训练和测试集。
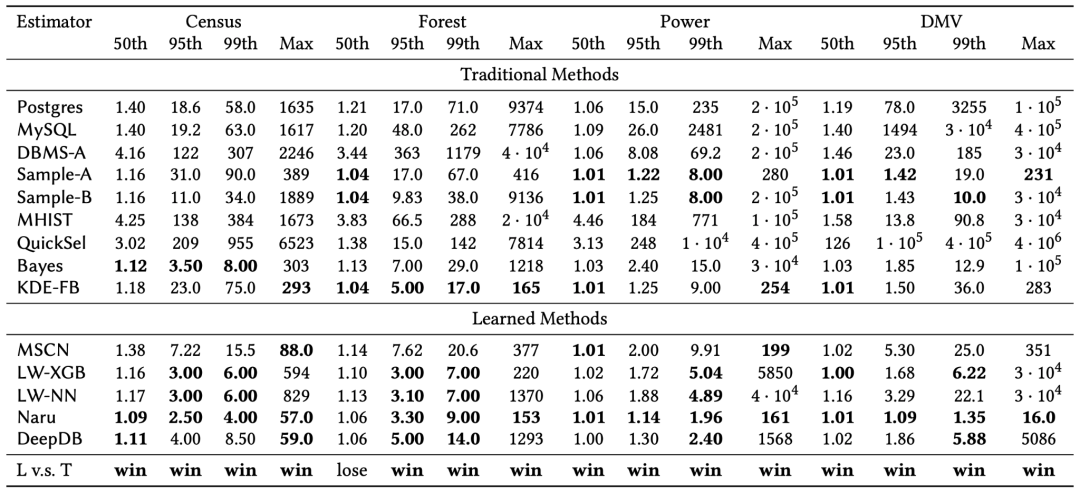
准确度比较(Error越小越好)
现象:
1. Naru 的准确度是最好的;
2. 最新的机器学习方法整体比传统方法更准确。
4.1 训练时间比较(以 Power 数据集为例)
下图展示了不同方法完成训练所需要的时间。
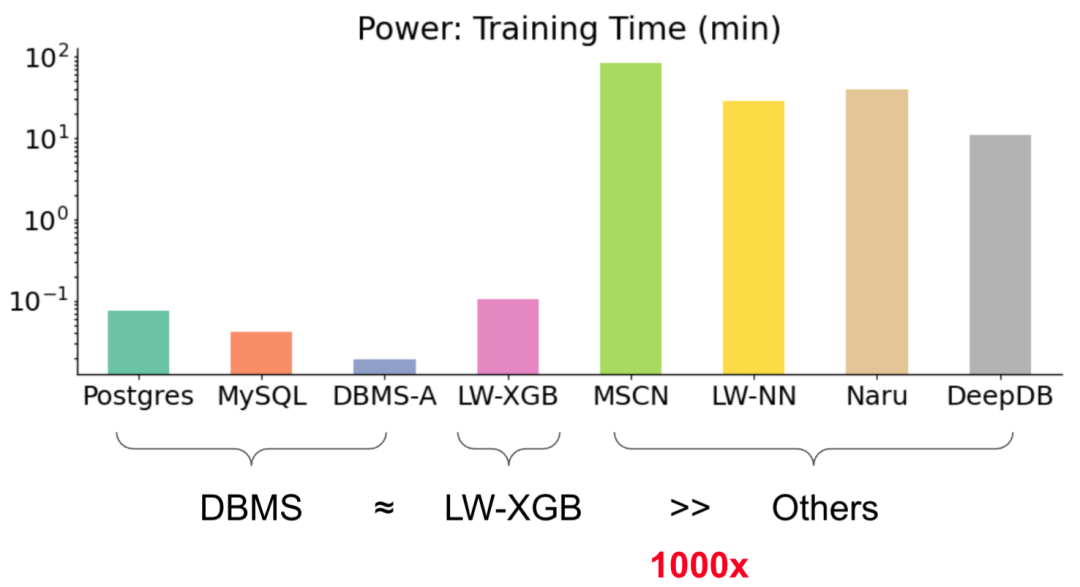
训练时间的差异
现象:
所有的数据库,都可以在几秒内完成统计信息的更新,而机器学习方法中,只有 LW-XGB 有可比性,其余的甚至可以慢到 1000 倍以上。
4.2 推断时间比较(以Power数据集为例)
下图展示了不同方法,平均完成一次推断所需要的时间。
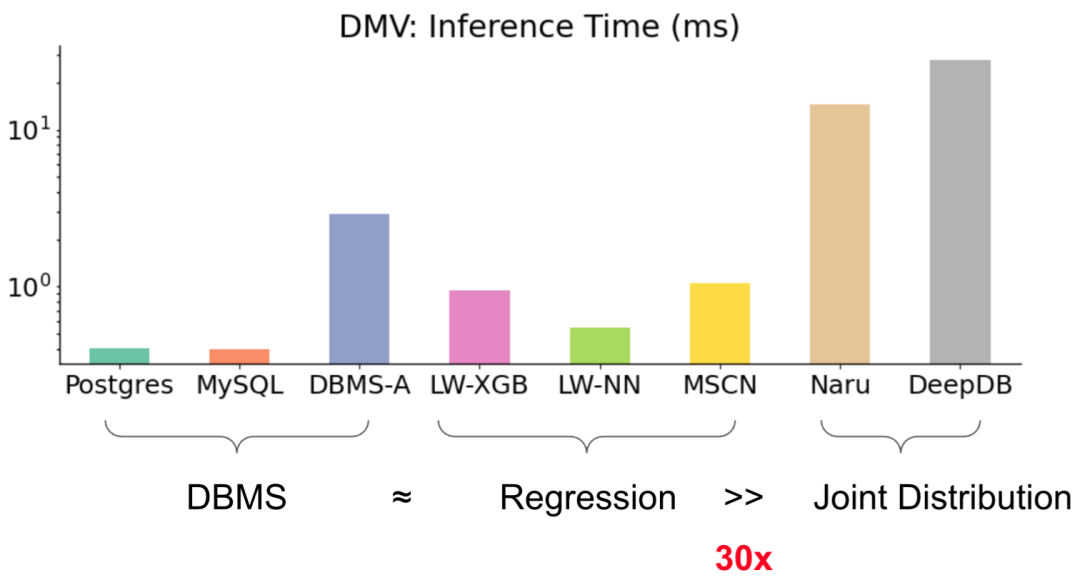
预测时间的差异
现象:
所有的数据库,都有毫秒级的响应速度,而机器学习方法中,只有 Regression 方法有可比性,其余的可以慢 30 倍以上。
主要结论:基于机器学习的方法在准确率上相比于传统方法有比较大的提升。然而相比于传统方法,除了 LW-XGB 以外,机器学习方法需要更多的时间去训练模型,同时在模型运行的时候也会更慢。

Are Learned Methods Ready For Dynamic Environments?
在现实的生产环境中,数据库中的数据是会经常发生变化的。
设计本实验的难点是需考虑数据更新带来的多方面变化:
1. 数据方面
(1)数据的更新频率;
(2)数据的变化。
2. 模型方面
(1)不同模型的更新方式;
(2)模型更新花费的时间;
(3)在模型更新前后的准确率有变化的情况下,综合地测量准确率。
因此,本文在实验的第二部分中设计并引入了一个动态的框架来更加公平的比较机器学习方法和现有的数据库产品。部分结果如下:
当我们设定数据更新频率较高时,检测模型能否完成更新,结果如下图:
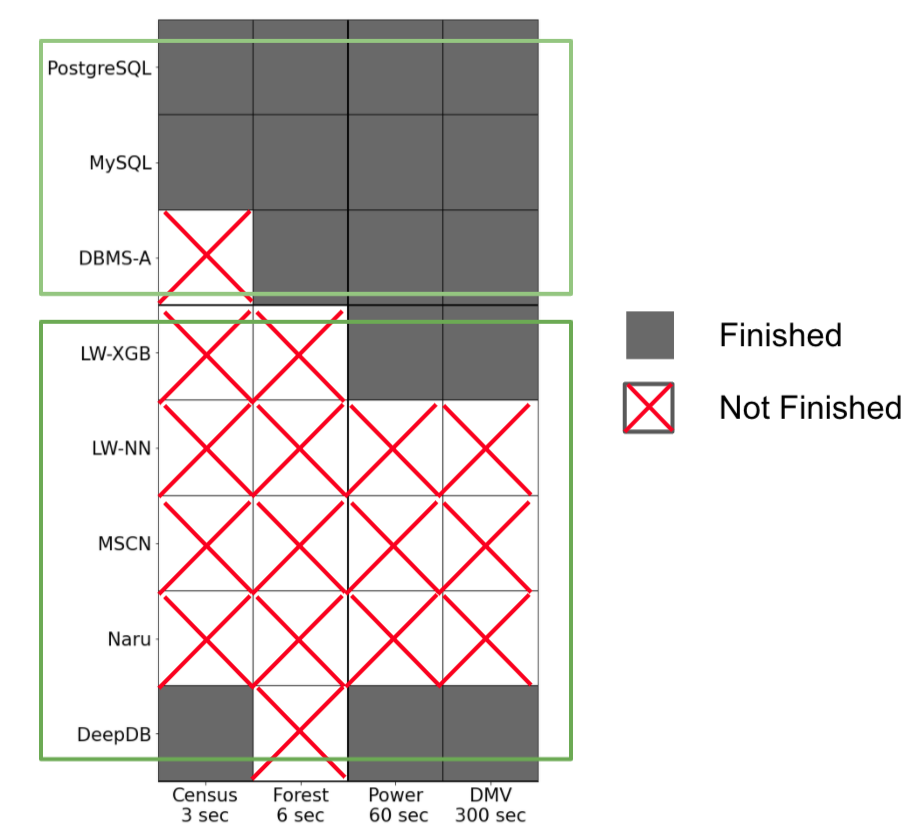
限定模型更新时间时,能否完成更新
现象:当更新频率较高时,大多数机器学习方法不能跟上频繁的更新,而大多数情况下,数据库都可以完成更新。
当我们设定数据更新频率特别低,并保证所有的机器学习方法都可以完成更新时,比较不同方法的准确度排序(1 最好,5 最差),结果如下图:
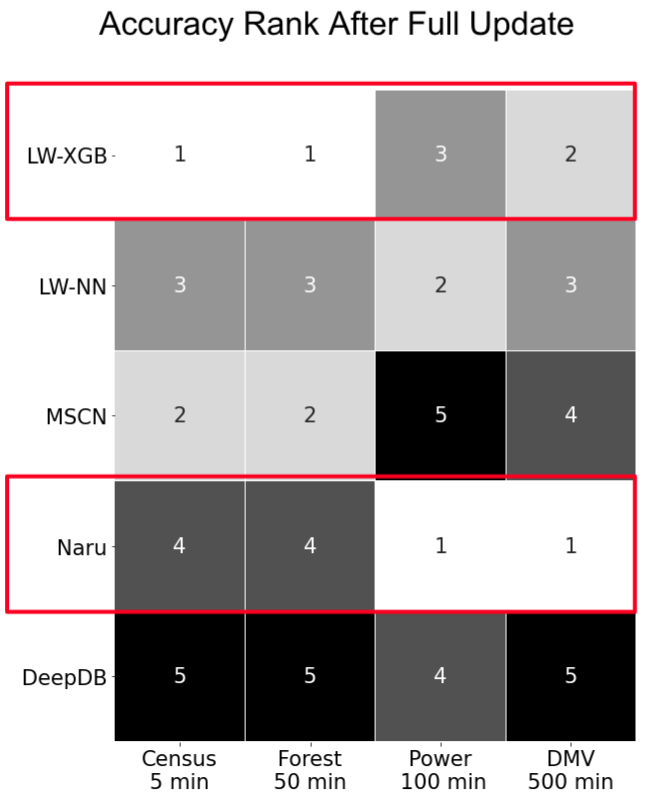
现象:当所有的机器学习方法都可以完成更新时,没有哪个方法可以在不同数据集上始终最好。
主要结论:机器学习方法需要更久的时间去更新模型,因此往往会跟不上数据更新的速度。与此同时,不同机器学习方法的估计误差在不同的数据集上有所差异,并没有一个显著的最优方法。

When Do Learned Methods Go Wrong?
机器学习和深度学习模型相较于传统启发式方法的一个劣势在于他们相对来说更难被人直观的理解和解释。
这也导致很难预估他们什么时候会表现不好,从而导致用户难以真正的信任和使用它们。
作者还发现了一些模型的不符合逻辑的行为,举例如下:
1. 估计结果不单调。如下两个查询:

可见,Q1 的查询范围大于 Q2,所以符合逻辑的结果应该是 Q1 的估计结果 >= Q2 的估计结果。然而,在实际实验结果中,Q2 却比 Q1 大了超过 60%。
2. 估计结果不稳定。同一个查询,重复执行 2000 次的分布图如下:
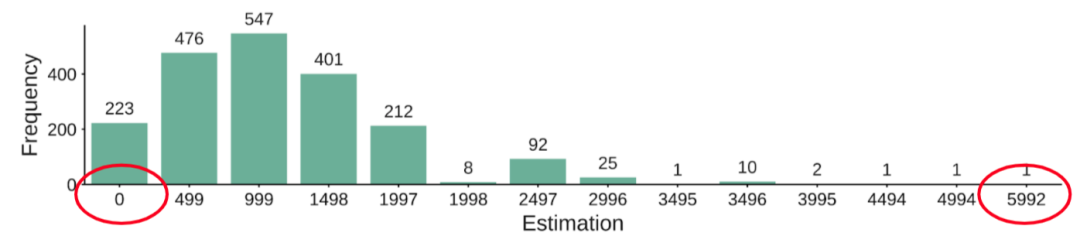
同一个查询的估计结果范围从 0 到 6000,这样的估计结果会导致系统的表现不稳定,从而影响人们对系统的信任。
主要结论:黑箱模型导致了无法解释误差的来源且结果难以预测。
论文结论
问:能否把基于 ML 的模块 X(Learned X)落地于数据库产品中?
答:暂时还不行。
虽然目前基于机器学习的基数估计方法还不能够投入使用,但是他们表现了在准确度上面的潜力以及对数据库优化器可能带来的巨大的影响力。
为了能够真正的把它们部署到真实的数据库产品中,作者认为未来需要重点解决两个问题:
1. 提升模型训练和查询速度
当前大部分的机器学习模型与数据库产品相比,训练和查询时间都有较大差距,同时针对模型本身的参数调优也会花费数据库管理员的时间和精力。
由于更新速度过慢,很多准确度很高的模型无法处理高速变化的数据。
因此提升模型的训练以及查询速度是部署该类方法到数据库产品中的重要前提。
2. 提升模型可解释性
现有的基于学习模型的方法大多基于复杂的黑盒模型,很难预测它们何时会出问题,而且如果出现问题也难以调试。
本文在实验中也展示了它们的一些不符合逻辑的行为,这些都会成为把它们投入到真实使用中的障碍。
因此,提升模型解释性在将来会是一个非常重要的课题,作者认为一方面可以从研究更为透明的模型入手,另一方面也可以投入更多的精力在模型解释和调试中。
关于作者
王笑盈、曲昌博、吴畏远,在读博士,西蒙菲莎大学。
王健楠,副教授,西蒙菲莎大学
2013年在清华大学获得博士学位,并于2013年至2015年在加州大学伯克利分校AMPLab进行博士后的研究。曾获2020年加拿大计算机协会授予的杰出青年奖,2018年IEEE授予的数据工程新星奖,2016年ACM SIGMOD最佳演示奖,2013年CCF最佳博士论文奖,2011年Google PhD Fellowship。
周庆庆,腾讯。
参考文献
[1] http://www.vldb.org/pvldb/vol14/p1640-wang.pdf
[2] https://mp.weixin.qq.com/s/6ndxLWBTXkJQnBz_dNtYRQ
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









