








©PaperWeekly 原创 · 作者 | 张成蹊
单位 | FreeWheel机器学习工程师
研究方向 | 自然语言处理
或许上过 NLP 或大数据课程的同学会想到课程小作业的王者:TF-IDF。掌握一些 NLP 基础的同学可能还会想到静态或动态的词向量:Word2Vec、GloVe、ELMo,BERT——有着探索精神的同学或许会再试试 BERT 的一些为人所熟知的变种:RoBERTa、DistillBERT。
对 BERT 的结构及其各层表达能力有所了解的同学(底层学基础特征,中部学句法信息,上层学语义信息)[1] 会试着取出多层的词向量表示后再做聚合。当然,还需要将这些词向量汇总成一个句子的最终向量,不外乎求和、平均、各种 Pooling…… 最后,也会有同学去寻找一些专门为词向量表达能力进行过强化的预训练模型 Sent2Vec、SentenceBERT。总之,换模型、换方法、换 idea,已经 21 世纪了,调参调包谁不会呢?
有所不同的是,除了盘点上述常用的无监督句向量获得方式外(作为快速获得无监督词向量的途径,上面的方法在落地时具有轮子齐全、即插即用的巨大优势),本文还将介绍一些获得无监督句向量表示的较新方法。这些方法或是解决了上述方法在形式上过于简单粗暴而存在的一些问题,或是在句向量表达能力的评估系统(如 STS tasks)中具有压倒性的优势——众所周知,在 21 世纪,SoTA 与 Accept 呈显著正相关。
现在就让我们开始吧。
本文第一部分会介绍基于词袋模型的一系列句向量表示方法,第二部分主要讲述基于预训练词向量的 Power Mean Embedding 表示方法,第三部分将通过 4 篇论文串讲的方式,从 0 到 1 地介绍对比学习(Contrastive Learning)在无监督句向量中的应用,最后在文末整理了一些值得思考与讨论的点,希望能为大家的工作带来一些微小的启发。

Real-unsupervised methods
首先进场的是无监督场景中的无监督代表队。
顾名思义,这一类方法完全不需要额外的训练或预训练,它们大部分由 Bag-of-Words 的思想衍生而来,通过(1)从句子中提取表达能力相对较强的词汇,并(2)采用某种编码规则将其转换为数字形式,最终获得句子的向量。
值得注意的是,这类依赖于词表的(包括下面的 Word2Vec 等——但经过了预训练的 Word2Vec 模型不在此范围内,因为它已经给定了词表)方法会受到上游的一些诸如 tokenization、lemmatization 与 stemming 在内的数据预处理结果的影响。所以想要更好的使用这类方法,需要注意数据预处理的方式。
1.1 Bag-of-Words思想
假定我们已经拥有了一个分词后的句子库 ,通过扫描,就能获得全量句子的一个总汇性词表 (假设该词表是有序的)。那么,我们就能将每条句子变成一个数值向量,这个向量的长度就是词表的大小 ,向量在位置 0 处的值就是词表中第 1 个单词在该句子中出现的次数、位置 1 处的值就是词表中第 2 个单词在该句子中出现的次数,......,以此类推。
显而易见的是,这个方法是存在问题的:在词表大小很大的时候,储存句子的向量会变成一件十分耗费资源的事情。从直觉上来说,我们应该使用的是一些能更好的有信息表达能力的单词,而删除一些总出现频次过少(生僻字)或总出现频率过高(常见字)的单词,而 TF-IDF 就较好地具备了这些能力。
1.1.1 TF-IDF
解读 TF-IDF 方法细节的博客十分常见,在此不再进行赘述。简单来说,该方法通过 TF 项:单词在当前句子中的出现频次/频率,来表示当前词汇在句子中的重要程度;通过 IDF 项:单词在所有句子中出现的频率(的倒数的对数),来表示当前词汇是不是过于常见。正好匹配原生 BoW 思想中所存在的缺陷。此外,类如 scikit-learn 等机器学习库中的 TF-IDF 方法还有一些如 n-gram 或者 max-df 等额外参数,来帮助调参侠们更好地控制产出特征的质量。
1.1.2 Simhash
与 TF-IDF 不同,Simhash 走了另一条解决问题的道路——有损信息压缩——来节省耗费的资源。Simhash 是一种局部敏感的 hash 算法,最初被 Google 用于亿万级别的网页去重。所谓局部敏感,也就是当句子做出一些细微的改变的时候,基于 Simhash 获得的句子向量也只会产生微小的变化,而非像传统 hash 那样整个签名完全发生改变。
具体而言,对于一个句子,首先使用 TF-IDF 等 BoW 方法获得句子内权重最大的 个单词,随后通过一种或若干种 hash 算法将每个单词都变换为 64 位的 01 二进制序列。遍历该序列,将值为 0 的位置手工修改为 -1。这样,每个单词都被变换为了只包含 的序列。在求整个句子的 hash 值的时候,只需要把它前 个单词的序列对应位置相加。值得注意的是,相加操作后,我们需要将现在 的位置再次修改为 0,从而使得句向量重新变回一个二进制序列。
要判断句子间(段落/文本)的相似度差异,只需要对这两个句子的 Simhash 值进行异或,并判断异或后 64 位中 1 的个数即可。1 的个数越多,则代表这两个句子间不相似的位数越多,即越不相似。
1.2 SAUCE
SAUCE [2] 是今年的 CIKM 中一篇比较有趣的工作,同时也使用了 BoW 的思想来提取文本表示向量。SAUCE 的立意其实与 Simhash 更为相似一些,即为了快速检索相似的文本 —— 再具体一点讲,SAUCE 提出的大背景是:我们已经具有了相当丰富的预训练模型,而我们往往希望将这些模型应用到我们 domain-specific 的任务中。
与这个目的相悖的是,BERT 等预训练模型为了具有更加 general 的文本表示能力,都是在 Wiki 等通用语料上进行预训练的。因此产生了一个新的需求:我们希望能够给定一些领域相关的语料作为种子(corpus seed),来对大规模网页文本进行检索,获得大量相似的领域内文本,从而对通用的预训练模型进行进一步的训练(post-pretrain),提升它们在具体领域内的表示能力。
假定总文档数为 ,首先,像所有的 BoW 方法一样,SAUCE 产生了一份所有文档具有的单词词表 。上文已经提到,直接进行文档的向量化会导致每个文档的向量大小都是 。为了进一步缩小维度,SAUCE 计算了每个单词出现的文档数 (Document Count),即:
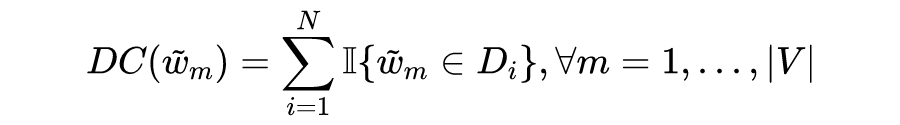
其中 是指示函数,当 出现在第 个文档 中时为 1,否则为 0。
SAUCE 基于 来实现维度的缩减,提出了两个用于控制维度的阈值:
用于筛除出现频次过低的单词,即简单粗暴地删除所有出现频次不到 的单词。删除后的维度被快速缩减到:
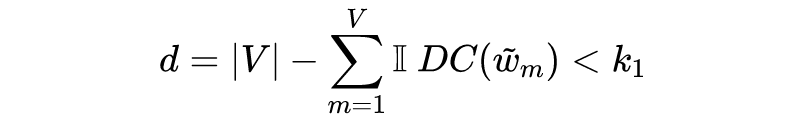
用于控制保留的数量,即在经过 筛选后,接下来只保留剩余单词中 最小的 个。这个控制方式更加粗暴,强行把向量维度控制到:
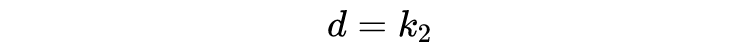
然后呢?然后没有了。因为精美的食材,往往只需要简单的烹饪。
下图是作者提供的算法伪代码,让我们再过一遍:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 81
81











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









