








©PaperWeekly 原创 · 作者 |苏剑林
单位 |追一科技
研究方向 |NLP、神经网络
Dropout 是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近 Dropout 有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的 SimCSE [1] 和 R-Drop,尤其是在文章《又是 Dropout两次!这次它做到了有监督任务的 SOTA》中,我们发现简单的 R-Drop 甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout 是被加在每一层的输出中,或者是加在模型参数上,这是 Dropout 的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》[2] 中学到了一种新颖的用法:加到梯度上面。
梯度加上 Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。

方法大意
简单来说,这篇论文主要提出了一种名为“ChildTuning”的思路,来提高预训练模型在 finetune 时的效果,其中“Child”是“Children Network”的意思,指的是从预训练模型中选择一个子网络进行优化,缓解优化整个模型所带来的过拟合风险。其中,在子网络的选择上,又分为两种方式:ChildTuning-D 和 ChildTuning-F。

ChildTuning-D
ChildTuning-D(Task-Dependent)是任务相关的选择方式,它需要下游任务的训练数据来参与计算。具体来说,假设训练数据为 ,模型为 ,其中 是模型的所有参数,而 则是其中的第 i 个参数,那么我们计算如下形式的 Fisher 信息作为该参数的重要性:
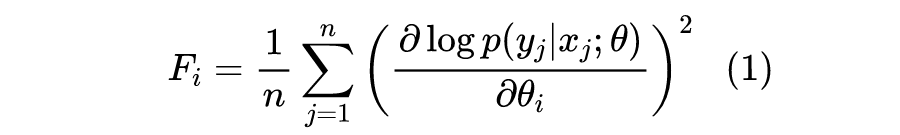
有了重要性指标后,我们就可以对每个参数进行排序,然后选出最重要的 部分(比如前 20%,即 ),然后在模型更新的时候只优化这些参数。由于优化的参数变少了,所以过拟合的风险也就降低了。在实际使用时,ChildTuning-D 在 finetune 之前就把要优化的参数确定下来,然后就一直保持不变了。
要注意的是,这里的参数选择是以每个分量为单位的,也就是说,可能一个参数矩阵里边,只有一部分被选择中,所以不能说单独挑出哪些参数矩阵不优化,而是要通过构建对应的 0/1 矩阵 来将对应的梯度 mask 掉,即,其中除以 是保持整理的更新量级不变。这样没被选中的参数梯度一直是 0,所以也就没有更新了。这样一来,虽然理论上更新的参数少了,但它也不能节约计算量,所以作者只是将它定位为提高 finetune 效果的方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









