








©作者 | 丹师
单位 | 伯明翰大学
研究方向 | 机器学习
本文来自于一篇博士论文,上周查阅 Cross Validated 时候发现的。这篇论文让我眼前一亮是使用 Kalman filter(卡尔曼滤波)去解决机器学习(Deep Gaussian Process, DGP)的问题。而且论文的外审专家和答辩评委(pre-examiner, opponent)是 David Duvenaud 和 Manfred Opper,两人都是机器学习 GP 和 SDE 的大牛,论文的质量应该是有保证的。论文比较长而且其第 2,3 章的内容不是我的专业而且和 GP 没多大关系,因此只讨论第四章。第四章的内容貌似大部分来源于这个论文。

论文标题:
State-space deep Gaussian processes with applications
关键词:
高斯过程,状态空间,卡尔曼滤波
论文链接:
https://github.com/zgbkdlm/dissertation/blob/main/dissertation.pdf
https://link.springer.com/article/10.1007/s11222-021-10050-6
https://aaltodoc.aalto.fi/handle/123456789/111268
代码链接:
https://github.com/zgbkdlm/dissertation
这也是笔者第一次写学习笔记,花了好长时间阅读,如有错误请大佬评论区指出勿喷。

背景介绍
高斯过程(Gaussian process),以下简称 GP [1],是一种广泛应用于机器学习中的概率模型。如果一个过程 是 GP 的话,我们一般我们用以下公式来表示:
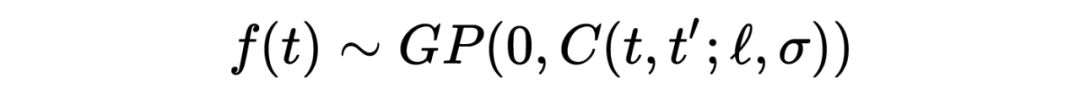
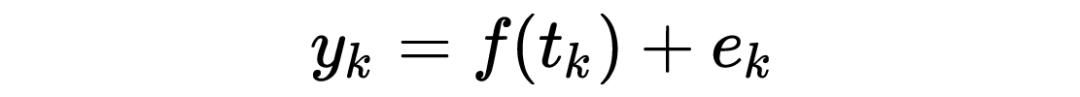
上述公式中,C 是核函数(kernel function),也叫协方差函数(covariance function),另外 C 有两个超参数 需要人工设定或者从数据集中学习、估计。e 代表观测的高斯噪声。以下我们假设 f 的均值函数(mean function)是 0。
GP 的优势主要是因为他是 Infinite-dimensional 模型。怎么理解呢?设想神经网络,其网络权值需要从数据中学习,而且学到的值是 deterministic 固定的。而 GP 是 non-parametric,从数据中学到是一个分布,是一个关于函数的后验分布,因此包含无限种取值可能性。但相应的,这牺牲了 GP 的计算复杂度。
GP 主要有两个问题:
1. 计算复杂度高;
2. 对非稳态&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2375
2375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









