







©作者 | 微风
单位 | 中山大学+IDEA研究院
研究方向 | 多模态表征学习、多模态生成
DALL·E 2 之所以能够生成十分惊艳的图像,扩散模型功不可没,相比 GAN,该模型可以生成更多样,更高质量的图像(缺点在于计算量很大,需要反复迭代)。扩散模型的思想很简单,inference 的时候给定一个噪声信号作为输入,训练一个模型估计高斯噪声,用噪声减去这个预测的噪声,然后重复迭代以上操作直至恢复原始信号。理论上,可以用于语音合成、图像生成、超分辨率等连续信号的生成。
本文主要介绍扩散模型及其在图像生成领域的应用,主要包括以下部分:
扩散模型(diffusion model)的原理
引导扩散模型 guided diffusion model(classifier-guidance, semantic-guidance, classifier-free-guidance)
GLIDE
DALL·E 2

扩散模型(Diffusion Model)
1.1 概述
如图所示,扩散模型分两个过程:扩散(diffusion,从 到 的过程逐步加入噪声)和去噪(denoise,从 到 逐步去噪)。训练的时候,需要利用扩散加噪来生成训练样本;推理的时候,输入一个噪音,逐步去噪输出原始信号(比如图像、语音)。
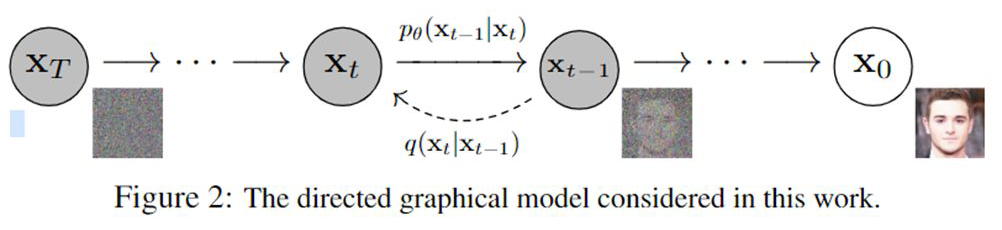
参考文献:Denoising Diffusion Probabilistic Models
1.2 扩散和去噪(Diffusion&Denoise)
首先介绍一下高斯分布的表达,记作 :
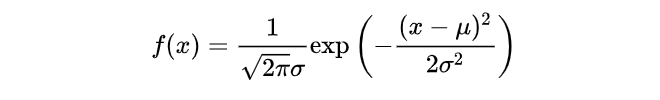
扩散过程每一步都加入一个方差为 的高斯噪声可以用马尔科夫链来表示:
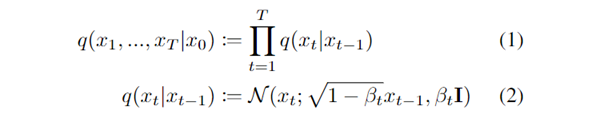
这里的 是一个 0 到 1 的等比序列(),此时表示原始图像;第 步的时候,,表示标准高斯噪声 。因而实际上扩散过程是一个从原始图像变为标准高斯分布的过程。加噪和高斯采样等价,无非就是改变了一下高斯采样的均值中心点。
实际训练的时候,我们可以直接用下面的公式一次性算出某一步的加噪图片作为训练素材,无需逐步迭代。

去噪过程和扩散过程反过来:从一张随机采样的高斯噪声图片逐步去噪得到我们想要生成的图像。表达式:
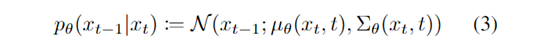
去噪过程,需要用模型预测加入的高斯噪声,得到原始的无噪声的图像。上式表示,利用模型算出原始第 n 步的未加噪图像,实质上只要算出均值和方差,再做一个采样得到原始图像。而为了算出 ,我们需要预测出噪声 ,反推出原始图像的均值中心,方差项可以由网络预测也可以取常数(前者效果好)。下节将介绍模型的训练和推理过程。
1.3 训练和采样(Training&Sampling)
训练其实就是扩散过程,而采样其实就是去噪过程。

算法如上图所示,训练 training 的过程实际上是随机采第 t 步的加噪图像,输入带噪图片以及步数 t,模型预测噪声 ,模型训练目标:预测噪声与实际加入噪声的误差越小越好。
采样 sampling 的过程(生成过程)为:将有噪声的图像(第一张图像为随机采样的高斯分布噪声)减去模型预测的噪声(噪声前面的其它参数可以由上面加噪的过程反向推导出来)不断把噪声去掉以恢复出原始的图像。
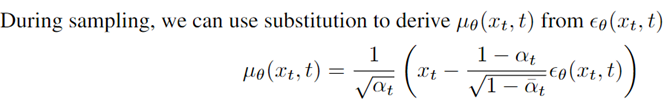
方差项 也可以由模型来预测。
参考文献:Improved Denoising Diffusion Probabilistic Models

引导扩散模型(Guided Diffusion)
前文已经讲述扩散模型的原理,然而我们随机输入一张高斯噪声显然不能按照人的意愿生成我们想要的内容,因而需要额外的引导 guidance 以得到我们需要的图像。一种想法是使用外部模型(分类器 or 广义的判别器)的输出作为引导条件来指导扩散模型的去噪过程,从而得到我们想要的输出;还有一种则比较直观一些:我们直接把我们想要的引导条件 condition 也作为模型输入的一部分,从而让扩散模型见到这个条件后就可以直接生成我们想要的内容。
下文将讲解 classifier guidance 和 semantic guidance diffusion model(后者包括前者,前者是比较简单的一个应用),除此之外,由于额外的判别器会拖慢推理速度,因此后来有人提出了 classifier-free guidance diffusion model 来替代前面的那种方案,也即把条件作为模型的输入,直接生成我们需要的图像。
2.1 Classifier Guidance Diffusion Model
这种方法不用额外训练扩散模型,直接在原有训练好的扩散模型上,通过外部的分类器来引导生成期望的图像。唯一需要改动的地方其实只有 sampling 过程中的高斯采样的均值,也即采样过程中,期望噪声图像的采样中心越靠近判别器引导的条件越好。

上图总结了采样算法。Algorithm 1 和 Algorithm 2 其实是等价的(1 是直接预测均值和方差,2 是预测噪声的误差)。直接看 Algorithm 1 可知,实质上改变的只有高斯分布的均值中心,将扩散方向“引导”成我们想要的内容。具体而言,用分类模型 对生成的图片进行分类,得到预测分数与目标类别的交叉熵,将其对带噪图像求梯度用梯度引导下一步的生成采样。(实际使用的时候,需要把这个分类器也在带噪数据额外训练一下)
因为我们实际使用的模型预测的是噪音,实际计算为 Algorithm 2,可以由 1 推导而来。(具体推导过程可以参考文献)
参考文献:Diffusion Models Beat GANs on Image Synthesis
2.2 Semantic Guidance Diffusion
介绍完前面的 classifier guidance 后,显然我们可以把分类器替换成其它任意的判别器,也即更换引导条件,从而实现利用不同的语义信息来指导扩散模型的去噪过程。比如说,我们可以实现 text-guidance 和 image-guidance 等。
实质上就是把 classifier guidance 的条件推广,表达为:
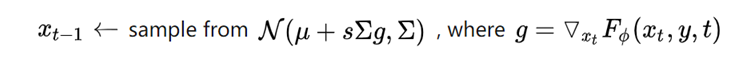
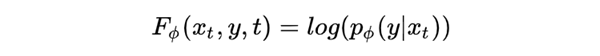
表示就是新的引导条件,这里展示的是分类的,其实也可以换成相似度之类的分数指标。具体可以有以下的例子:图像引导、文本引导、图像+文本引导。

参考文献:More Control for Free! Image Synthesis with Semantic Diffusion Guidance
2.3 Classifier-Free Guidance Diffusion
正如前文提到的,额外引入一个网络来指导,推理的时候比较复杂(扩散模型需要反复迭代,每次迭代都需要额外算一个分数)。然而,直接将引导条件作为模型的输入,直到 Classifier-Free Diffusion Guidance 被提出前似乎效果也一般般。Classifier-Free Diffusion Guidance 这篇文章的贡献就是提出了一个等价的结构替换掉了外部的判别器,从而可以直接用一个扩散模型来做条件生成任务。
实际做法只是改变了模型输入的内容,有 conditional(除了随机高斯噪声输入外,把引导信息的 embedding 也加进来)和 unconditional 的 sample 输入。两种输入都会被送到同一个 diffusion model 从而让其能够具有无条件和有条件生成的能力。得到这两种输入的输出后,就可以用来引导扩散模型进行训练。
回忆一下前面的 classifier guidance 的噪音更新方式:
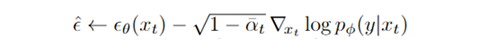
实质上,这个 classifier-free 用另一个近似的等价结构替换掉了后面那一项:
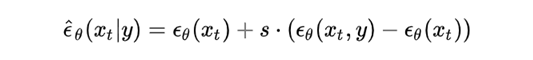
其中, 表示 conditional 的输入,而 则表示 unconditional 输入,用这两项之差乘以一个系数来替换掉原来的那项。至于为什么可以这么直接替换,其实可以用贝叶斯公式推导而来:
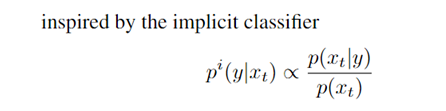

因而,实际上这个过程就训练了一个 implicit classifier,从而移除外部的分类器。
参考文献:Classifier-Free Diffusion Guidance

GLIDE
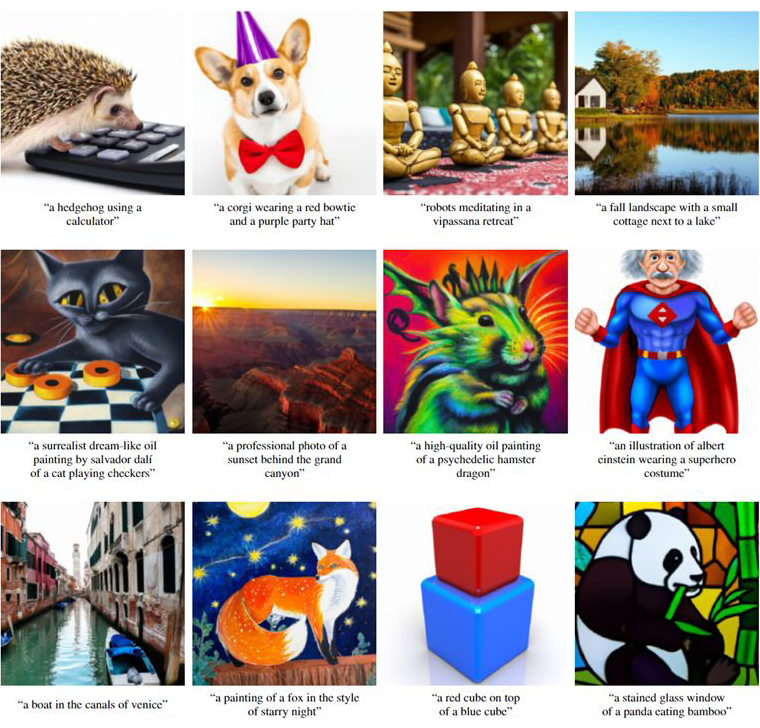
这篇文章主要就是用到了前面所说的 classifier-free 扩散模型,只不过把输入的 condition 换成了文本信息,从而实现文本生成图像,此外还利用 diffusion model 实现了超分辨率。一些效果展示如下,可以看到,其实已经可以生成一些比较逼真的图片了。
具体可以表达为:

这里无非就是把原来的 label y 换成了 caption,实际上就是运用了足够量的 image-text pair 从而可以把 caption 当作是某种程度上的 label。(随机替换为空序列以实现 unconditional 的训练方式)
由于此时的生成图像质量一般般,文章也提供了图像编辑的方式(具体操作为:将选中区域 mask 掉,将图像也作为一个 condition 连同文本输入到模型中去):


DALL·E 2
4.1 概况
第一版 DALL·E 用的是 GAN+CLIP 重排序的结构。
DALL·E 2 可以把 diffusion model 和 CLIP 结合在一起,生成效果十分惊艳,可以直接去官网浏览一下。DALL·E 2(openai.com)。

包括 prior 网络用于将 caption 转换为 CLIP image embedding,一个decoder 把 image embedding 作为 condition 来生成图像。prior 有两种:一种是 autoregressive model、一种是 diffusion model(后者效果更好一些);decoder 就是 diffusion model。总之,这里相比前面的变化主要在于加入了 prior,以及把 condition 换成了 CLIP 的 embedding。
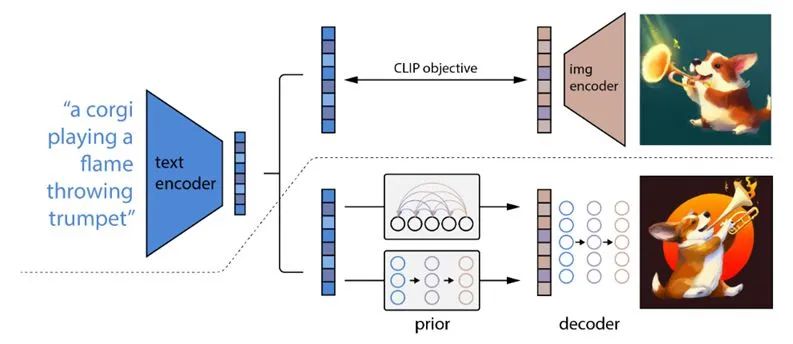
4.2 Decoder
具体而言,把 CLIP image embedding 作为 condition 输入到 diffusion model 中,同时把 CLIP image embedding 映射成 4 个额外的 tokens 接到 GLIDE text encoder 的输出。
除了用于生成图像的 diffusion model,这部分还有 2 个额外用于超分辨率的 diffusion model,生成高清图像。
4.3 Prior
这部分的内容是为了将 caption y 转换为 CLIP image embedding,以用于后面 decoder 的图像生成。
一种是 auto-regressive model,将 image embedding 转换为一串离散的编码,并且基于 condition caption  自回归地预测。(这里不一定要 condition on caption(GLIDE 的方法——额外用一个 Transformer 处理 caption),也可以condition on CLIP text embedding)。此外,这里还用到了 PCA 来降维,降低运算复杂度。
自回归地预测。(这里不一定要 condition on caption(GLIDE 的方法——额外用一个 Transformer 处理 caption),也可以condition on CLIP text embedding)。此外,这里还用到了 PCA 来降维,降低运算复杂度。
一种是 diffusion model。这是一个 decoder-only Transformer,输入是 encoded text+CLIP text embedding+noised CLIP image embedding+ 额外token(类似 class embedding)输入,其输出一个 unnoised CLIP image embedding(取那个额外的 embedding)。
4.4 Variations
这部分是为了给一张图,生成相似的图像。做法很简单:用 CLIP 把图像编码,把这个 CLIP image embedding 作为 condition 引导 decoder 生成图像。除此之外,还可以对 2 张图像的 CLIP embedding 进行插值,以实现风格迁移。( spherical interpolation 几何球面线性插值)。这里证明了 CLIP 语义空间的可解释性。

4.5 量化结果
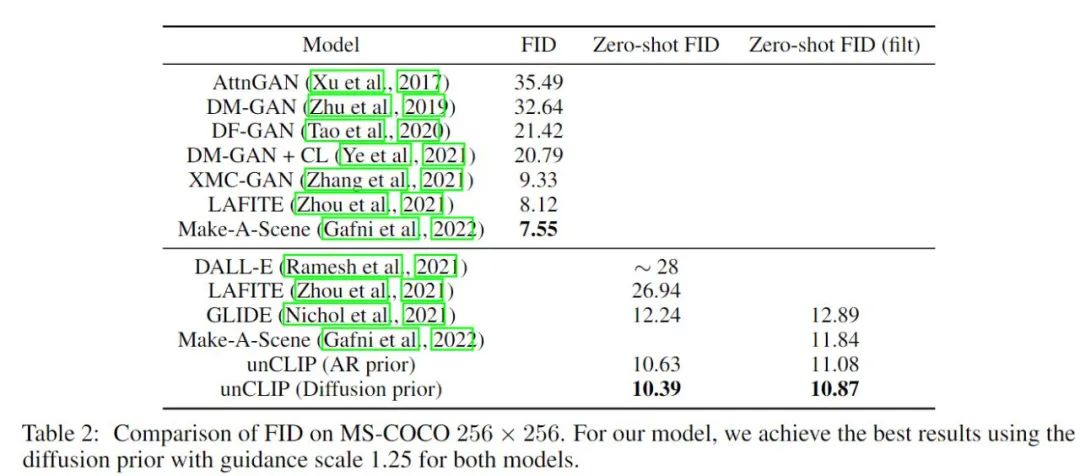
本文方法又称 unCLIP(其实本质上就是把 CLIP 生成的 embedding 进行 decode),相比 GLIDE 有小幅的提高。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









