









论文标题:
Ekko: A Large-Scale Deep Learning Recommender System with Low-Latency Model Update
收录会议:
OSDI 2022
论文链接:
https://www.usenix.org/system/files/osdi22-sima.pdf

研究背景
基于深度学习的推荐系统(Deep Learning Recommender System, DLRS)是众多大型技术公司和组织的关键基础设施。一个典型的 DLRS 架构如下图所示,它通常包含了大量参数服务器以支撑众多的机器学习模型,例如嵌入特征表、深度神经网络。这些参数服务器在不同地区的数据中心进行备份,从而和处于全球不同地区的用户进行容错、低延迟的通信。
为了保证对新用户和新内容进行快速服务,DLRS 必须持续地更新机器学习模型。这一过程首先利用训练服务器收集新的训练数据,并计算模型梯度;接着利用广域网将模型更新传播到各个参数服务器的备份模型。
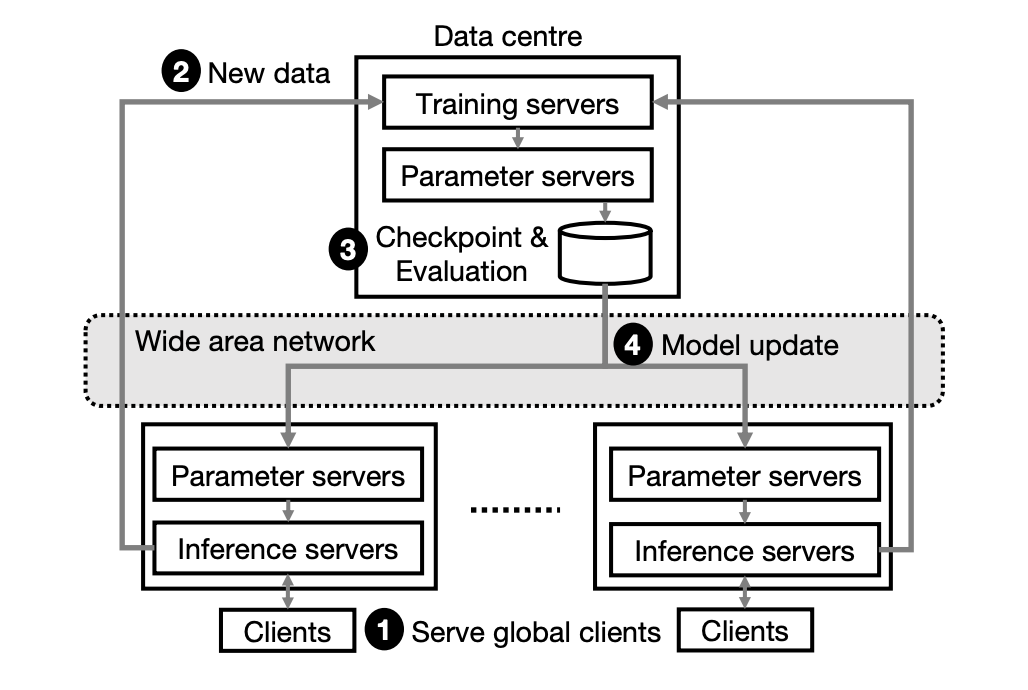
大规模 DLRS 需要为十亿级别的用户提供服务,因此必须实现关于延迟指标的服务级别目标(Service-Level Objective, SLO),例如将一个新上传内容提供给用户的延迟时间。并且,DLRS 在模型更新方面需要满足一些新的低延迟需求,从而应对以下实际场景中的新因素、最好地实现 SLO:
1. 最近的 DLRS 应用,例如 YouTube、抖音,使用户能够生产海量的短视频、文章、图片内容。这些内容需要在几分钟、甚至几秒内提供给其他用户;
2. 如 GDPR 等数据保护法规允许 DLRS 用户进行匿名,而匿名用户的行为必须进行在线学习;
3. 实际生产中越来越多的机器学习模型,例如强化学习,被用于提升应用的推荐质量。这些模型需要进行持续的在线更新,以达到最佳模型效果。
不幸的是,实现上述低延迟模型更新在现有的 DLRS 中极其困难。现有系统通过离线方法进行模型更新:采集新训练数据后,离线对模型参数计算梯度,验证模型检查点(checkpoint),将模型更新传输到所有数据中心。这样的离线流程需要花费长达数小时进行模型更新。一个替代方法是使用广域网优化的机器学习系统,或联邦学习系统。这些系统使用本地收集的数据更新模型,并 lazy 同步到重复的模型副本中。但 lazy 同步技术不可避免地造成相当程度的异步更新,这通常对系统实现 SLO 造成一定的负面影响。
本文希望探索一种 DLRS 系统设计方案,能够在不降低 SLO 的前提下实现低延迟的模型更新。本文的关键思想是允许训练服务器在线更新模型并立即将模型更新传输到所有模型推理集群。这一设计允许我们绕过离线训练、模型检查、验证、传播等高延迟步骤,从而减少模型更新延迟。
为了实现这一设计,我们需要解决以下几个关键挑战:1)面对带宽限制、异构网络结构等问题,怎样基于广域网高效地传输模型更新;2)当发生网络拥塞、关键模型更新传输发生延迟时,怎样保证 SLO 的实现;3)怎样处理对模型准确率有害的有偏(biased)模型更新,以保证 SLO 的实现。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









