








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
老读者也许会发现,相比之前的更新频率,这篇文章可谓是“姗姗来迟”,因为这篇文章“想得太多”了。
通过前面九篇文章,我们已经对生成扩散模型做了一个相对全面的介绍。虽然理论内容很多,但我们可以发现,前面介绍的扩散模型处理的都是连续型对象,并且都是基于正态噪声来构建前向过程。而“想得太多”的本文,则希望能够构建一个能突破以上限制的扩散模型统一框架(Unified Diffusion Model,UDM):
1、不限对象类型(可以是连续型 ,也可以是离散型的 );
2、不限前向过程(可以用加噪、模糊、遮掩、删减等各种变换构建前向过程);
3、不限时间类型(可以是离散型的 ,也可以是连续型的 );
4、包含已有结果(可以推出前面的 DDPM、DDIM、SDE、ODE 等结果)。
这是不是太过“异想天开”了?有没有那么理想的框架?本文就来尝试一下。

前向过程
从前面的一系列介绍中,我们知道构建一个扩散模型包含“前向过程”、“反向过程”、“训练目标”三个部分,这一节我们来分析“前向过程”。
在最初的 DDPM 中,我们是通过 来描述前向过程的;后来,随着 DDIM 等工作的发表,我们逐渐意识到,扩散模型的训练目标和生成过程,都跟 没直接联系,反而跟 的联系更为直接,而从 推导 往往也比较困难。因此,一个更为实用的操作就是直接以 为出发点,也就是将 视为前向过程。
的最直接作用,就是用来构建扩散模型的训练数据,因此 的最基本要求是便于采样。为此,我们可以通过重参数
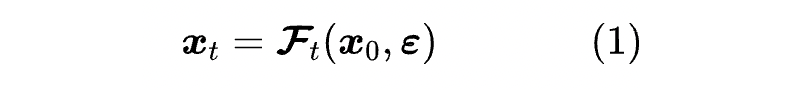
其中 是关于 的确定性函数, 是采样自某个标准分布 的随机变量,常见选择是标准正态分布,但其他分布通常也是可行的。可以想像,该形式包含了足够丰富的 到 的变换,它对 、 的数据类型也没有约束。一般情况下,唯一的限制是 越小, 所包含的 的信息越完整,换言之用 重构 越容易,反之 t 越大重构就越困难,直到某个上界 时, 所包含的 的信息几乎消失,重构几乎不能完成。

反向过程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









