








©PaperWeekly 原创 · 作者 | 连同学

论文标题:
Unsupervised Selective Labeling for More Effective Semi-Supervised Learning
作者单位:
UC Berkeley / ICSI,伯克利/国际计算机科学研究所
论文链接:
https://arxiv.org/abs/2110.03006
代码链接:
https://github.com/TonyLianLong/UnsupervisedSelectiveLabeling
TL; DR:现有的半监督算法大多着眼于改善训练方式,而忽略了“数据集中的哪部分需要标注”这个问题。我们的 Unsupervised Selective Labeling(USL)着眼于从完全无标注的情况下从无标注数据集中选择一部分数据来获取标注,然后再运行传统的半监督学习算法,从而以更少的标注成本来达到更高的半监督学习的效果。我们的方法在半监督学习里的常用数据集上达到了远好于现有选择方法的效果(使用原来 1/8 到 1/25 的标注数据,在半监督学习上达到原有选择方案的精确度)。

半监督学习
众所周知,深度学习算法在很多应用领域都取得了很大的成功。但是最常用的监督学习算法训练出的模型效果严重依赖于数据量,尤其是数据标注的量。
半监督学习(Semi-supervised Learning,简称 SSL)旨在解决这个问题:因为无标注数据在大多数情况下很容易获取,然而手工标注需要大量的时间和成本,半监督学习使用部分标注的数据集来对模型来训练。通过利用未标注的数据,半监督学习可以只使用很少的标注数据来达到和标注整个数据集差不多的效果。半监督学习这个领域很大,本文关注 CV 领域的半监督分类问题。
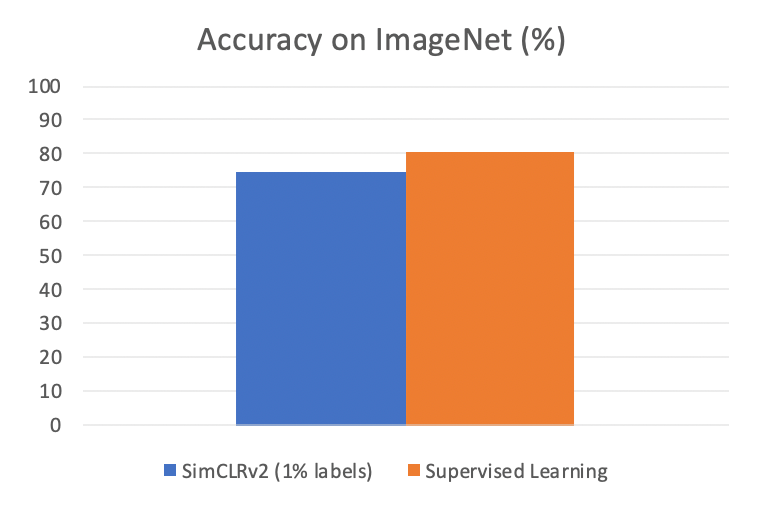
半监督学习领域发展得非常迅猛,就拿 ImageNet 来说,只需要 1% 的标注数据(每个 class 给大约 13 张标注图片),SimCLRv2 就能达到 76.6% 的 Top-1 精确度(同样的模型给 100% 数据标注也只能达到 80.5%)。使用 Transformer 模型和 1% 的数据,新发布的 Semi-ViT 方法能达到 80% 的 Top-1 精确度。这也就是说在实际运用中,我们完全有可能可以只标注数据集的一部分,然后让模型也达到很高的精度。

半监督学习的隐秘角落
可是这里出现了一个问题:我们到底要标注数据集的哪个部分呢?这个问题是值得探讨的:如果不按照一定规律选择的话,我们完全可能会遇到几种情况:
1. 目前标注的这个数据其实之前有类似的数据标过了,我们完全可以让模型自己去推算这个数据的标注。
2. 目前标注的数据是一个outlier,这样标注的数据集很可能会导致半监督算法没办法稳定训练,甚至崩溃(collapse)。
这两种情况都没有办法给模型的训练提供有效信息,也就浪费了珍贵的标注预算。
大部分半监督领域的工作(例如 SimCLRv2)都直接绕过了这个问题,如下图(右)所示:这类算法假设我们已经有一个数据集,并且其中有一些部分已经是标注好的,然后直接在上面运行算法。
很多现有半监督领域的工作都是在半监督方法上做改进,以模型的训练方式为中心,我们这里称之为 Model-Centric SSL 方法。而这个数据集的标注方式其实就是随机抽取:我们随机在未标注的数据集里面,按照我们的标注预算来选择一部分数据(例如 1% 数据),来进行标注。
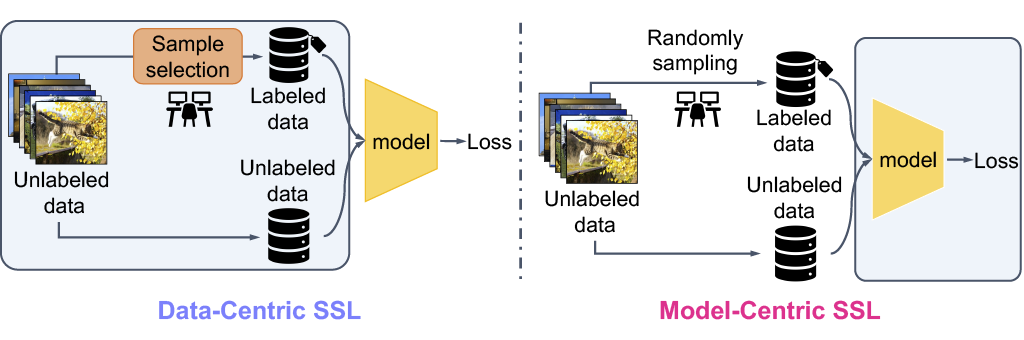
另一个大部分半监督领域的工作绕过的问题是,大部分的半监督领域的工作其实对数据分布做了假设:它们假设有标注数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









