







©作者 | 袁铭怿、陈萍
来源 | 机器之心
关于 Transformer ,这是一篇很好的学习指南,可以帮助你熟悉最流行的 Transformer 模型。
自 2017 年提出至今,Transformer 模型已经在自然语言处理、计算机视觉等其他领域展现了前所未有的实力,并引发了 ChatGPT 这样的技术突破,人们也提出了各种各样基于原始模型的变体。
由于学界和业界不断提出基于 Transformer 注意力机制的新模型,我们有时很难对这一方向进行归纳总结。近日,领英 AI 产品战略负责人 Xavier Amatriain 的一篇综述性文章或许可以帮助我们解决这一问题。
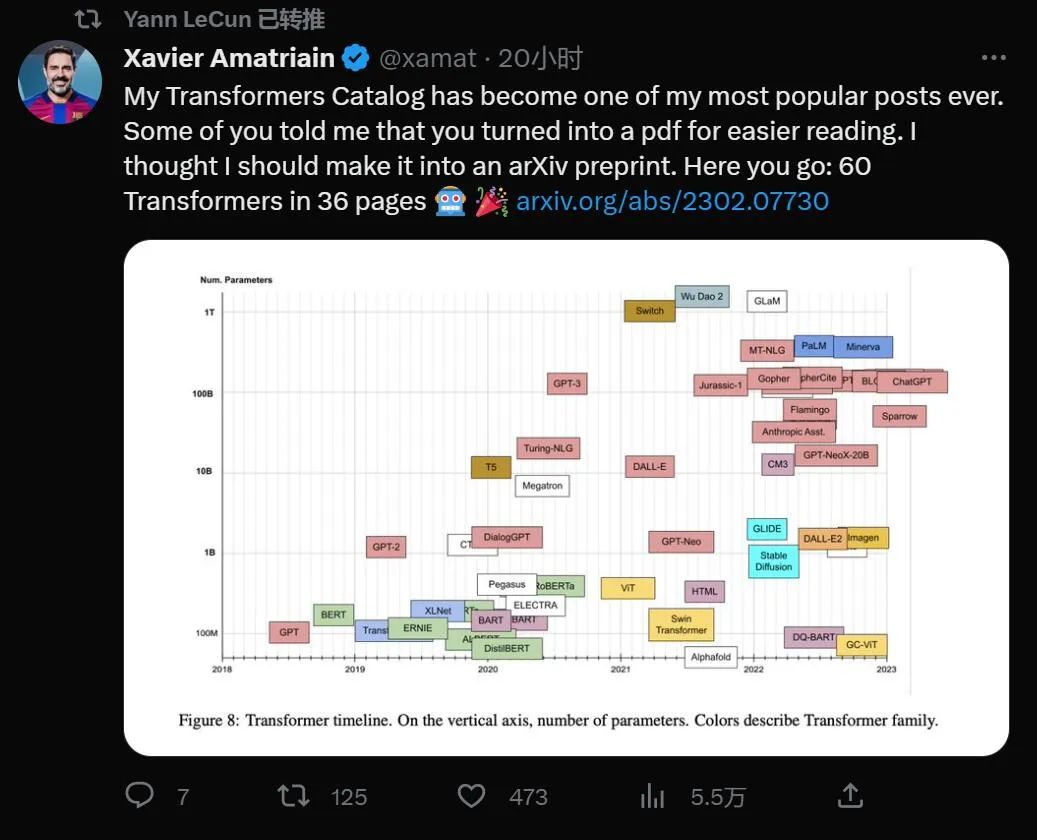
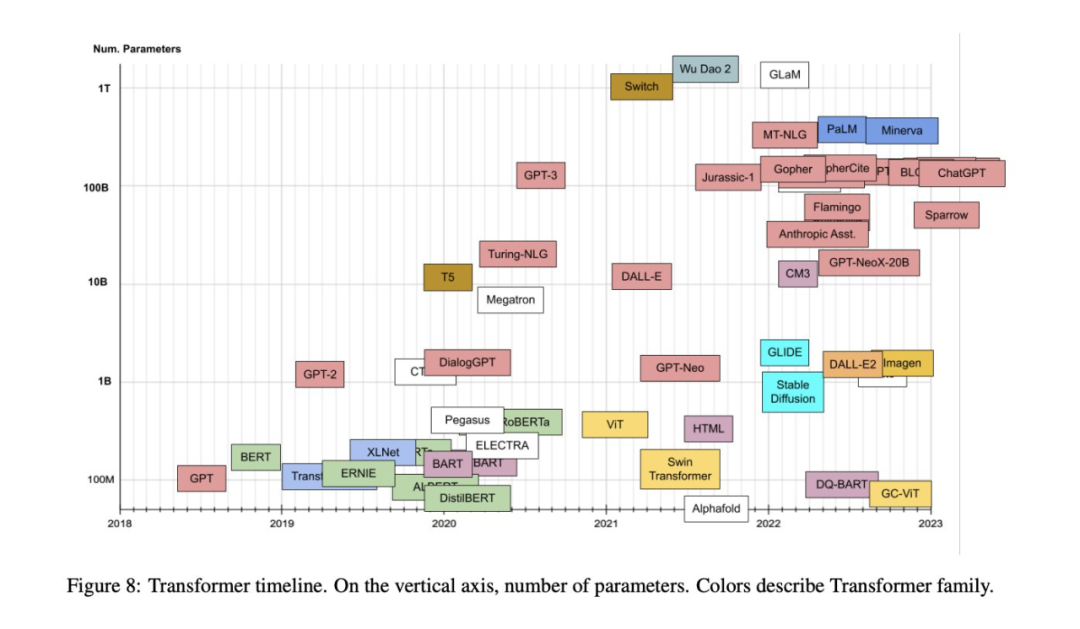
在过去的几年里,陆续出现了数十个来自 Transformer 家族模型,所有这些都有有趣且易懂的名字。本文的目标是为最流行的 Transformer 模型提供一个比较全面但简单的目录和分类,此外本文还介绍了 Transformer 模型中最重要的方面和创新。

论文标题:
Transformer models: an introduction and catalog
论文链接:
https://arxiv.org/abs/2302.07730
Github:
https://github.com/xamat/TransformerCatalog

简介:什么是Transformer?
Transformer 是一类由一些架构特征定义的深度学习模型。首次出现在谷歌研究人员于 2017 年发表的著名论文《Attention is All you Need》中(这篇论文在短短 5 年就被引用了 3.8 万余次)以及相关的博客文章中。Transformer 架构是编码器 - 解码器模型 [2] 的一个特定实例,该模型在 2 - 3 年前开始流行起来。
然而,在此之前,注意力只是这些模型使用的机制之一,这些模型主要基于 LSTM(长短期记忆)[3] 和其他 RNN(循环神经网络)[4] 变体。Transformers 论文的关键见解是,正如标题所暗示的那样,注意力可以被用作推导输入和输出之间依赖关系的唯一机制。讨论 Transformer 体系结构的所有细节超出了本博客的范围。
为此,本文建议参考上面的原论文或 Transformers 的帖子,内容都十分精彩。话虽如此,本文将简要叙述最重要的方面,下面的目录中也会提到它们。本文将先从原始论文中的基本架构图开始,继而展开叙述相关内容。
编码器 / 解码器架构
通用编码器 / 解码器体系架构(参见图 1)由两个模型组成。编码器接受输入并将其编码为固定长度的向量。解码器获取该向量并将其解码为输出序列。编码器和解码器联合训练以最小化条件对数似然。一旦训练,编码器 / 解码器可以生成给定输入序列的输出,或者可以对输入 / 输出序列进行评分。
在最初的 Transformer 架构中,编码器和解码器都有 6 个相同的层。在这 6 层中的每一层编码器都有两个子层:一个多头注意层和一个简单的前馈网络。每个子层都有一个残差连接和一个层归一化。编码器的输出大小是 512。解码器添加了第三个子层,这是编码器输出上的另一个多头注意层。此外,解码器中的另一个多头层被掩码。
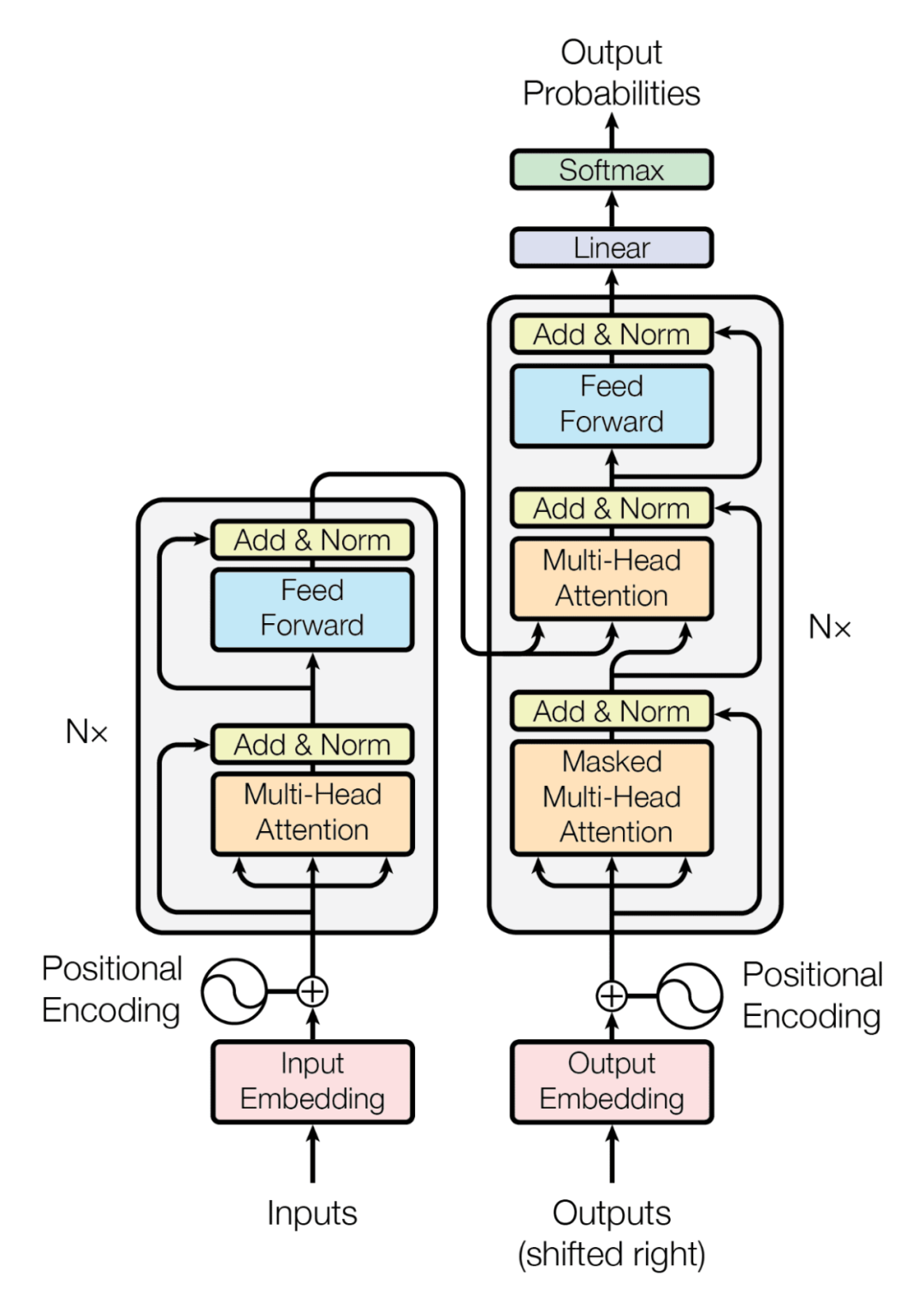
▲ 图1. Transformer 体系架构
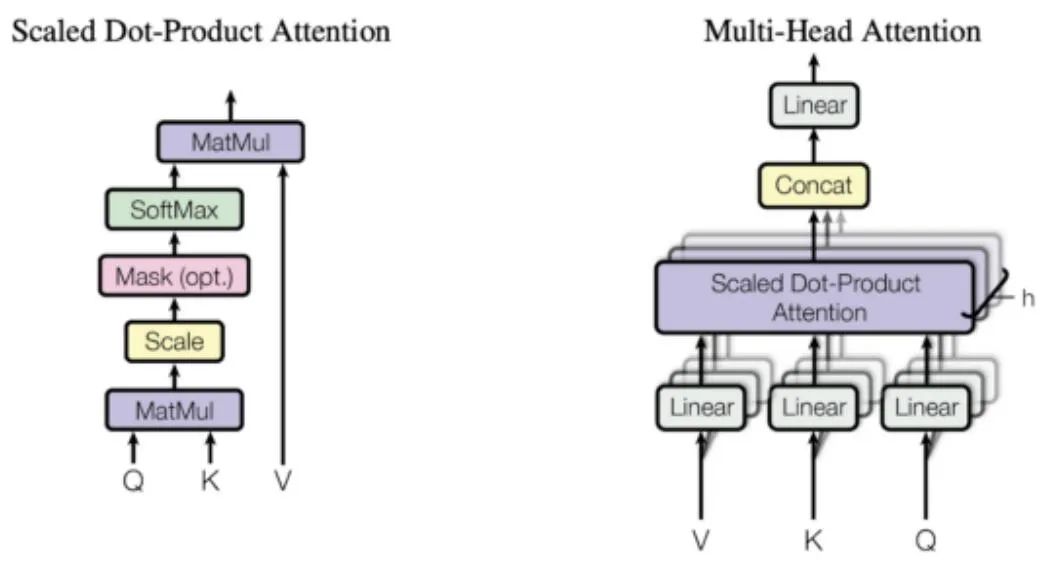
▲ 图2. 注意力机制
注意力
从上面的描述可以清楚地看出,模型体系架构唯一的特别元素是多头注意力,但是,正如上面所描述的,这正是模型的全部力量所在。那么,注意力到底是什么?
注意力函数是查询和一组键值对到输出之间的映射。输出是按值的加权和计算的,其中分配给每个值的权重是通过查询与相应键的兼容性函数计算的。Transformers 使用多头注意力,这是一个被称为缩放点积注意力的特定注意力函数的并行计算。
关于注意力机制如何工作的更多细节,本文将再次参考《The Illustrated Transformer》的帖文,将在图 2 中再现原始论文中的图表,以便了解主要思想。与循环网络和卷积网络相比,注意力层有几个优势,最重要的两个是它们较低的计算复杂性和较高的连通性,特别是对于学习序列中的长期依赖关系非常有用。
Transformer的用途是什么,为什么它们如此受欢迎?
最初的 Transformer 是为语言翻译而设计的,特别是从英语到德语。但是,通过原先的研究论文就可以看出,该架构可以很好地推广到其他语言任务。这一特别的趋势很快就引起了研究界的注意。在接下来的几个月里,大多数与语言相关的 ML 任务排行榜完全被某个版本的 Transformer 架构所主导(比方说,著名的 SQUAD 排行榜,其中所有位于顶部的模型都是 Transformer 的集合)。
Transformer 能够如此迅速地占据大多数 NLP 排行榜的关键原因之一是它们能够快速适应其他任务,也就是迁移学习。预训练的 Transformer 模型可以非常容易和快速地适应它们没有经过训练的任务,这具有巨大的优势。作为 ML 从业者,你不再需要在庞大的数据集上训练大型模型。你所需要做的就是在你的任务中重新使用预训练的模型,也许只是用一个小得多的数据集稍微调整它。一种用于使预训练的模型适应不同任务的特定技术被称为微调。
事实证明,Transformer 适应其他任务的能力是如此之强,以至于尽管它们最初是为与语言相关的任务而开发的,但它们很快就被用于其他任务,从视觉或音频和音乐应用程序,一直到下棋或做数学。
当然,如果不是因为有无数的工具,任何人都可以轻松地编写几行代码,那么所有这些应用程序都不可能实现。Transformer 不仅能被迅速整合到主要的人工智能框架(即 Pytorch8 和 TF9)中,甚至基于此创建起整个公司。Huggingface 是一家迄今为止已经筹集了 6000 多万美元的初创公司,几乎完全是围绕着将开源 Transformer 库商业化的想法建立的。
最后,有必要谈谈 Transformer 普及初期 GPT-3 对其的影响。GPT-3 是 OpenAI 在 2020 年 5 月推出的 Transformer 模型,是他们早期 GPT 和 GPT-2 的后续产品。
该公司通过在预印本中介绍该模型而引起了很大的轰动,他们声称该模型非常强大,以至于他们无法向世界发布它。从那以后,该模型不仅发布了,而且还通过 OpenAI 和微软之间的大规模合作实现了商业化。GPT-3 支持 300 多个不同的应用程序,是 OpenAI 商业战略的基础 (对于一家已经获得超过 10 亿美元融资的公司来说,这是很有意义的)。
RLHF
最近,从人类反馈(或偏好)中强化学习(RLHF(也称作 RLHP)已成为人工智能工具包的一个巨大补充。这个概念已经在 2017 年的论文《Deep reinforcement learning from human preferences》中提出。
最近,它被应用于 ChatGPT 和类似的对话智能体,如 BlenderBot 或 Sparrow。这个想法很简单:一旦语言模型被预先训练,用户就可以对对话生成不同的响应,并让人类对结果进行排序。人们可以在强化学习环境中使用这些排名(也就是偏好或反馈)来训练奖励(见图 3)。
扩散
扩散模型已经成为图像生成中的新 SOTA,显然将之前的方法如 GANs(生成对抗网络)推到了一边。什么是扩散模型?它们是一类经过变分推理训练的潜变量模型。以这种方式训练的网络实际上是在学习这些图像所代表的潜在空间(参见图 4)。
扩散模型与其他生成模型有关系,如著名的 [生成对抗网络 (GAN)] 16,它们在许多应用中已经被取代,特别是与(去噪)自动编码器。有些作者甚至说扩散模型只是自编码器的一个具体实例。然而,他们也承认,微小的差异确实改变了他们的应用,从 autoconder 的潜在表示到扩散模型的纯粹生成性质。
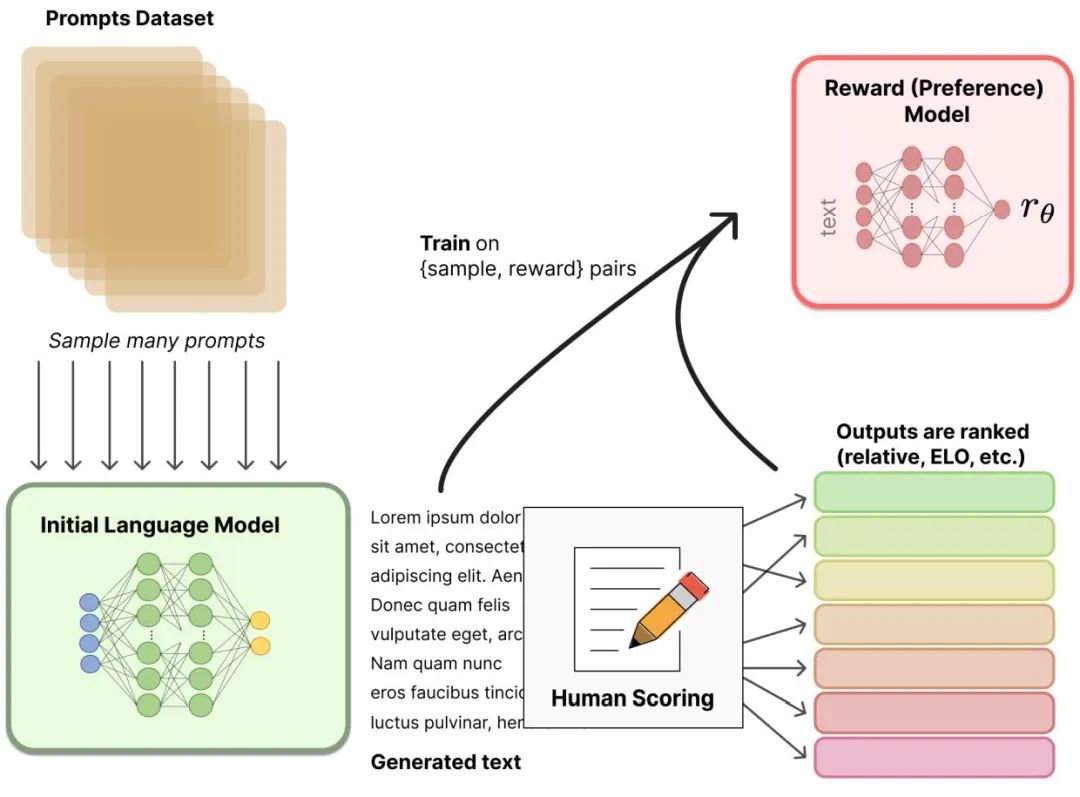
▲ 图3. 带有人类反馈的强化学习

▲ 图4. 概率扩散模型架构摘自《Diffusion Models: A Comprehensive Survey of Methods and Applications》
本文介绍的模型包括:




更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









