








©PaperWeekly 原创 · 作者 | 曾广韬
单位 | 新加坡设计科技大学
我们很高兴向大家分享我们在 ACL 2023 上发表的关于大模型、parameter-efficient transfer learning 方向的最新工作。

论文标题:
One Network, Many Masks: Towards More Parameter-Efficient Transfer Learning
论文链接:
https://arxiv.org/pdf/2305.17682.pdf
代码链接:
https://github.com/ChaosCodes/ProPETL
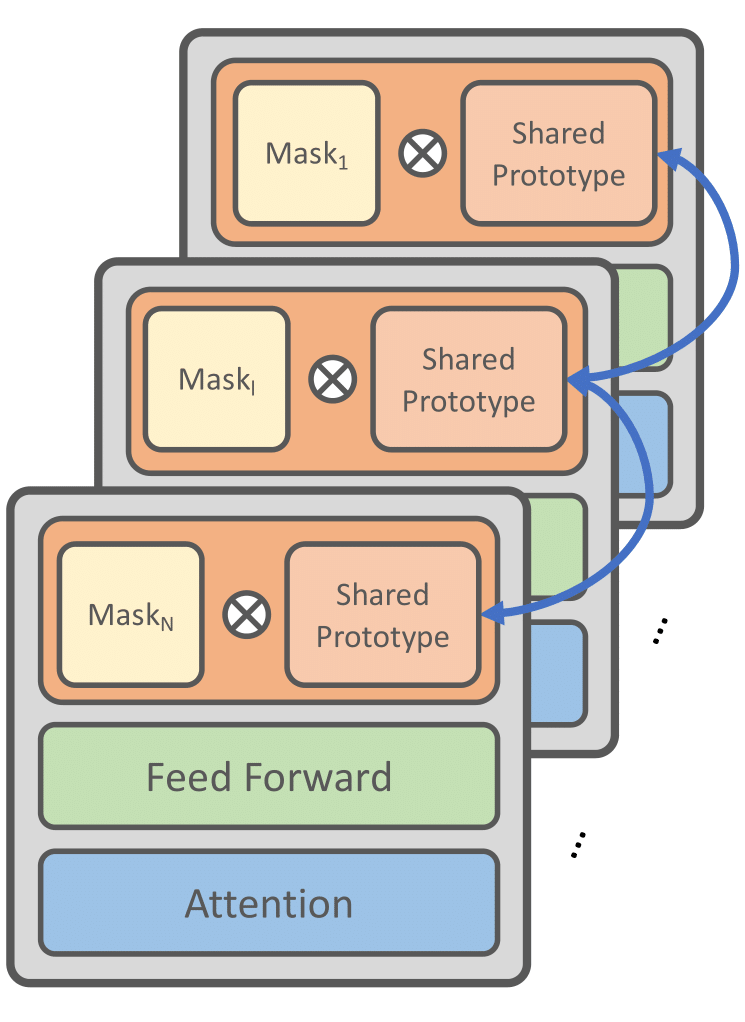

背景与动机
在深度学习领域,我们一直在寻找更有效的方法来提高模型的性能,同时降低计算和存储需求。我们的工作主要关注如何通过共享参数和掩码子网络的设计(也可以看作是一种剪枝操作)来提高模型的参数效率。
1.1 问题一:参数效率的挑战
在大型语言模型中,参数数量通常是巨大的,这不仅增加了计算和存储的需求,也可能导致过拟合等问题。因此,在 finetune 大型语言模型时, 许多 Parameter Efficient Transfer Learning(PETF)方法被提出。这些方法只需要更新很少一部分的额外参数, 节省了 finetune 时的显存以及存储需求。但是当下游任务变得越来越大的时候,计算和存储的需要也会变大从而很难应用在资源受限的环境。
于是我们希望找到一种方法,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2262
2262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









