







 本文介绍了CMB,一个全面的中文医疗模型评估基准,旨在通过选择题和临床诊断任务评估模型的医学知识和诊断能力。CMB包括CMB-Exam和CMB-Clin两个部分,分别针对模型的医学知识掌握和临床应用能力。实验结果显示,尽管GPT-4在医学领域表现出色,但中文医疗模型仍有很大提升空间。CMB提供了一种有参考答案和评分标准的评估方式,有助于加速模型迭代和医学大模型的发展。
本文介绍了CMB,一个全面的中文医疗模型评估基准,旨在通过选择题和临床诊断任务评估模型的医学知识和诊断能力。CMB包括CMB-Exam和CMB-Clin两个部分,分别针对模型的医学知识掌握和临床应用能力。实验结果显示,尽管GPT-4在医学领域表现出色,但中文医疗模型仍有很大提升空间。CMB提供了一种有参考答案和评分标准的评估方式,有助于加速模型迭代和医学大模型的发展。

©PaperWeekly 原创 · 作者 | 王熙栋
单位 | 香港中文大学(深圳)& 深圳市大数据研究院
研究方向 | NLP、医疗AI
近期,中文医疗大模型研发如火如荼,出现了很多有影响力的工作(BenTsao [7],MedicalGPT [4],Med-ChatGLM [5],HuatuoGPT [1] 等)。但是因为缺乏标准化的基准,进步的量化与模型的进一步迭代方向变得模糊。CMB 从临床医学工种职业发展过程中的真实考核出发,通过选择题和复杂病历问诊任务对模型医学知识和诊断能力进行了全面评估。我们真诚地希望,CMB 基准可以给医学大模型开发者提供细粒度足够高的反馈,加快模型迭代速度,推动中文医学领域语言模型进一步发展和应用。

论文题目:
CMB: A Comprehensive Medical Benchmark in Chinese
论文链接:
https://arxiv.org/abs/2308.08833
代码链接:
https://github.com/FreedomIntelligence/CMB
官网链接:
https://cmedbenchmark.llmzoo.com/

研究背景
医疗技术的进步极大地延长了人类的寿命。医学依赖于知识和经验,而语言模型依赖于数据,这种一致性给予了医学大模型帮助缓解医疗资源短缺的可能性。
虽然医学 LLM 应用前景广阔,模型的评估仍有许多挑战,在医院中部署 LLM 会带来重大的伦理问题,使得实际反馈变得困难。现有的模型评价通常使用自动评估(GPT-4),考虑到医疗的准确性和专业性要求,这种没有参考答案的评估欠缺说服力。而专业的人工评判昂贵而不易扩大规模。
BioLAMA 拥有参考答案,但它是为了评估掩码语言模型而不是自回归模型。MultiMedBench 包括问题解答、报告总结、视觉问题回答、报告生成和医疗图像分类,但 MultiMedBench 只有英文版本,直接翻译一方面需要对中英文医学和文化有深入了解,另一方面难以覆盖中医医学知识。
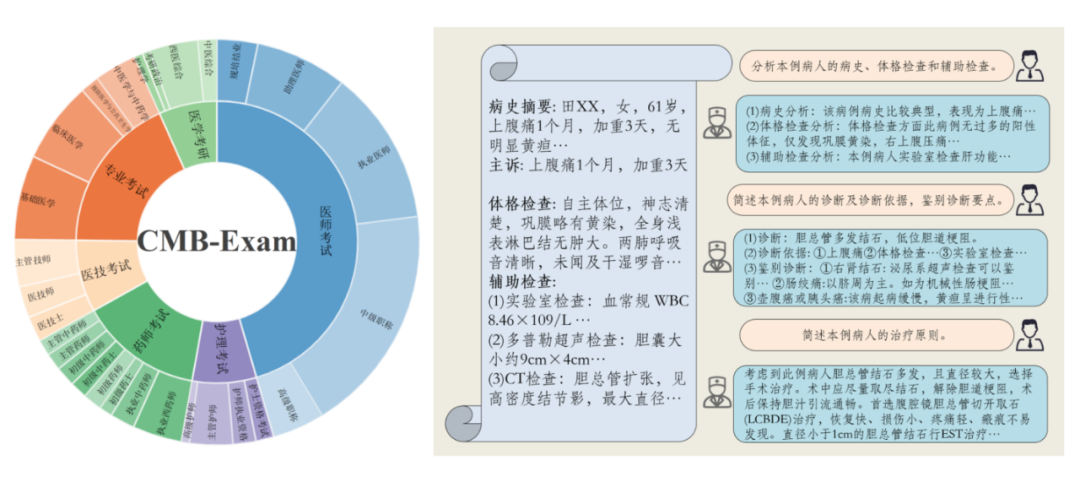
为此,我们提出了中文医疗模型评估基准 CMB,其包括了不同临床职业、不同职业阶段考试中的多项选择题(CMB-Exam)和基于真实病例的复杂临床诊断问题(CMB-Clin)。通过测评实验,我们发现:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









