







 研究提出了一种弱监督的Referring Image Segmentation(RIS)框架,仅使用文本描述作为监督信号,无需像素级标注。通过双向提示方法和校准策略,该框架在定位和分割目标对象方面表现与全监督方法相当,优于现有弱监督方法。此方法有望简化视觉任务,利用自然语言描述即可完成图像分割等任务。
研究提出了一种弱监督的Referring Image Segmentation(RIS)框架,仅使用文本描述作为监督信号,无需像素级标注。通过双向提示方法和校准策略,该框架在定位和分割目标对象方面表现与全监督方法相当,优于现有弱监督方法。此方法有望简化视觉任务,利用自然语言描述即可完成图像分割等任务。


论文链接:
https://arxiv.org/pdf/2308.14575.pdf
代码链接:
https://github.com/fawnliu/TRIS
基本概念:Referring Image Segmentation(RIS)是一种图像分割技术,旨在根据自然语言表达来标记图像或视频中表示对象实例的像素。也就是根据自然语言描述来实现图像分割。
与一般图像分割的区别:RIS 可以通过自然语言引导对不同对象进行分割,例如,有一张包含两只猫的图片,一只黑猫和一只白猫。一般图像分割模型会将两只猫都标记为“猫”,而不进行更精细的区分。但在 RIS 中,如果给定参考表达式“白色的猫”,模型将仅标记白色的猫。
问题:RIS 图像分割技术的 label,除了分割对象的自然语言描述,还需要大量的像素级标注,而像素级标注成本相当高。限制了 RIS 技术的发展。
解决方案:提出一个新的弱监督 RIS 框架,只使用文本描述监督情况下,实现与现有完全监督 RIS 方法相当的表现,且优于最新的弱监督方法。
前景展望:视觉语言大模型已有长足发展,已有很多视觉语言大模型可以进行 VQA 或者对图像进行结构化问答,如果按照本文思路,后续可能的应用:给一个数据集,一个描述,视觉语言大模型就可以返回你想要的结果,比如框,前景 mask 等。
比如你正在做手势识别项目,拍摄了大量手势相关图像,将图像输入给视觉语言大模型,给视觉语言大模型一个 prompt:请输出所有图像中的手部框,手部 mask。视觉语言大模型就端到端返回你想要的结果。再多想一层:如果算力够的话,是不是就不需要专门的检测分类分割之类的图像处理任务,只通过自然语言描述就可以实现想要的任何图像任务结果?

图 1 所示,本文方法可以准确地定位目标对象并生成分割图。尽管它只使用文本描述进行训练,但结果与完全监督方法相当。本文主要贡献如下:
提出了一种新的弱监督 RIS 框架,它只使用现成可用的文本语言进行监督,不需要任何额外标注。
本文的框架有三个主要的技术创新点。首先,提出双向提示方法来协调视觉和语言特征的域差异。其次,提出校准方法来提高响应图定位目标的正确性。最后,提出响应图选择策略来生成高质量的伪标签,用于目标对象的分割。
本文提出一种新的指标来评估定位精度。大量实验表明,本文框架与以前的完全监督 RIS 方法相比可以产生可行的结果,并且优于从相关任务改编的现有弱监督基线。

本文框架
弱监督 RIS 任务的主要目标是在没有像素级标注(使用框级标注,涂鸦,点,类别标签)的情况下建立图像内容与输入文本表达式之间的像素级关联。本文框架旨在通过学习对每个输入图像进行正样本文本和正样本文本的分类,从而学习根据正样本文本定位图像中的目标对象。正样本文本是用于描述输入图像目标对象的语言表达,而正样本文本是来自其他图像的语言表达。
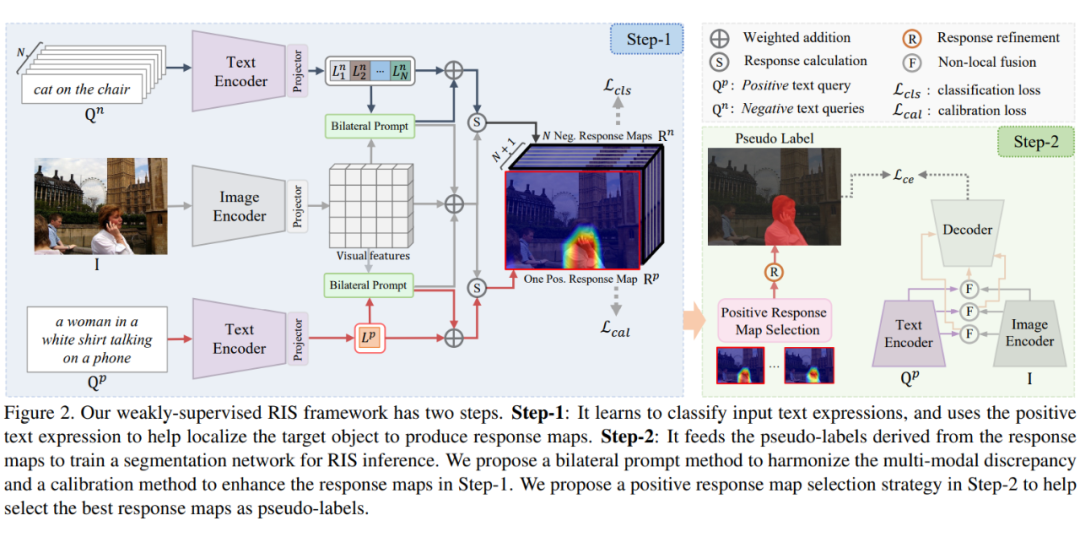
图 2 显示了本文的弱监督 RIS 框架,它分两个步骤。第一步对分类过程中的文本到图像响应建模,以帮助定位目标对象并产生响应图。本文在这一步中提出了双
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









