







最近在大型视觉-语言模型(LVLMs)上的进展使得语言模型能够处理多模态输入,但这需要显著的计算资源,特别是在端侧设备上进行部署。本研究旨在通过采用高质量训练数据,弥合传统规模 LVLMs 与轻量版本之间的性能差距。
为此,我们利用 GPT-4V 构建了一个高质量的合成数据集,包含(1)具有详细文本描述的图文对;和(2)复杂的推理指令和详细的答案。利用该训练数据,我们训练了一个轻量级的多模态模型 ALLaVA-3B,在同量级的 LVLMs 的 12 个 benchmark 中取得了有竞争力的性能。这项工作突出了采用高质量数据训练性能优异的轻量级 LVLMs 中的可行性。

论文题目:
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
论文链接:
https://arxiv.org/abs/2402.11684
数据链接:
https://huggingface.co/datasets/FreedomIntelligence/ALLaVA-4V
代码链接:
https://github.com/FreedomIntelligence/ALLaVA
Demo链接:
https://allava.freedomai.cn/#/

研究背景
近几个月来,大型视觉-语言模型(LVLMs)的发展迅速。这些模型能够处理视觉和文本输入,类似于人类在现实世界场景中处理信息的方式。一个 LVLM 通常由两个关键组件组成,即视觉编码器和大型语言模型(LLM)。
因此,LVLMs 不仅能够执行传统任务,如图像标题生成和图文检索,还能够遵循人类的指令执行复杂的视觉问答(VQA)任务,使它们成为通往人工通用智能(AGI)的一个里程碑。
尽管 LVLMs 展现出了卓越的能力,它们通常需要大量资源来进行训练和部署。为了使 LVLMs 方便部署,一些工作致力于开发轻量级 LVLMs。尽管这些模型对于计算资源较少的用户更加友好,但在某种程度上,它们伴随着性能的损失,这表现在常规尺寸 LVLMs 与轻量级版本之间存在性能差距。
遵循“输入决定输出”原则,我们的方法从数据中心的角度重新评估多模态语言模型。在这个框架内,我们专注于两个主要策略:“多模态对齐”和“视觉指令微调”。前者主要致力于帮助语言模型识别视觉对象并增强其视觉推理能力,后者着重于使 LVLMs 能够跨更广泛的指令泛化,特别是涉及视觉输入的指令。
现有工作通常使用 caption 数据来在语言模型中对齐图像和文本,但这些数据集由简短和粗粒度的 caption 组成,引入噪声信号并阻碍了视觉-语言对齐过程。此外,[1] 发现 COCO 图像-文本对的跨模态关联有限,这对在 COCO 基础上合成高质量数据的有效性提出了质疑。因此,我们需要一个更合理和可扩展的方法来获得高质量的caption数据。
与此同时,对齐数据的规模,尤其是高质量数据的规模,则相对有限。这在泛化到更广泛的长尾视觉知识方面存在挑战。扩大对齐数据的数量,特别是来自多样化来源的数据,对于实现对长尾视觉知识的细致理解至关重要。
视觉指令微调数据同样存在不足。当前的视觉指令调整数据集(如 Vision-FLAN,OCRVQA,TextVQA)更多地关注于提高基础能力,而不是更高级的能力,如复杂推理。此外,尽管 Vision-FLAN 中的答案是由人工标注的,但它们通常由短语或短句组成,且没有格式提示。直接学习这样的输出将阻碍模型性能,因此我们需要改善或重新生成指令的答案。

数据集生成
2.1 图像来源
我们为数据合成选择了两个图像来源:Vision-FLAN(简称 VFLAN)和 LAION。我们选择前者是因为这些图像与近 200 个任务的多样化指令相关联。选择后者是因为它来自“野生”互联网的自然图像,且图像来源足够多样;此外,图像来源也与终端用户的实际用途保持一致。
LAION 是一个流行的视觉-语言对齐数据集,因为它包含从网页爬取的多样化图像。为了确保图像质量,我们只下载短边分辨率至少为 512 的图像。
Vision-FLAN 是一个整合了 101 个开源数据集中 191 个 VQA 任务的数据集。它包含了对提高 LVLMs 基础能力和提升传统 benchmark 表现至关重要的指令。
2.2 使用“先标注后问答”方式进行数据合成
为了生成高质量的 caption 和视觉问答(VQA),我们提出在单个会话中为一张图像生成一个 Caption 和一个问答对,详见图 1。具体来说,我们使用图像提示 GPT-4V,要求它首先生成一个细粒度的 caption,然后是一个 VQA 对。通过这样做,整个数据合成过程包括三个阶段:描述、提问和回答。
描述:GPT-4V 需要生成尽可能详细的图片描述,用于视觉语言的模态对齐。
提问:GPT-4V 根据图片生成复杂推理问题。
回答:GPT-4V 根据图片、描述和问题生成详细的答案。
为了避免潜在的伦理问题,我们 prompt 里提示 GPT-4V 拒绝为相关图片生成图片描述,同时避免生成带有偏见的答案。
在 VQA 场景中,加入额外的图片描述是有益的。补充的图片描述可以被视为额外的上下文,有助于提高答案质量并减少幻觉现象。通过利用额外的信息,模型获得对视觉和文本组件的全面理解,从而改善其提供准确和情境相关回应的能力。此外,由于提供了更多的上下文,它可能减轻幻觉问题。

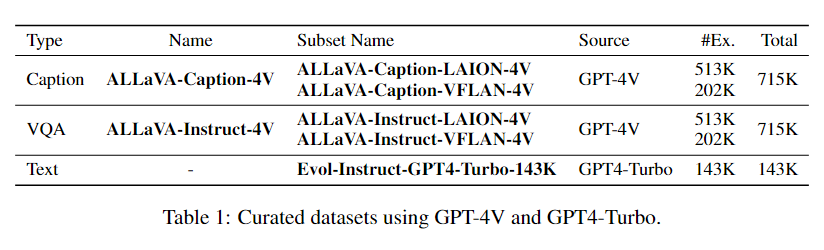
2.3 数据集卡片
为了缓解模型的文本灾难性遗忘问题,我们也使用 GPT-4-Turbo 重新生成了 WizardLM 指令数据集 [2] 的回答部分。
我们将 ALLaVA-4V 数据集的名称、来源及样本量汇总在表 1 中。图片数量达 700K,总样本量(包括文本数据)达 1.5M,是目前最大的用于 LVLM 训练的开源高质量 GPT-4V 数据集。
2.4 数据集样例


实验
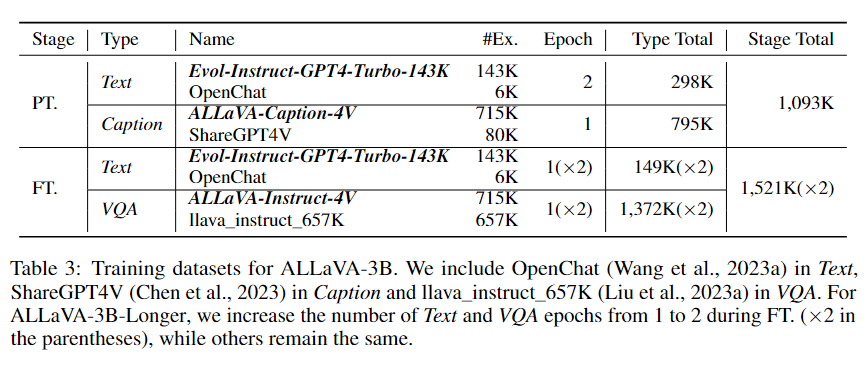
我们以 Phi-2 作为语言模型基座,采用两阶段训练。如表 3 所示,预训练阶段,我们选用 Evol-Instruct-GPT4-Turbo-143K 和 OpenChat [3] 组成纯文本数据,ALLaVA-Caption-4V 和 ShareGPT4V [4] 组成对齐数据;视觉语言指令微调阶段,除了文本数据,我们用 ALLaVA-Instruct-4V 和 llava_instruct_657K [5] 组成指令数据。
我们推出两个模型:ALLaVA-3B 和 ALLaVA-3B-Longer。两个模型的区别仅在第二阶段,后者比前者多训练一个 epoch。
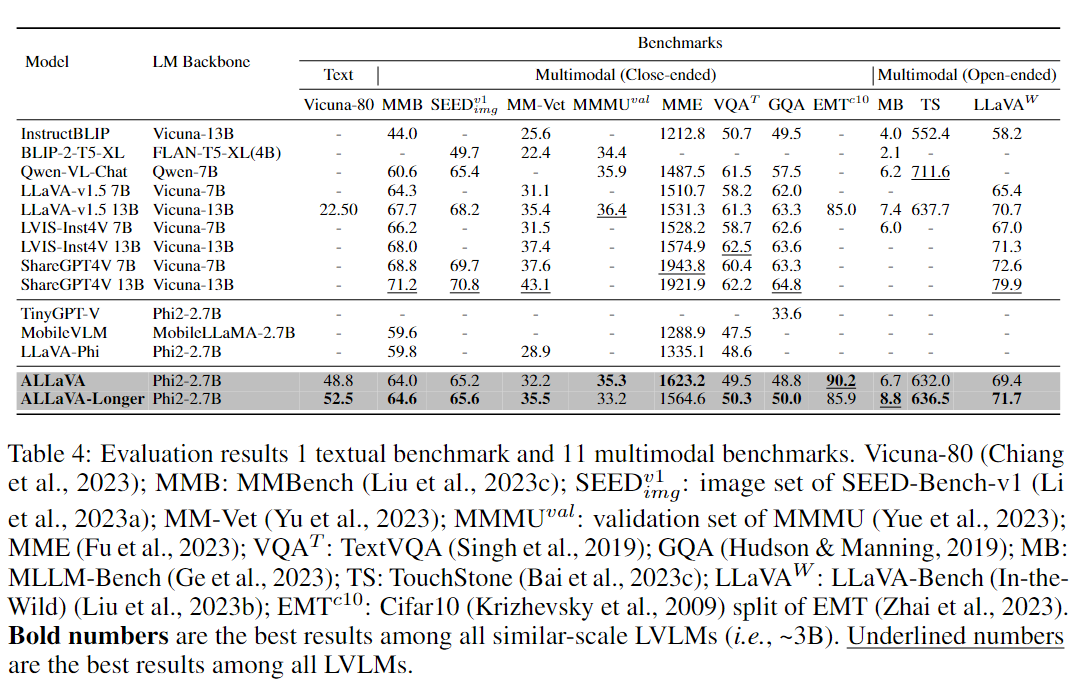
3.1 Benchmark结果
我们的模型展示了卓越的语言能力,在 Vicuna-80 上获得了 52.5% 的胜率,超过了 LLaMA2-7B-Chat 提供的 anchor 答案。这个结果也大幅超过了 LLaVA-v1.5-13B,这表明我们文本数据的高质量以及从 base 模型构建 LVLM 的有效性。
对于多模态能力,我们根据答案的形式将我们的 benchmark 分为多项选择或简答(8 个 benchmark)和自由形式生成(3 个 benchmark)。
对于多项选择或简答 benchmark,ALLaVA-3B 在 MMB、SEEDBench、MM-Vet、MME 和 GQA 上大幅超过了同规模的 LVLMs。ALLaVA-3B-Longer 甚至在 MM-Vet、MME 和 EMT 上超过了 LLaVA-v1.5-13B,尽管其参数只有后者的 25%。
对于自由形式生成 benchmark,ALLaVA-3B-Longer 在用于探测复杂推理能力 MLLM-Bench上 实现了 8.8% 的 SOTA 胜率。它在 TouchStone 和 LLaVA(In-the-Wild)上的表现也与 LLaVA-v1.5-13B 相当。
3.2 定性结果展示
我们提供了两个示例,并比较了 ALLaVA-3B 与其他模型(包括 GPT-4V、LLaVA-v1.5-13B 和 LLaVA-v1.6-13B)的生成结果。
示例 1 测试了模型对幽默理解的能力。这四个模型都能够对图片进行的描述,捕捉到松鼠和鸟的姿态并识别它们各自的角色并分析幽默的原因。
示例2测试了检测情绪的能力。ALLaVA-3B、GPT-4V 和 LLaVA-v1.6-34B 对女性的面部表情及其潜在情绪的判断是一致的。然而,LLaVA-v1.5-13B 只给出了粗略的描述,并声称她正在看向相机,但实际上并非如此。
在这两个示例中,仅有 3B 参数的 ALLaVA 能够与更大模型达到相似的性能,展示了它从高质量训练集中获得的卓越推理能力。


总结
在这项工作中,我们提出了一个框架,同时生成高质量的 caption、视觉指令和答案。这是一种用于获取更多的 LVLM 训练数据的可扩展的方法。使用我们合成的数据集,我们训练了我们的模型 ALLaVA-3B,该模型在 3B 规模 LVLMs 的 12 个 benchmark 中取得了有竞争力的性能,并且在一些 benchmark 中与更大的 SOTA 模型如 LLaVA-v1.5-13B 的性能相当。
我们的数据可以显著缩小轻量级 LVLMs 与常规尺寸 LVLMs 之间的性能差距。我们向研究社区开源我们的模型和数据,以更好地推动这一领域的发展。

参考文献
[1] Parekh, Zarana, et al. "Crisscrossed captions: Extended intramodal and intermodal semantic similarity judgments for MS-COCO." arXiv preprint arXiv:2004.15020 (2020).
[2] Xu, Can, et al. "Wizardlm: Empowering large language models to follow complex instructions." arXiv preprint arXiv:2304.12244 (2023).
[3] Wang, Guan, et al. "Openchat: Advancing open-source language models with mixed-quality data." arXiv preprint arXiv:2309.11235 (2023).
[4] Chen, Lin, et al. "Sharegpt4v: Improving large multi-modal models with better captions." arXiv preprint arXiv:2311.12793 (2023).
[5] Liu, Haotian, et al. "Improved baselines with visual instruction tuning." arXiv preprint arXiv:2310.03744 (2023).
更多阅读



#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









