








一、结论写在前面
模型规模的庞大及训练和推理成本的高昂,限制了MLLMs在学术界和工业界的广泛应用。因此,研究高效轻量级的MLLMs具有巨大潜力,特别是在边缘计算场景中。
论文深入探讨了高效MLLM文献的领域,提供了一个全面的视角,涵盖了其核心主题,包括基础理论及其扩展。论文的目标是识别并强调需要进一步研究并提出未来研究可能的方向。论文旨在提供一个关于高效MLLM当前状态的全面视角,希望能够激发更多的研究。鉴于该领域的动态性,可能有些最新的发展并未被完全覆盖。为此,论文建立了一个专门的网站,利用众包来跟上最新的进展。该平台旨在作为持续更新的信息源,促进该领域的持续增长。
更多细节请参考论文的GitHub仓库:https://github.com/jiannuist/Efficient-Multimodal-LLMs-Survey。
二、论文的简答介绍
2.1 论文的背景
大型语言模型(LLM)的卓越能力激发了将其与其他基于模态的模型结合,以增强多模态能力的研究。OpenAI的GPT-4V和Google的Gemini等专有模型的成功进一步支持了这一概念。因此,多模态大型语言模型(MLLMs)应运而生,包括mPLUG-Owl系列、InternVL、EMU、LLaVA、InstructBLIP、MiniGPT-v2和MiniGPT-4。这些模型通过有效利用各模态的预训练知识,避免了从头开始训练的高计算成本。MLLMs继承了LLMs的认知能力,展现出如强大的语言生成和迁移学习能力等众多显著特性。通过与其他基于模态的模型建立强大的表征联系和校准,MLLMs能够处理来自多种模态的输入,显著拓宽了其应用范围。
MLLMs(多模态大型语言模型)的成功在很大程度上归功于scaling law:随着投入更多的资源,如数据、计算能力或模型大小,AI模型的性能会得到提升。然而,可扩展性伴随着高资源需求,这阻碍了大型模型的发展和部署。例如,根据NVIDIA A100 GPU的计算,MiniGPT-v2的训练需要总共超过800个GPU小时。这带来了巨大的费用,对于大型企业之外的研究人员来说是难以承受的。除了训练之外,推理构成了MLLM中资源消耗的主要部分。考虑一个典型场景,模型输入包含一个336 x 336像素的图像和一个包含40个token的文本提示,使用LLaVA-1.5和Vicuna-13B LLM骨干进行推理需要18.2T FLOPS和41.6G的内存使用。大型模型资源密集型的特性也引发了关于民主化和隐私保护的担忧,考虑到当前主流的MLLMs,如GPT-4V和Gemini,由少数主导企业控制,并在云中运行。如前所述的实验所示,即使是开源的MLLMs,对计算资源的高要求使得在边缘设备上运行它们变得具有挑战性。这进一步加剧了确保公平访问和保护用户隐私的挑战。
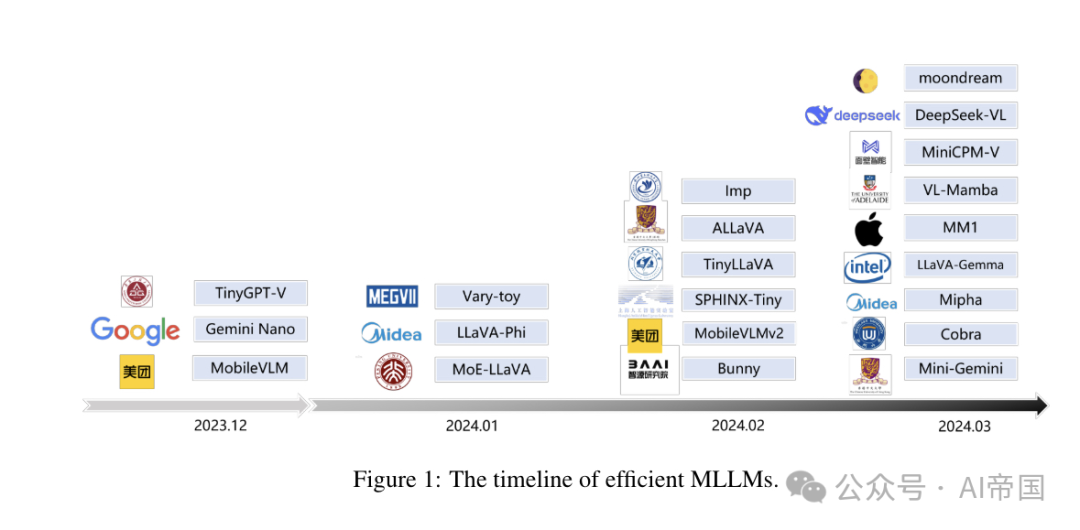
图1:高效MLLMs的时间线
鉴于这些挑战,对高效多模态大型语言模型(MLLMs)的研究越来越受到关注。这些努力的主要目标是减少MLLMs的资源消耗,同时扩大其适用性并最小化性能下降。高效MLLMs的研究始于用轻量级模型替换大型语言模型,并进行典型的视觉指令调整。随后的研究通过以下方式进一步增强能力和扩展应用场景:(1) 引入了更轻量级的架构,重点在于效率,旨在减少参数数量或计算复杂度;(2) 开发了更专业的组件,专注于针对高级架构的效率优化或赋予特定属性,如局部性;(3) 支持资源敏感型任务,一些工作采用视觉token压缩来提升效率,使得MLLM能力能够转移到如高分辨率图像和视频理解等资源密集型任务。
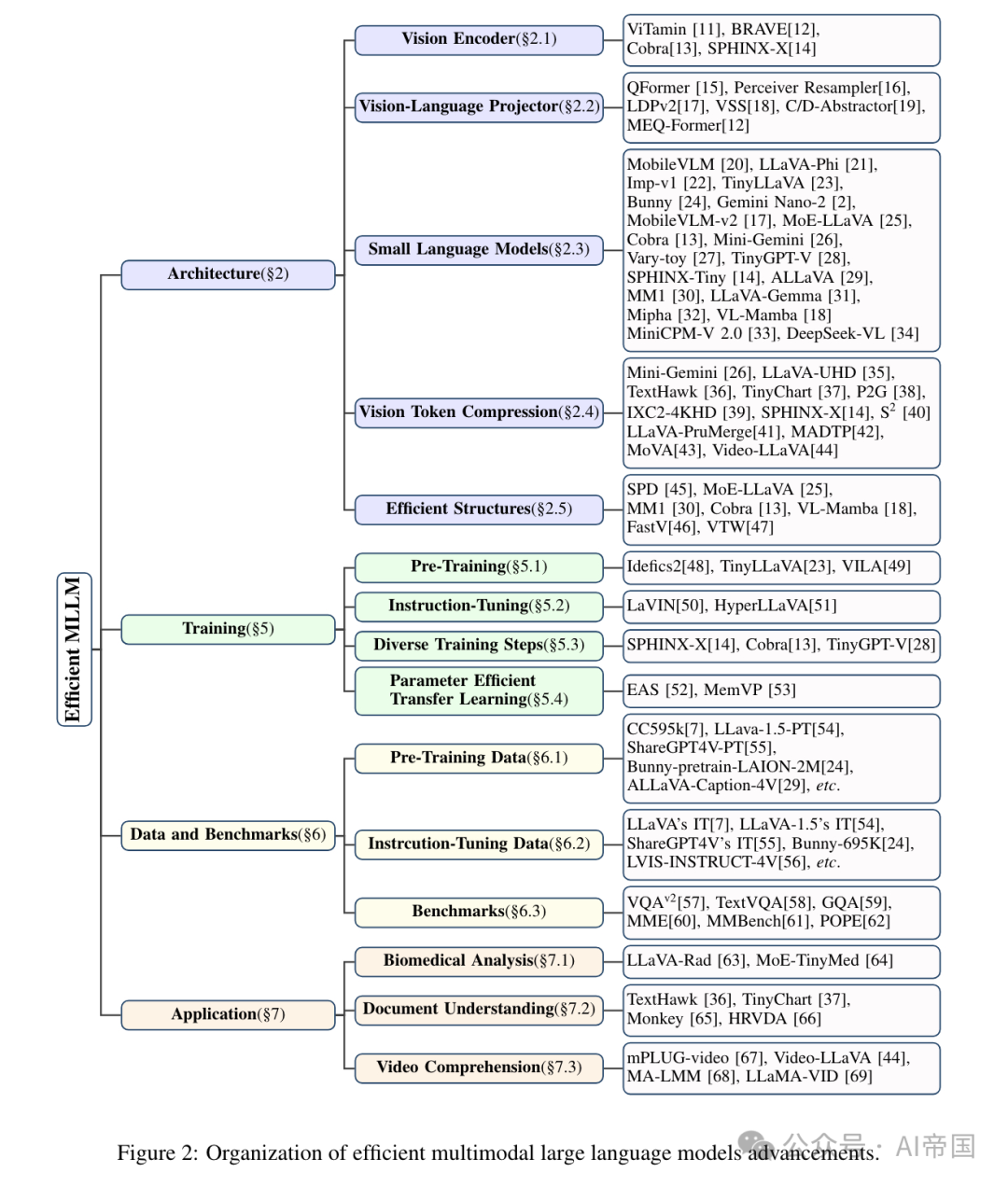
图2:高效多模态大型语言模型进展的组织结构 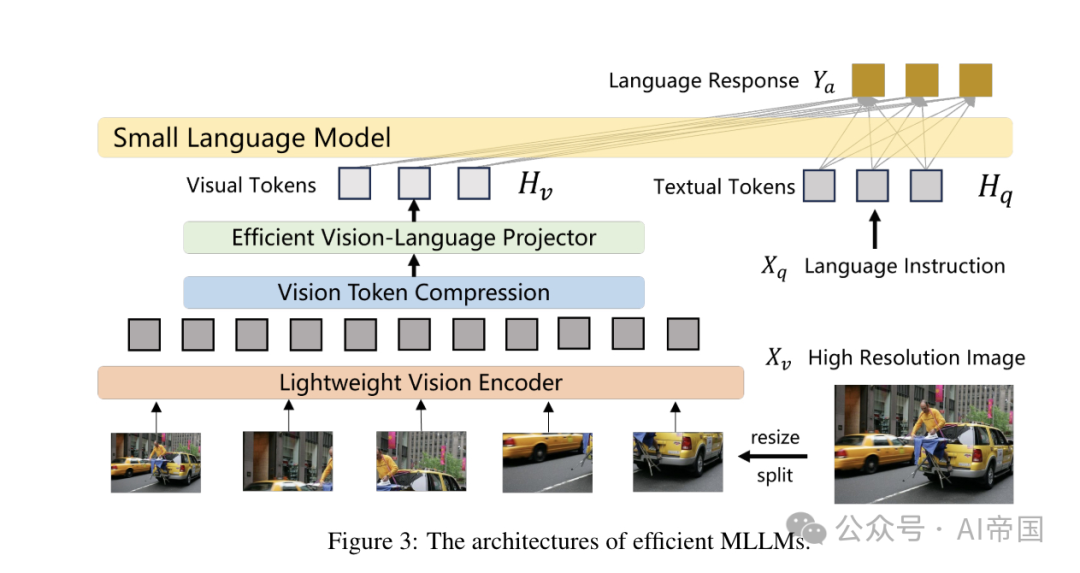 图3展示了高效多模态大型语言模型(MLLMs)的架构
图3展示了高效多模态大型语言模型(MLLMs)的架构
2.2 架构
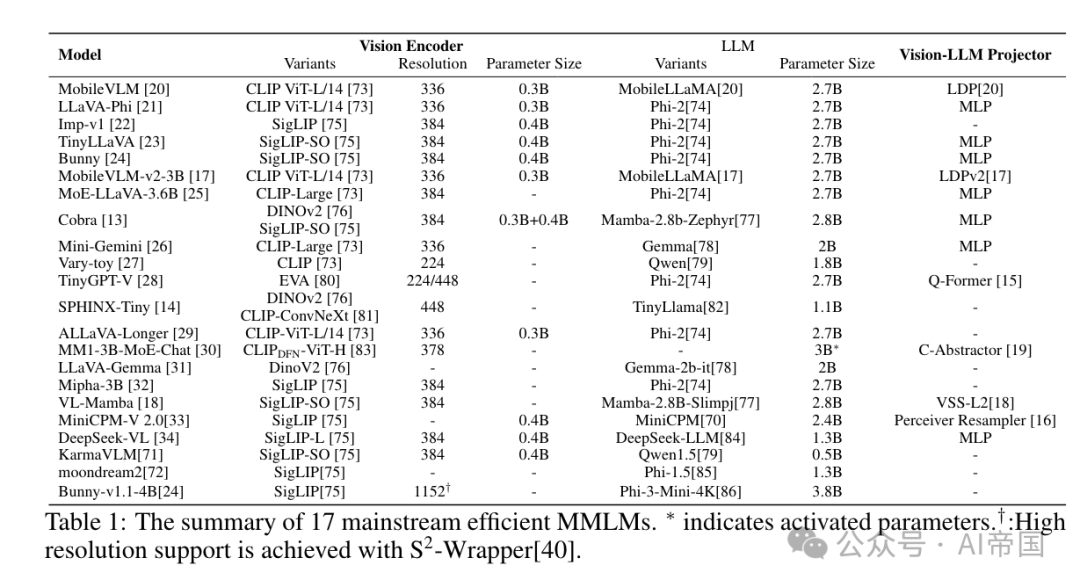
遵循标准MLLM框架,高效MLLMs可以分为三个主要模块:负责接收和处理视觉输入的视觉编码器g,管理接收的多模态信号并执行推理的预训练语言模型,以及作为连接两种模态桥梁的视觉-语言投影器P。为了提高通用MLLMs的效率,主要的优化在于处理高分辨率图像,压缩视觉token,实施高效结构,以及利用紧凑型语言模型等策略。架构图如图3所示。表1概述了高效MLLMs的总结,包括基础LLM、视觉编码器、图像分辨率以及用于连接视觉和语言的投影器。这些高效MLLMs包括:MobileVLM 、LLaVA-Phi 、Imp-v1、TinyLLaVA 、Bunny 、Gemini Nano-2 、MobileVLM-v2 、MoE-LLaVA-3.6B、Cobra、Mini-Gemini、Vary-toy、TinyGPT-V、SPHINX-Tiny 、ALLaVA 、MM1-3B、LLaVA-Gemma、Mipha-3B、VL-Mamba、MiniCPM-V2.0、DeepSeek-VL、KarmaVLM、moondream2。
2.2.1 视觉编码器
视觉编码器接收输入图像 ,将其压缩为更紧凑的图像块特征。
高效MLLM通常继续采用在大规模MLLM中广泛使用的视觉编码器,如表1所述*
多个视觉编码器:在图4中的BRAVE对处理多模态大型语言模型(MLMM)任务的各种视觉编码器及其不同的归纳偏置进行了广泛的消融研究。结果表明,没有单一的编码器设置能在不同任务中始终表现出色,具有多样偏置的编码器可以产生出乎意料相似的结果。可以推测,整合多个视觉编码器有助于捕捉广泛的视觉表示,从而增强模型对视觉数据的理解。Cobra将DINOv2和SigLIP作为其视觉主干,理由是结合DINOv2提供的低级空间特征和SigLIP提供的语义属性将提升后续任务的性能。SPHINX-X[14]采用两个视觉编码器——DINOv2和CLIP-ConvNeXt。鉴于这些模型通过不同的学习方法(自监督与弱监督)和网络架构(ViT与CNN)进行了预训练,它们自然能够提供最互补和复杂的视觉知识。
轻量级视觉编码器:ViTamin代表了一种轻量级视觉模型,专为视觉和语言模型定制。它以卷积基座开始,随后在第一和第二阶段采用移动卷积块,第三阶段则使用Transformer块。值得注意的是,拥有436M参数的ViTamin-XL达到了82.9%的ImageNet零样本准确率,这一成绩优于EVA-E[80]的82.0%准确率,后者以4.4B的参数规模运行,参数数量是其十倍。简单地将LLaVA的图像编码器替换为ViTamin-L,就能在多种MLLM性能指标上树立新标准。
2.2.2 视觉-语言投影器
视觉-语言投影器的任务是将视觉补丁嵌入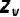 映射到文本特征空间。
映射到文本特征空间。
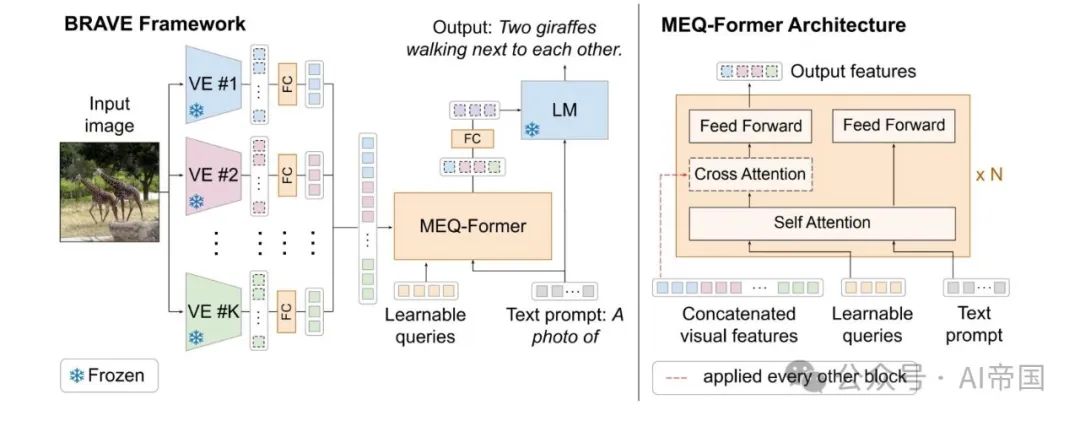 图4展示了BRAVE [12] 如何将来自K个不同视觉编码器的特征以序列方式进行拼接。这些拼接后的特征随后被MEQ-Former缩减
图4展示了BRAVE [12] 如何将来自K个不同视觉编码器的特征以序列方式进行拼接。这些拼接后的特征随后被MEQ-Former缩减
基于MLP的方法,如[7, 54]所述,视觉-语言投影器通常通过直接可学习的线性投影器或多层感知机(MCP)实现,即几个线性投影器与非线性激活函数交错,如表1所示。
基于注意力的BLIP2 [15] 引入了Q-Former,一种轻量级transformer,它使用一组可学习的查询向量从冻结的视觉模型中提取视觉特征。Flamingo[16]提出的Perceiver Resampler考虑使用可学习的潜在查询作为交叉注意中的Q,同时图像特征被展开并与Q拼接,作为交叉注意中的K和V。通过这种方式,transformer在可学习潜在查询对应位置的输出被视为视觉特征的聚合表示,从而将可变长度的视频帧特征标准化为固定大小的特征。BRAVE [12] 中的MEQ-Former设计了一个多编码器查询transformer,将来自多个冻结视觉编码器的特征融合成一种通用表示,该表示可以直接输入到冻结的语言模型中。
基于CNN的MobileVLMv2[17]提出了LDPv2,一种新的投影器,包含三个部分:特征变换、token缩减和位置信息增强。通过使用逐点卷积层、平均池化和带有跳跃连接的PEG模块,LDPv2实现了更高的效率,参数减少了99.8%,并且处理速度略快于原始的LDP[20]。
基于Mamba的VL-Mamba[18]在其视觉-语言投影器中实现了2D视觉选择性扫描(VSS)技术,促进了不同学习方法的融合。VSS模块主要解决了1D序列处理与2D非因果视觉信息之间的不同处理方法。
混合结构蜜蜂[191]提出了两种视觉投影器,即C-抽象器和D-抽象器,它们遵循两个主要设计原则:(1) 在视觉token数量上提供适应性,以及(ii) 高效地维护局部上下文。C-抽象器,或称卷积抽象器,通过采用卷积架构,专注于熟练地建模局部上下文。该结构由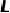 个ResNet块组成,随后是自适应平均池化和额外的个ResNet块,这有助于将视觉特征抽象为任意平方数量的视觉token。相反,D-抽象器,或基于可变形注意的抽象器,使用可变形注意,通过基于2D坐标的采样过程,利用参考点和采样偏移量来维护局部上下文。
个ResNet块组成,随后是自适应平均池化和额外的个ResNet块,这有助于将视觉特征抽象为任意平方数量的视觉token。相反,D-抽象器,或基于可变形注意的抽象器,使用可变形注意,通过基于2D坐标的采样过程,利用参考点和采样偏移量来维护局部上下文。
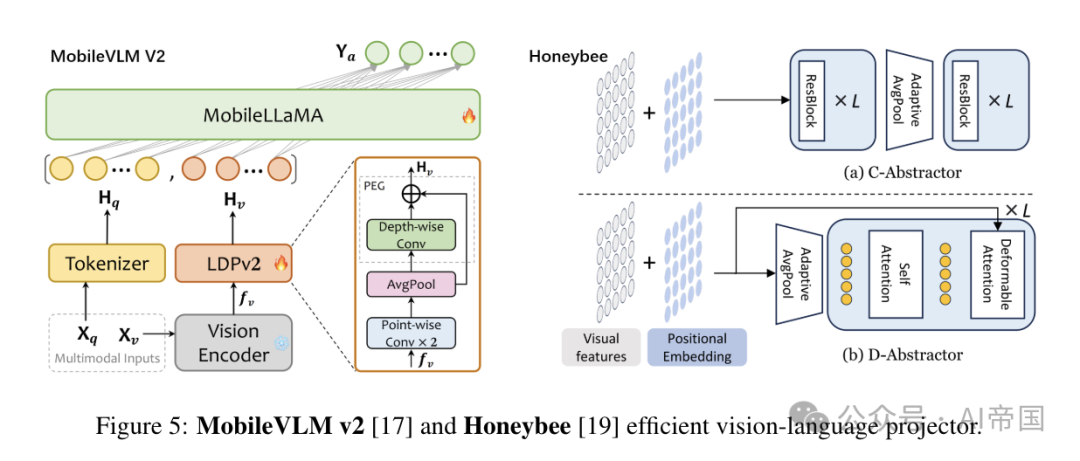
图 5:MobileVLM v2 [17] 和 Honeybee [19] 的高效多模态语言投影器。
2.2.3 小型语言模型
由于SLM贡献了MLLM参数的绝大部分,其选择与MLLM的轻量级特性密切相关。与参数规模从70亿到数百亿的传统MLLMs[87, 88]相比,高效MLLMs通常采用参数少于30亿的语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









