







 本文总结了大模型时代的表格推理技术,包括有监督微调、结果集成、上下文学习、指令设计和逐步推理,分析了LLM在表格推理任务上的优势,并探讨了未来发展方向,如多模态、多轮对话和检索增强生成。
本文总结了大模型时代的表格推理技术,包括有监督微调、结果集成、上下文学习、指令设计和逐步推理,分析了LLM在表格推理任务上的优势,并探讨了未来发展方向,如多模态、多轮对话和检索增强生成。

©PaperWeekly 原创 · 作者 | 张玄靓
单位 | 哈尔滨工业大学
研究方向 | 自然语言处理、表格推理

介绍
表格推理(Table Reasoning)任务要求模型根据给定表格完成用户的要求(如图 1 所示,包括表格问答、表格事实判断等)。表格推理在自然语言处理(Natural Language Processin, NLP)领域是一项重要的任务,它显著提升了人们从大量表格中获取和处理数据的效率。
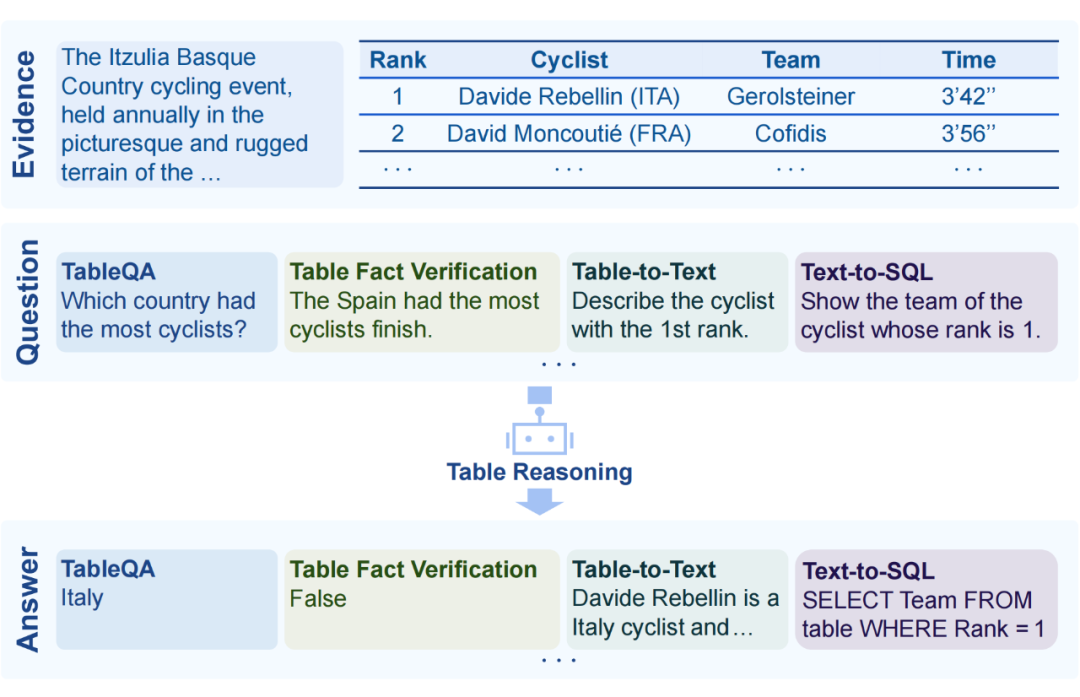
▲ 图1:不同表格推理任务的解释
过去表格推理的研究大致经过了基于规则、基于神经网络以及基于预训练模型几个阶段 [1],我们称之为前大模型时代。最近的研究 [2] 表明,大规模语言模型(Large Language Model,LLM)在各个 NLP 任务上都表现出了引人注目的性能,并且极大减少了标注需求,我们称之为大模型时代。因此,已经有许多工作将 LLM 应用到表格推理任务上,其性能超过了前大模型时代的方法,成为了目前的主流方法。
然而,目前缺乏关于 LLM 表格推理工作的总结分析,导致如何进一步提升性能仍有待研究,一定程度阻碍了现有研究。而基于前大模型的总结分析不适用于 LLM,因为一些前大模型时代的主流技术,例如改变模型结构和设计预训练任务不再适用于用 LLM 进行表格推理,LLM 时代的方法更关注如何设计 prompt 或 pipeline。
因此,本文总结了现有的用 LLM 进行表格推理的工作以促进未来研究。在本文中,我们主要讨论以下 3 个关于表格推理的问题:
1. LLM 时代什么技术可以提升表格推理性能?
2. 为什么 LLM 擅长表格推理?
3. 如何进一步提升模型的表格推理能力?
本篇综述的结构如图 2 所示。
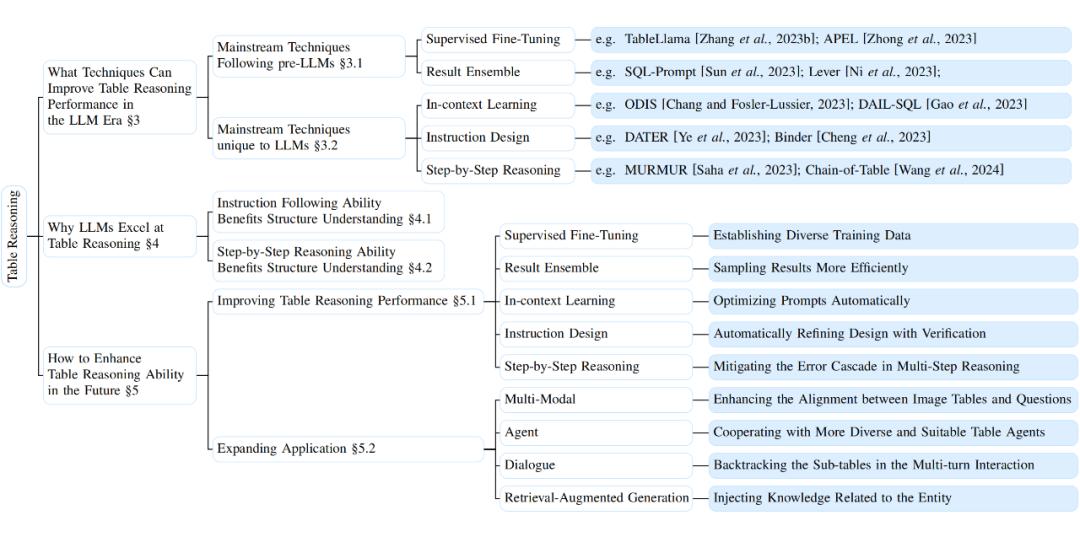
▲ 图2:本篇论文的结构总览,以最有代表性的工作举例
关于第一个问题,为了研究者更好地适应 LLM 时代的表格推理研究,我们在第 3 节展示了 LLM 时代表格推理的主流技术。关于第二个问题,我们在第 4 节从两个表格推理任务固有的挑战出发分析了 LLM 解决表格推理任务的优势。关于第三个问题,我们在第 5 节从如何进一步提升表格推理性能,以及如何探索实际应用中的表格推理任务两个角度讨论了表格推理研究未来潜在的方向。
本文是对综述《A Survey of Table Reasoning with Large Language Models》的翻译与总结,关于更详细的介绍与分析可以阅读原文,并且我们在 GitHub 中总结了现有相关研究的详细资源。

论文链接:
https://arxiv.org/abs/2402.08259
Github链接:
https://github.com/zhxlia/Awesome-TableReasoning-LLM-Survey

背景
2.1 论文选择标准
论文中要解决的问题至少要与一个表格相关。
论文中的方法需要使用 LLM 进行推理,或对 LLM 进行微调。
2.2 任务定义
在表格推理任务中,模型的输入包括表格和可选的文字描述,以及对应于不同任务的用户问题(比如,表格问答、表格事实验证、table-to-text 以及 text-to-SQL),输出则是对用户提出问题的回答。
2.3 相关数据集
尽管目前主流工作在使用 LLM 解决表格推理任务时,一般会使用基于上下文学习的方法来进行预测,而无需数据进行训练,但人们依然需要依赖标注数据,来验证 LLM 在解决表格推理任务时的性能。因此在这一小节,我们将针对四个目前主流的表格推理任务,分别介绍相关的主流数据集:
表格问答:根据表格回答问题。WikiTableQuestions [3] 数据集作为第一个表格问答类的数据集,由于其开放域的表格和复杂的查询问题,使得该数据集能够充分验证模型的表格问答能力;
表格事实验证:判断表格是否支持给定的文字假设。TabFact [4] 数据集作为第一个表格事实验证类的数据集,其大规模跨领域的表格数据和复杂的推理需求,可以有效检验模型在表格事实验证任务上的能力;
table-to-text:根据问题和表格生成对应的自然语言描述。ToTTo [5] 数据集通过高亮特定的表格内容生成相关描述,因其大规模高质量的表格数据及对应描述能很好地验证模型的 table-to-text 能力,而成为 table-to-text 任务的主流数据集;
text-to-SQL:将自然语言问题根据给定数据库转换成 SQL。Spider [6] 是第一个 text-to-SQL 任务上多领域、多表格的数据集,在 text-to-SQL 任务上被广泛使用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









