








©PaperWeekly 原创 · 作者 | 李文通
单位 | 浙江大学
研究方向 | 多模态、场景理解

引言
最近,多模态大模型(Multimodal LLM, MLLM)/(Large Multimodal Model, LMM)的研究更新速度令人目不暇接,开源模型逐渐朝着逼近与 GPT-4V/o 等闭源模型的性能前进。本工作针对多模态大模型中一个重要的模块-视觉映射器(Visual Projector)展开了探索与研究,提供了一个可以高质量压缩视觉 token 数量且性能表现优异的一种方法。
下面进行展开具体介绍。
典型的多模态大模型,采用线性映射 MLP 作为视觉映射器,其能够实现将视觉特征到 token 一对一地映射到文本空间, 从而有效地接入 LLM 中。然而,有没有更合适、更有效的结构形式来实现,是一个值得研究的问题。
其次,视觉 token 的个数对于多模态大模型效率起着重要作用,特别是大分辨率输入图像或视频场景,视觉 token 大幅增加,则将给 LLM 带来非常大的计算量。此外,简单的 MLP 作为视觉映射器产生的视觉 token 会存在一定的冗余视觉表示, 在最近的论文 LLaVA-PruMerge 中 [1] 也有相应的分析。因此,视觉映射器也起着视觉 token 压缩的关键作用来提升多模态大模型的效率。
目前对于视觉映射器,主要分为以下几种:
1. Resampler [2] or Q-former [3]:该方法通过引入可学习的 query 来自适应地来学习相关视觉表示,通过控制可学习 query 的个数来控制视觉 token 产生的数目。
2. 基于卷积的视觉映射器:典型的工作有 C-abstractor [4]、LDPv1/v2 [5], 通过引入卷积操作来建模局部视觉信息之间的关系,同时采用下采样减少视觉表示的长度。
3. 维度变换:将产生的视觉表示在 sequence 的维度变换到 channel 维度,如 PixelShuffle,虽然视觉信息没有减少但结构信息可能会被破坏。在 InternLM-XComposer2-4KHD [6] 与 InternVL 1.5 [7] 的研究工作均采用了类似的操作。此外,在研究工作 MM1 [8] 中,也对常用的几种 Visual Projector 进行实验验证与性能分析。
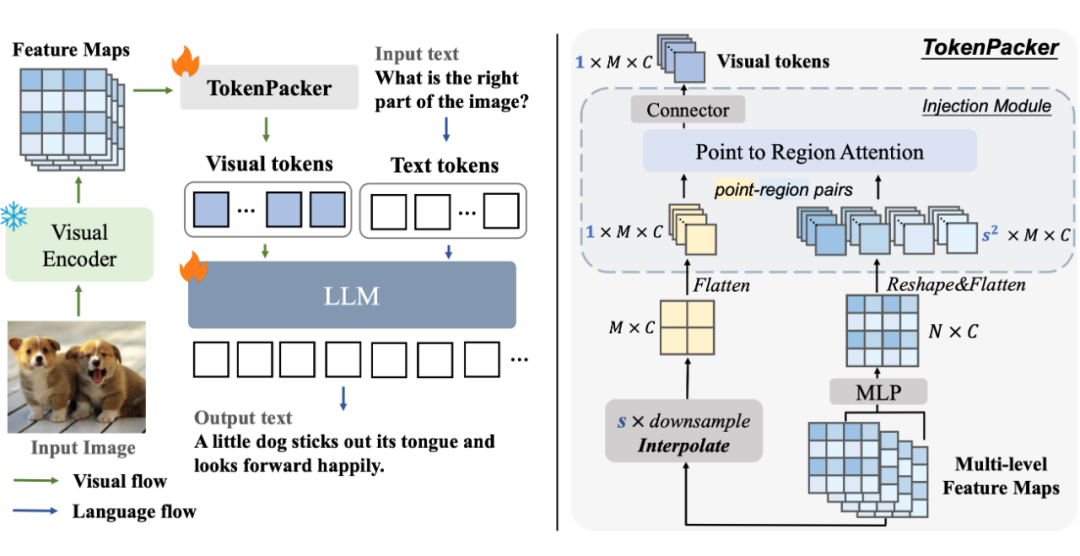
在本研究工作中,我们提出一种更有效的 Visual Projector 方法 - TokenPacker(寓意:对视觉特征信息进行打包,产生少而精的视觉 token 表示)。
首先,我们给出了在 llava-1.5 的相同 setting 下进行验证,对比分析了典型的几种视觉映射器。尽管现有的方法可以实现 token 数量的减少,但都会存在或多或少的性能下降,也就是其在视觉 token 压缩时存在信息损失。
本文的 TokenPacker 可以实现在压缩为 64(1/9)个 token 的情况下实现了与原始 LLaVA-1.5(576)相近的平均多模态性能表现,且模型的推理速度(TPS)大幅提升,TokenPacker 还可以进一步压缩至 32(1/16),甚至更少。
此外,我们也在大分辨率的设置下进行实验验证,在绝大多数的 benchmark 下领先目前典型的 Mini-Gemini-HD [9], LLaVA-NeXT [10] 等方法。
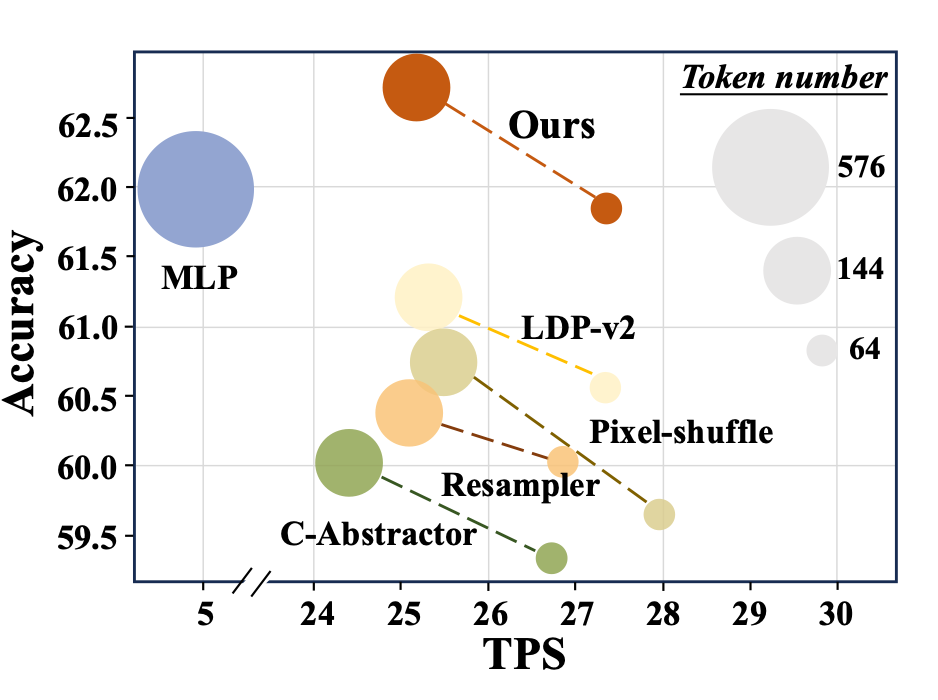
▲ 典型视觉映射器方法-精度与推理时间对比

具体方法
首先,我们分析了多模态大模型中视觉 token 个数是影响模型效率的重要因素;接着,详细介绍了 TokenPacker 具体过程;以及作为扩展,本文还提供了一种支持大分辨率输入图像的动态划分策略来高效实现多模态大模型对大输入分辨率的细粒度理解。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









