







如何突破多模态数据瓶颈?通义实验室提出多模态指令进化方法 MMEvol,实现感知进化、推理进化、交互进化三个维度的同步提升。
相较开源多模态 SOTA 模型,在 13 个权威多模态评测集上的 ACC 平均提升了 3%。

论文标题:
MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
论文作者:
林廷恩,罗润,刘雄,武玉川,黄非,李永彬
论文链接:
https://arxiv.org/abs/2409.05840
项目主页:
https://mmevol.github.io/home_page.html
代码链接:
https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/mmevol/mmevol_sft_data

背景
随着多模态大语言模型(MLLM)的快速发展,视觉推理、多模态智能体等应用取得了显著进展。然而,随着任务复杂度的提升,模型面临着严峻挑战,特别是在高质量开源图文指令数据匮乏的情况下,模型训练效果受到了明显限制。为解决这一瓶颈,传统方法依赖大量人工标注,但成本极高,难以大规模应用。
最近,阿里通义实验室联合中科院等机构,推出了多模态指令进化方法 MMEvol(MMEvol-Empowering Multimodal Large Language Models with Evol-Instruct)。
该方法通过多轮进化迭代,可自动提升图文指令数据的质量和数量,相较于全开源的 SOTA 模型 Cambrain-1-8B,仅使用了 1/4 不到的 SFT 数据,在 13 个权威多模态评测集上的 ACC 平均提升了 3%,验证了方法的有效性。

社区反馈
MMEvol 的代码和数据已开源,在学术界和工业界引起了广泛关注和讨论,获得了 HuggingFace Daily Paper 推荐。

在 Twitter 上引发了热烈的讨论与交流。

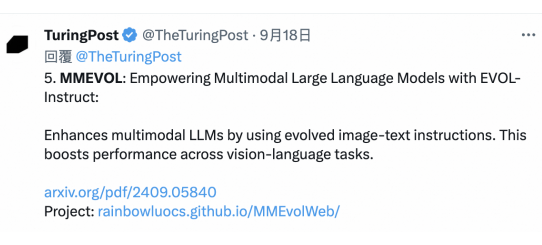



方法概述
图文指令数据存在的核心问题
现有的图文指令数据存在以下三个主要问题:
1. 指令形式单一:手工标注的指令往往局限于标注者的思维方式,难以涵盖多样化任务需求。模型生成的指令则依赖预设模板,难以做到无限扩展,从而限制了模型的指令跟随能力。
2. 指令复杂度不足:标注者多偏向于创建简单或中等难度的问题,而模型自动生成的指令常表现为简短回答,缺乏视觉推理步骤,使模型难以应对真实世界的复杂任务。
3. 图文对齐粒度不足:现有指令数据多关注图像中常见的主要物体,忽视了小型或少见的物体,导致在视觉物体的长尾分布中,尾部物体相关问题稀少,限制了模型的视觉感知和抗幻觉能力。
此外,文本指令进化在数学推理、代码生成等领域已被广泛应用,但在多模态领域仍存在挑战。主要难点在于:
1. 浅层推理现象:图像相关的问题往往比较基础,多次进化后,数据可能只是简单的重写,无法进行深度进化。
2. 视觉内容限制:语言中心的问题受限于图像内容,多次进化可能产生与图像无关的数据,无法有效拓展。
为克服上述瓶颈,作者提出了“多模态指令进化(MMEvol)”框架,旨在通过多轮自动迭代演化,提升图文指令数据的质量和多样性。
核心创新点:
作者设计了三种精细的进化方向,来解决上述问题:
1. 细粒度感知进化:关注图像细节和易被忽略的元素,生成更丰富的指令数据,提升模型的视觉感知能力和鲁棒性。
2. 推理认知进化:生成具有更长视觉推理链的复杂指令数据,提升模型的视觉推理能力,扩展其在复杂任务中的应用。
3. 交互进化:打破指令形式的限制,自动生成各种新颖的指令形式,覆盖真实世界中更多的任务需求,增强模型的指令跟随能力。
在方法实现上,作者将输入图像抽象为场景图,其中图像中的物体作为节点,每个节点具有属性,节点之间的连接代表其相对关系。通过在场景图上进行不同的进化操作,从而生成多样化的指令数据。
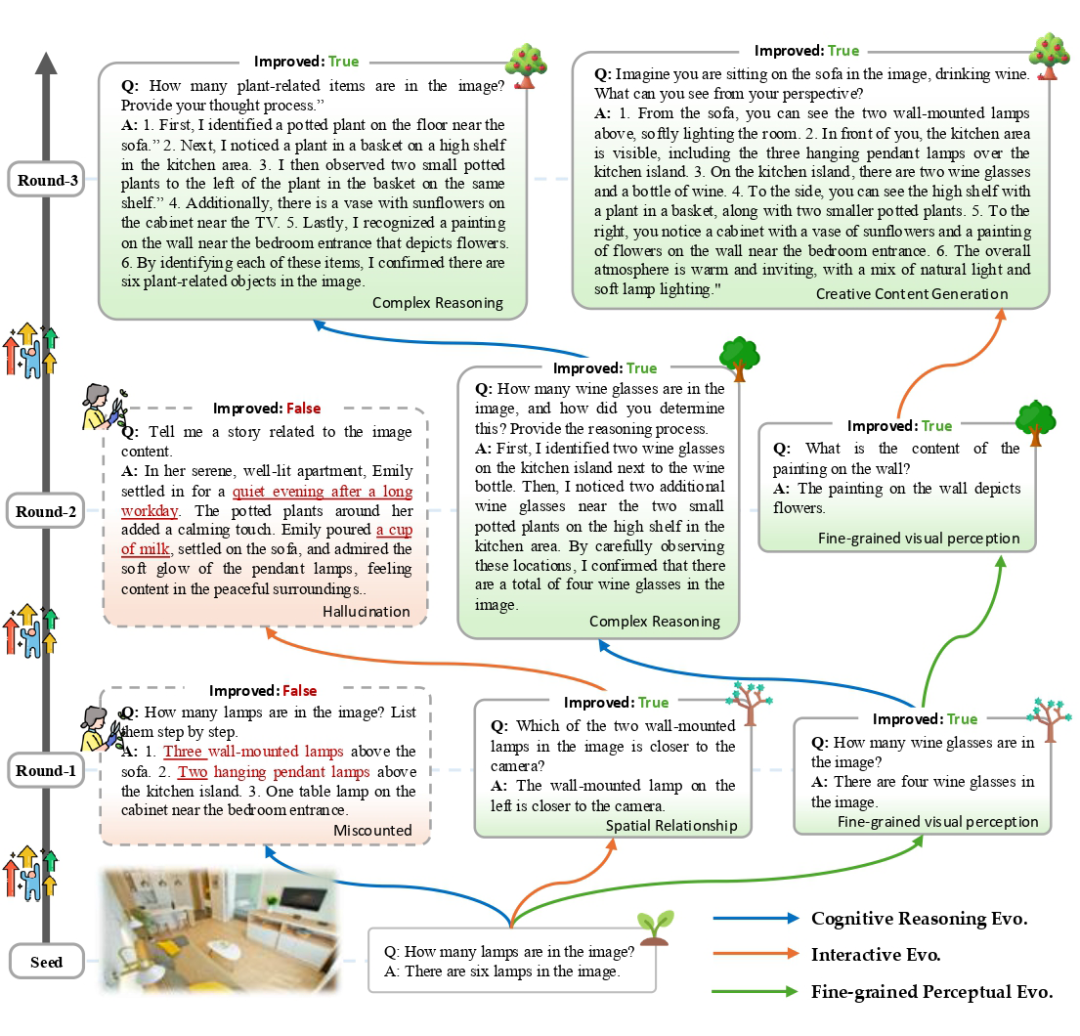
种子数据
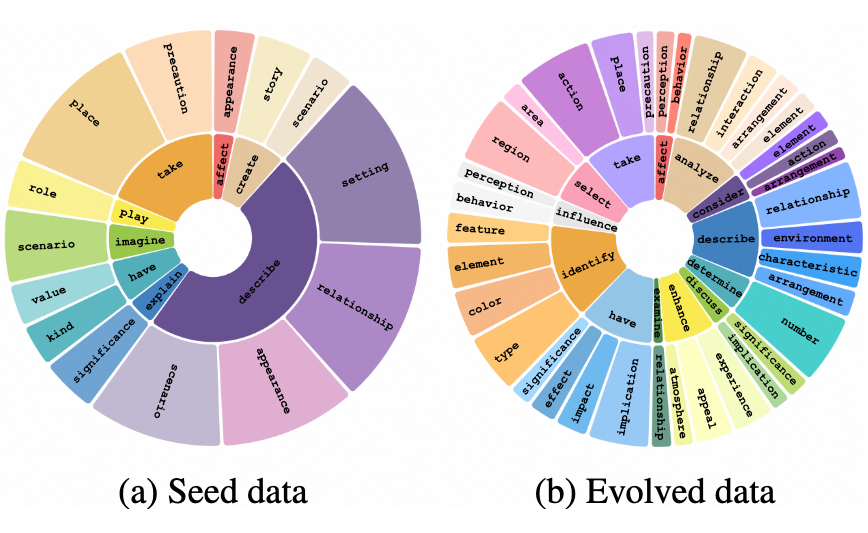
为了验证 MMEvol 的有效性,作者以 LLaVA-Instruct 和 ShareGPT4V 数据为基础,增加了科学问答、图表理解、代码生成和数学推理数据,最终构建了 163K 条种子数据集,分布如下:
进化示例分析:
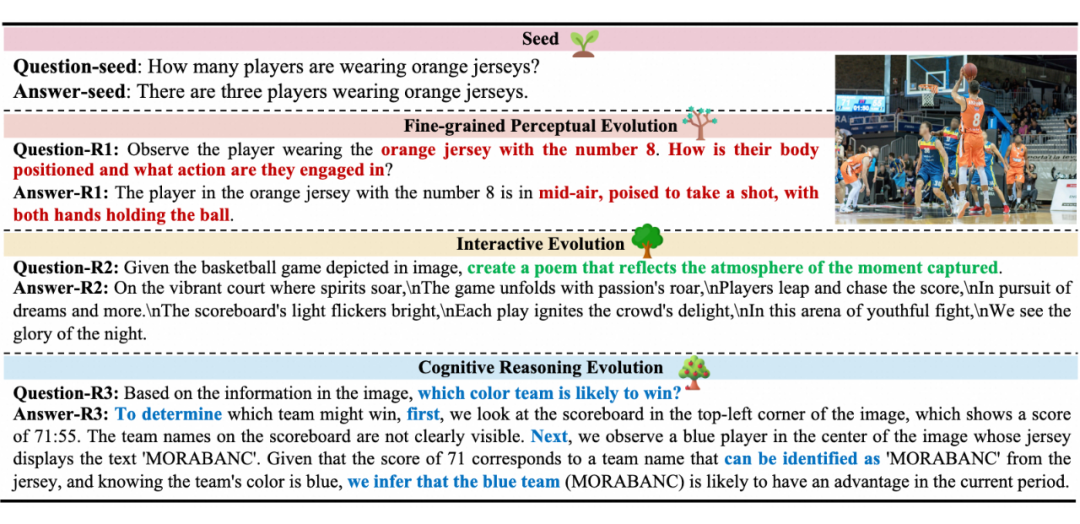
细粒度感知进化:可以细化数据的对齐粒度,关注到更多不一样的细节问题,如球员的姿态和球衣号码等细粒度问题(图中红色标记)提升数据的多样性。
认知推理進化:可以构造更为复杂的问题和拥有更多视觉推理步骤的答案(图中蓝色部分)。
交互进化:扩展数据的指令形式,将对话问答变为新颖的指令任务,例如诗歌创作(图中绿色标记部分)。

实验
MMEvol 数据经过多轮进化后,在复杂度、细粒度和多样性方面明显提升。
复杂度提升:演化后数据在平均原子能力长度、视觉推理步数、难度分数等维度显著提升。
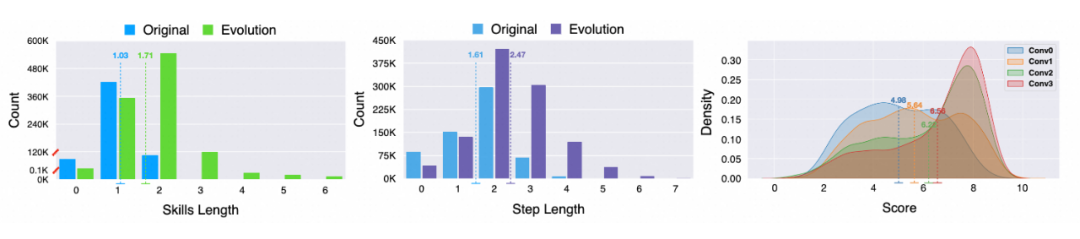
原子能力长度:演化后的指令数据的平均原子能力增加 0.68,最大原子能力长度从 2 提升到 6
视觉推理步数:演化后的指令数据的平均视觉推理步数增加 0.86,最大视觉推理步数从 3 提升到 7
难度分数:每轮演化后的数据的难度平均分数逐步提升,方差逐步缩小,多轮迭代可以稳定提升指令数据的复杂度。
长尾分布改善:演化后数据在视觉物体的长尾分布中显著改善,尾部物体出现频率增加。
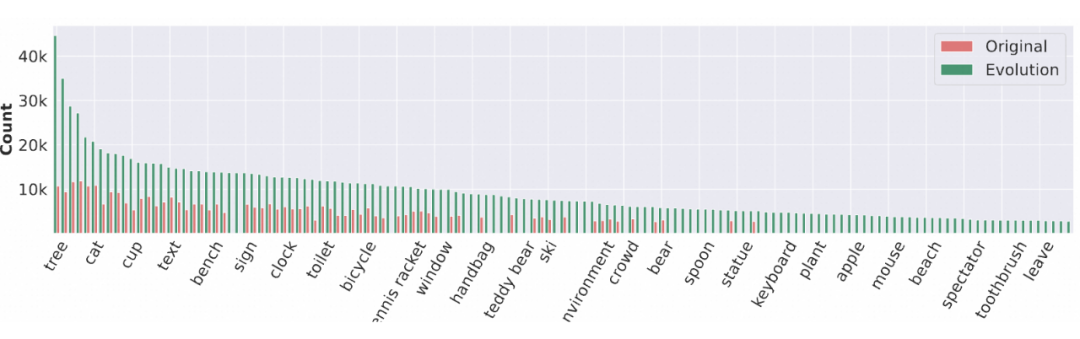
指令形式多样性增加:词频统计表明,演化后数据涵盖了更多图文任务,指令形式更丰富。
性能提升对比:实验表明,模型在视觉推理、指令跟随和抗幻觉能力方面表现出色,在 13 个权威多模态评测集上的 ACC 平均提升了 3%;
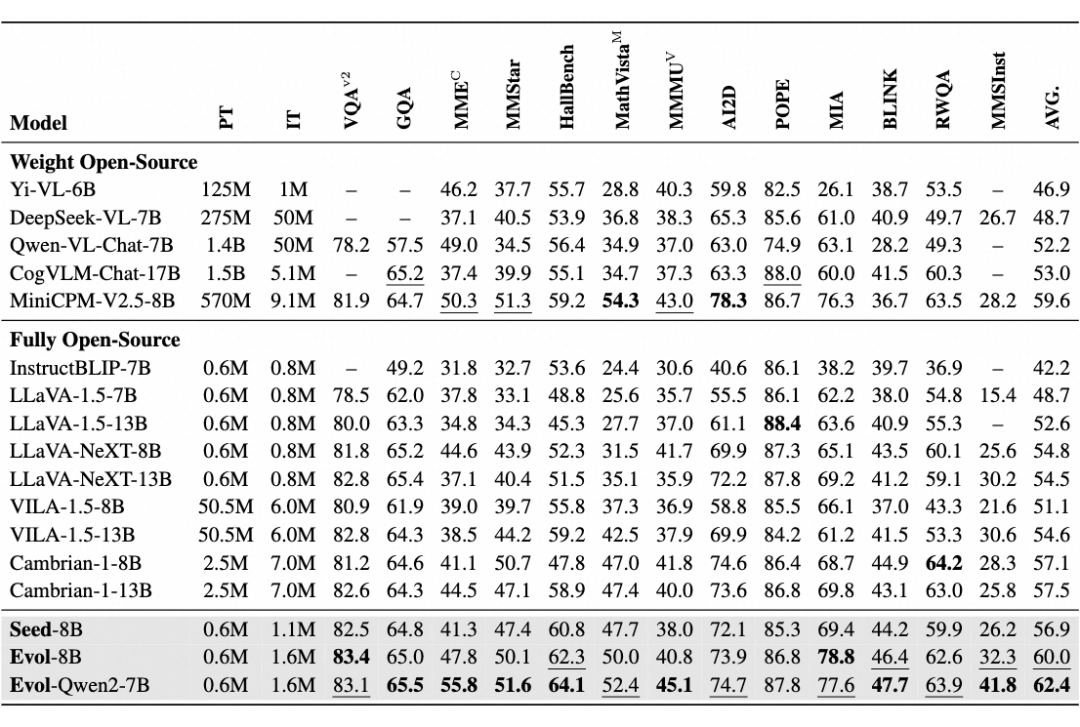
权重开源模型对比:相比 MiniCPM-V2.5-8B,作者用更少的高质量数据实现了视觉推理(MMSInst)、指令跟随(MIA)和抗幻觉性能(HallBench)的显著提升。
全开源模型对比:相比于全开源的先进模型 Cambrain-1-8B,即使数据全部采样于 Cambrain-1-8B 的训练数据,但是使用 MMEvol 对仅 1/4 不到的数据进行多模态指令进化后,却能取得全面领先的效果。
消融实验
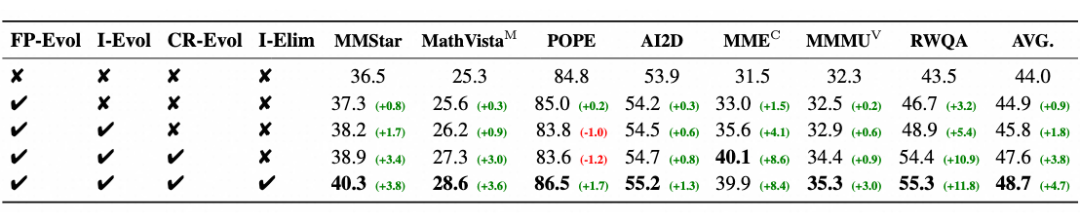
作者针对细粒度感知进化(FP-Evol)、交互进化(I-Evol)、认知推理进化(CR-Evol)和指令消除(I-Elim)进行了消融实验。结果显示,三种进化方向可以正交叠加,协同提升多模态大语言模型能力。
指令消除则过滤掉演化失败数据,进一步提纯数据的质量并提高模型抗幻觉能力。

结论
多模态指令进化(MMEvol)通过细粒度感知、认知推理和交互进化三种策略,显著提升了多模态大语言模型的数据质量和多样性,突破了任务复杂度不足、指令形式单一等瓶颈。该方法减少了对手工标注的依赖,在 13 个多模态评测集上实现了性能提升,展现出优异的视觉推理、指令跟随和抗幻觉能力。
展望未来,作者计划进一步探索多模态协同进化,将图像、文本、音频等多模态信息更紧密地融合,以推动“智能飞轮”持续演进,提升模型在更广泛任务中的表现。这将有助于构建具备综合感知和推理能力的智能系统,推动 AI 技术向更高效、通用和自主的方向发展。
欢迎加入我们
阿里通义实验室-对话智能团队-招聘大语言模型算法专家/实习生
团队介绍
阿里巴巴通义实验室-对话智能团队,以大模型对话技术为核心,研究及应用方向包括智能客服、个性化对话、角色扮演、分身复刻、社交智能、数字人等,主要业务场景包括(1)通义晓蜜—阿里云智能客服,国内对话式 AI 市占率第一;(2)通义星尘-类人智能体创作平台。2020 年以来,围绕预训练、对话智能、大模型等方向发表 80 + 篇国际顶会论文,欢迎对大模型感兴趣的你加入我们,一起创造人机对话的未来。
团队 Google scholar:
https://scholar.google.com/citations?user=5QkHNpkAAAAJ
工作地点
北京 & 杭州
招聘岗位
算法专家,Research Intern
岗位职责
1. 负责角色扮演技术(Role-Playing Agent)的研究和应用;
2. 负责分身复刻(Character AI)的研究和应用;
3. 负责多模态 Character 模型的研究和应用,推动端到端语音对话大模型的大规模落地应用;
4. 负责数字专家的研究和应用,包括用户心理推断、策略搜索推理等技术;
5. 将上述技术在通义晓蜜、通义星尘、阿里云百炼等大模型产品进行大规模应用落地,并探索新应用产品形态;
岗位要求
1. 在人工智能相关方向的硕士/博士,有扎实基础和丰富经验,有相关方向研究或应用者优先;Research Intern 需有至少一篇以上的顶会一作论文;
2. 热爱技术,乐于用创新技术解决业务问题,有大模型经验者优先;
3. 具备优秀的分析问题和解决问题的能力,以及良好的沟通协作能力;
4. 具备技术洞察力、业务敏感度和数据分析能力,能应对复杂业务的算法需求。
简历投递
ting-en.lte@alibaba-inc.com
邮件标题和简历标明:姓名-岗位名称-PaperWeekly
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









