








背景:长上下文视频生成的挑战
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。
解决这一问题的关键在于:高效地对长视频进行训练。但传统的自回归视频建模面临严重的计算挑战——随着视频长度的增加,token 数量呈爆炸式增长。视觉 token 相较于语言 token 更为冗余,使得长下文视频生成比长上下文语言生成更为困难。
本文针对这一核心挑战,首次系统性地研究了如何高效建模长上下文视频生成,并提出了相应的解决方案。
我们特别区分了两个关键概念:
长视频生成:目标是生成较长的视频,但不一定要求模型持续利用已生成的内容,因此缺乏长时序的一致性。这类方法通常仍在短视频上训练,通过滑动窗口等方式延长生成长度。
长上下文视频生成:不仅要求视频更长,还要持续利用历史上下文信息,确保长时序一致性。这类方法需要在长视频数据上进行训练,对视频生成建模能力提出更高要求。
长上下文视频生成的重要性:最近的工作 Genie2 [1] 将视频生成用于 world modeling /game simulation 的场景中,展现出非常令人惊艳的潜力。然而,现有基于滑窗的生成方法通常缺乏记忆机制,无法有效理解、记住并重用在 3D 环境中探索过的信息,比如 OASIS [2]。
这种缺乏记忆性的建模方式,不仅影响生成效果,还可能导致对物理规律建模能力的缺失。这可能正是当前长视频生成中常出现非物理现象的原因之一:模型本身并未在大量长视频上训练,i2v(image-to-video)+ 滑动窗口的方式难以确保全局合理性。

论文标题:
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
论文作者:
Yuchao Gu, Weijia Mao, Mike Zheng Shou
作者单位:
新加坡国立大学 Show Lab
项目主页:
https://farlongctx.github.io/
论文链接:
https://arxiv.org/abs/2503.19325
开源代码:
https://github.com/showlab/FAR

FAR 的创新设计与分析
2.1 核心理念:将视频生成重构为基于长短时上下文的逐帧预测任务
1)帧自回归模型(FAR):FAR 将视频生成任务重新定义为基于已有上下文逐帧(图像)生成的过程。
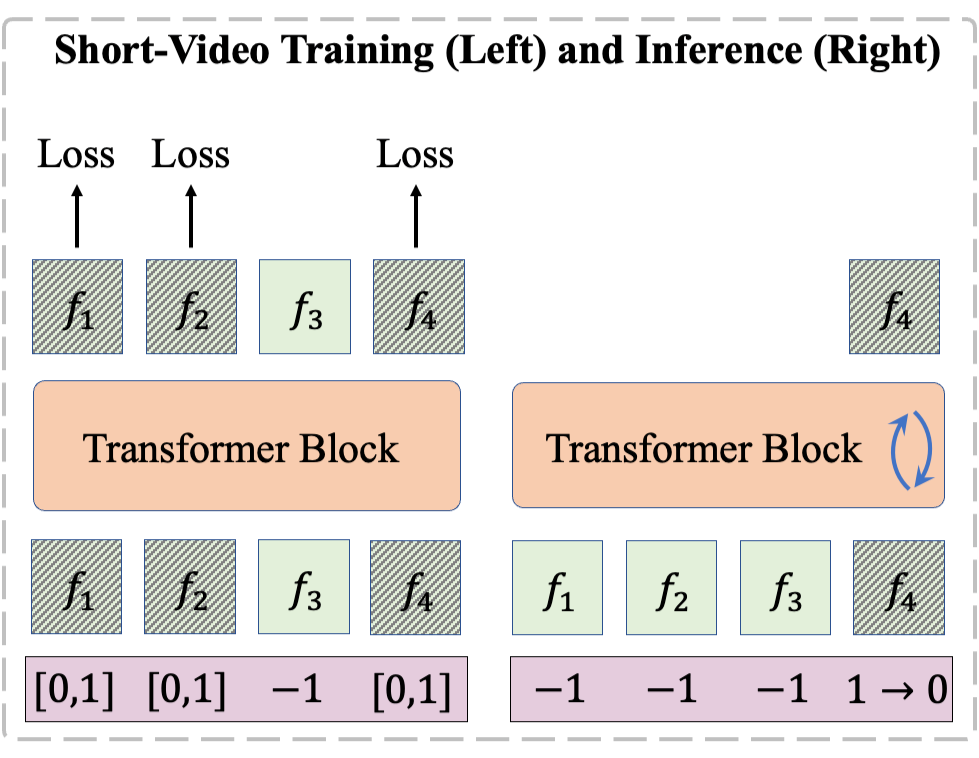
▲ FAR 在短视频上的训练测试架构
2)长短时上下文建模:我们观察到,随着上下文帧数量的增加,视频生成中会出现视觉 token 数量急剧增长的问题。然而,视觉 token 在时序上具有局部性:对于当前解码帧,其邻近帧需要更细粒度的时序交互,而远离的帧通常仅需作为记忆存在,无需深入的时序交互。
基于这一观察,我们提出了长短时上下文建模。该机制采用非对称的 patchify 策略:短时上下文保留原有的 patchify 策略,以保证细粒度交互;而长时上下文则进行更为激进的 patchify,减少 token 数量,从而在保证计算效率的同时,维持时序模拟的质量。
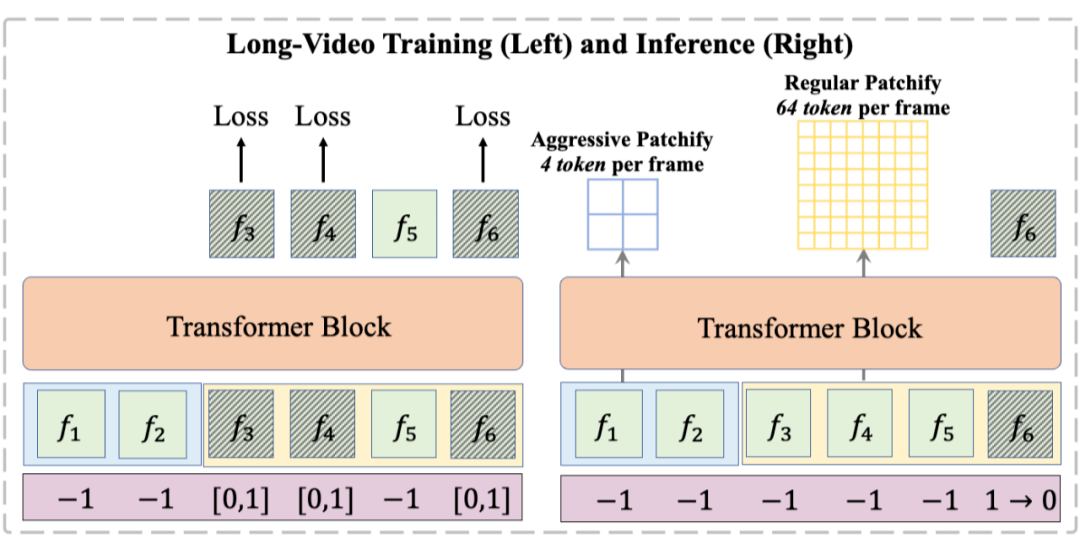
▲ FAR 在长视频上的训练测试架构:对长时和短时 context 利用非对称的 patchify 策略
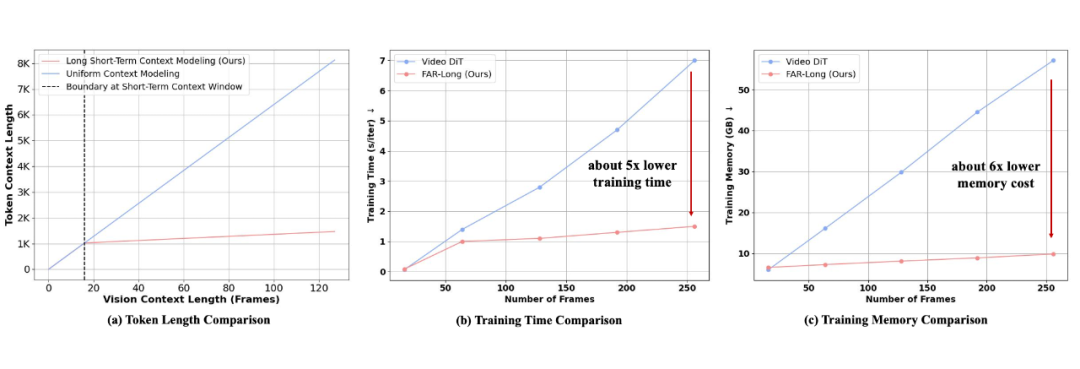
▲ FAR 在长视频上的 token 减少以及训练效率提升
3)用于长上下文视频生成的多层 KV Cache 机制:针对长短时上下文的非对称 patchify 策略,我们提出了相应的多层 KV-Cache 机制。
在自回归解码过程中,当某一帧刚离开短时上下文窗口时,我们将其编码为低粒度的 L2 Cache(少量 token);同时,更新仍处于短时窗口内帧的 L1 Cache(常规 token)。最终,我们结合这两级 KV Cache,用于当前帧的生成过程。
值得强调的是,多层 KV Cache 与扩散模型中常用的 Timestep Cache 是互补的:前者沿时间序列方向缓存 KV 信息,后者则在扩散时间步维度上进行缓存,共同提升生成效率。
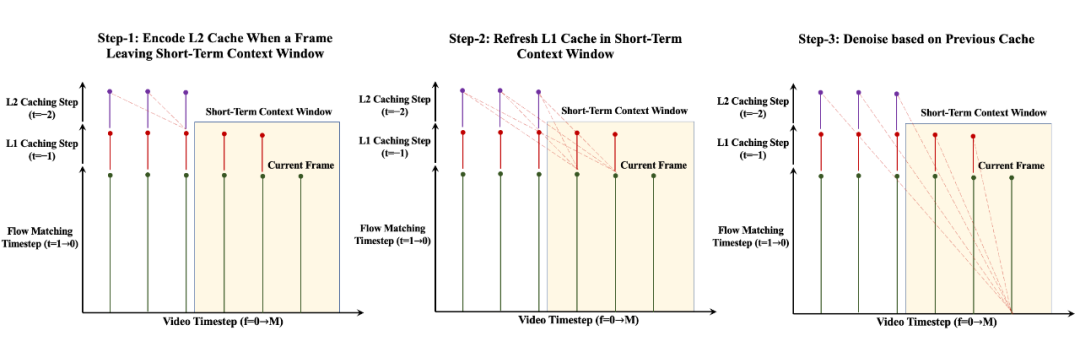
▲ 针对长短时上下文策略的多层 KV Cache
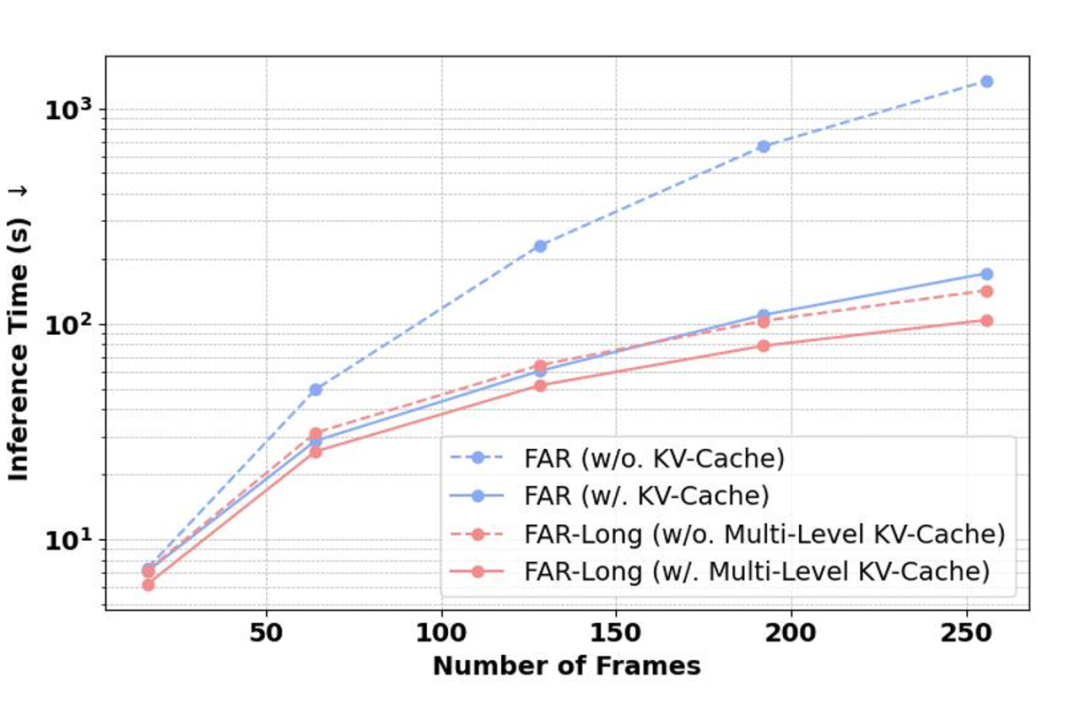
▲ 长视频生成的效率提升

FAR 相对于 SORA 类 VideoDiT 的潜在优势
1)收敛效率:在相同的连续潜空间上进行实验时,我们发现 FAR 相较于 Video DiT 展现出更快的收敛速度以及更优的短视频生成性能。
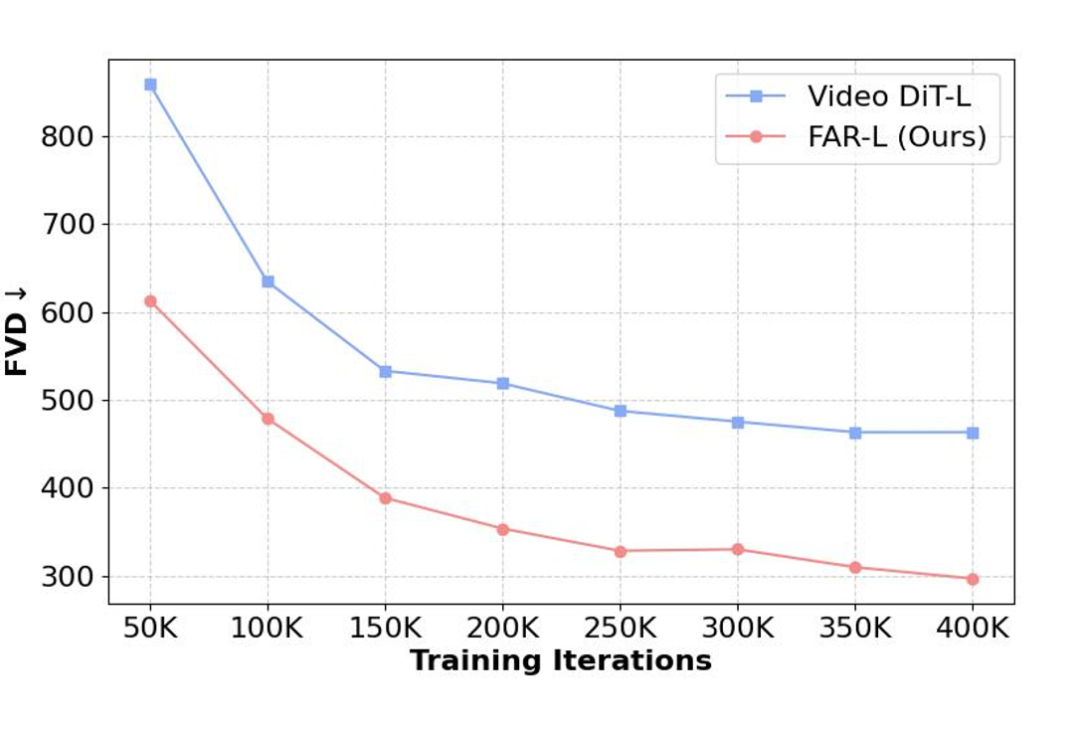
▲ FAR 与 Video DiT 的收敛对比
2)无需额外的 I2V 微调:FAR 无需针对图像到视频(I2V)任务进行额外微调,即可同时建模视频生成与图像到视频的预测任务,并在两者上均达到 SOTA 水平。
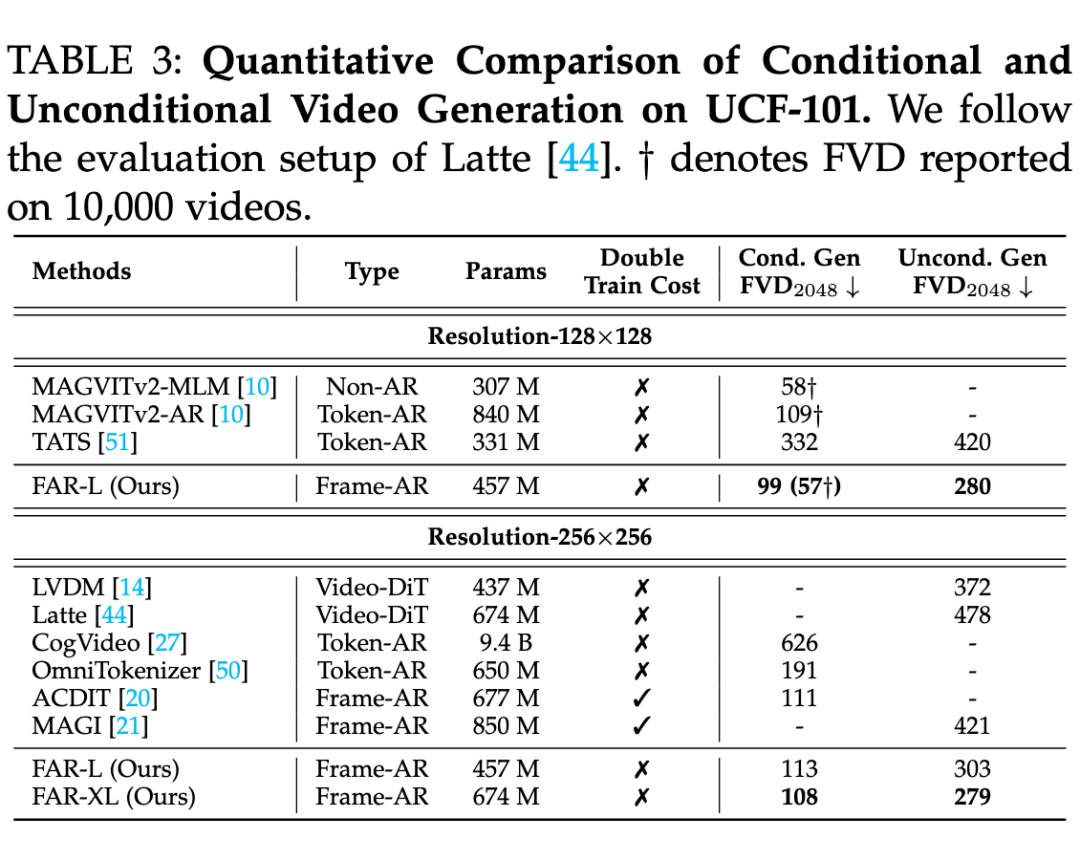
▲ 条件/非条件视频生成的评测结果
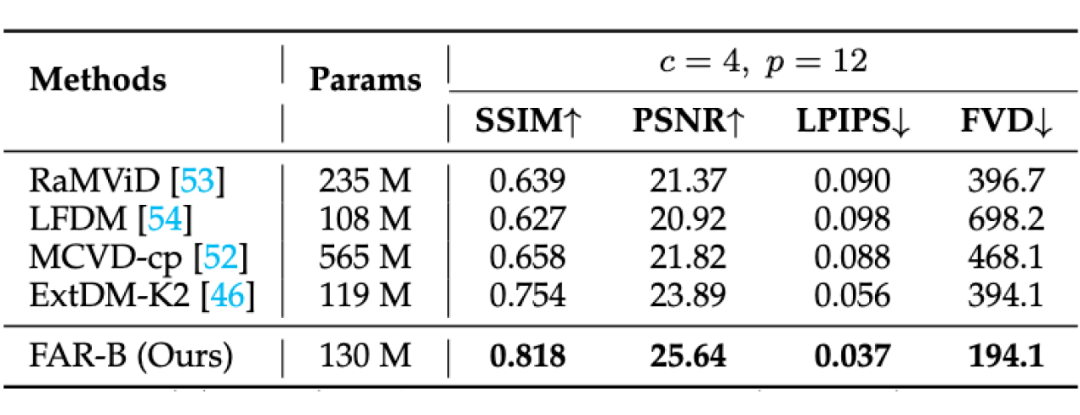
▲ 基于条件帧的视频预测的评测结果
3)高效的长上下文建模能力:FAR 支持高效的长视频训练以及对长上下文建模。在基于 DMLab 的受控环境中进行实验时,我们观察到模型对已观测的 3D 环境具有出色的记忆能力,在后续帧预测任务中首次实现了近乎完美的长期记忆效果。
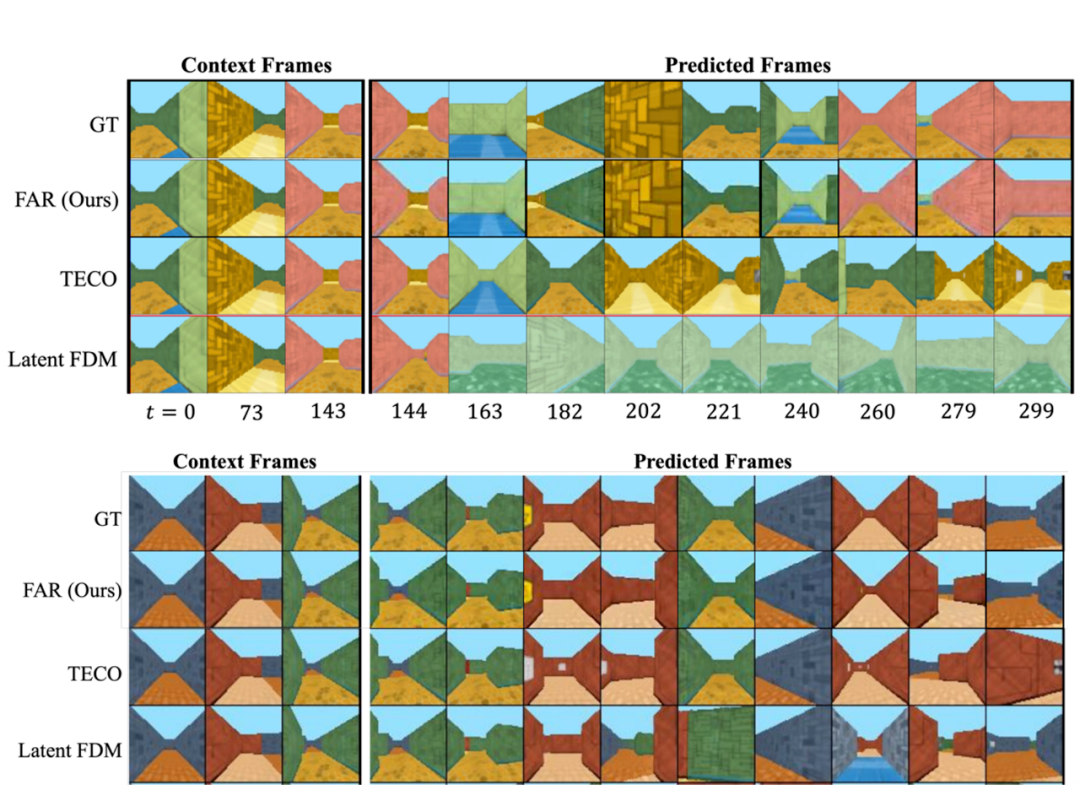
▲ 基于观测帧的长视频预测结果

总结
我们首次系统性地验证了长上下文建模在视频生成中的重要性,并提出了一个基于长短时上下文的帧自回归模型——FAR。FAR 不仅在短视频生成任务中,相较于 Video DiT 展现出更快的收敛速度与更优性能,同时也在长视频的 world modeling 场景中,首次实现了显著的长时序一致性。
此外,FAR 有效降低了长视频生成的训练成本。在当前文本数据趋于枯竭的背景下,FAR 为高效利用现有海量长视频数据进行生成式建模,提供了一条具有潜力的全新路径。

参考文献
[1] Genie 2: https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/
[2] Oasis: https://oasis-model.github.io/
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 4571
4571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









