








过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。为此,PaperWeekly 联手百度 PaddlePaddle 共同发起了本次论文有奖复现,我们希望和来自学界、工业界的研究者一起接力,为 AI 行业带来良性循环。
作者丨黄涛
学校丨中山大学数学学院18级本科生
研究方向丨图像识别、VQA、生成模型和自编码器

论文复现代码:
http://aistudio.baidu.com/#/projectdetail/23600
GAN
生成对抗网络(Generative Adversarial Nets)是一类新兴的生成模型,由两部分组成:一部分是判别模型(discriminator)D(·),用来判别输入数据是真实数据还是生成出来的数据;另一部分是是生成模型(generator)G(·),由输入的噪声生成目标数据。GAN 的优化问题可以表示为:
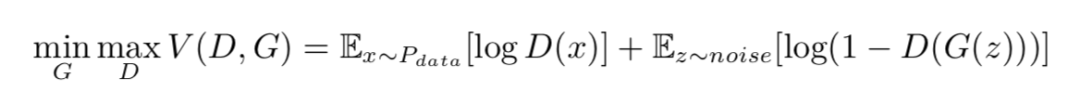
其中 Pdata 是生成样本,noise 是随机噪声。而对于带标签的数据,通常用潜码(latent code)c 来表示这一标签,作为生成模型的一个输入,这样我们有:
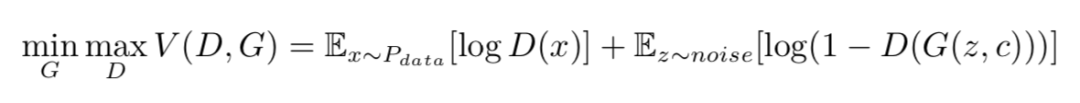
然而当我们遇到存在潜在的类别差别而没有标签数据,要使 GAN 能够在这类数据上拥有更好表现,我们就需要一类能够无监督地辨别出这类潜在标签的数据,InfoGAN 就给出了一个较好的解决方案。
互信息(Mutual Information)
互信息是两个随机变量依赖程度的量度,可以表示为:
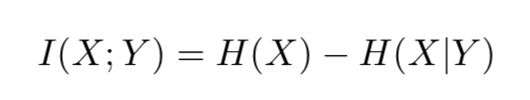
要去直接优化 I(c;G(z,c)) 是极其困难的,因为这意味着我们要能够计算后验概率(posterior probability)P(c|x),但是我们可以用一个辅助分布(auxiliary distribution)Q(c|x),来近似这一后验概率。这样我们能够给出互信息的一个下界(lower bounding):
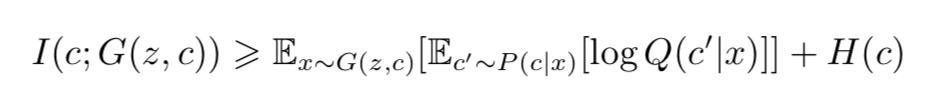
InfoGAN
在 InfoGAN 中,为了能够增加潜码和生成数据间的依赖程度,我们可以增大潜码和生成数据间的互信息,使生成数据变得与潜码更相关:
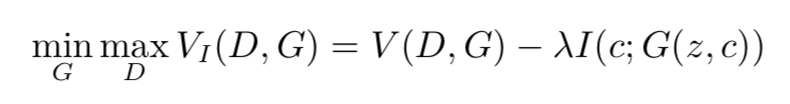
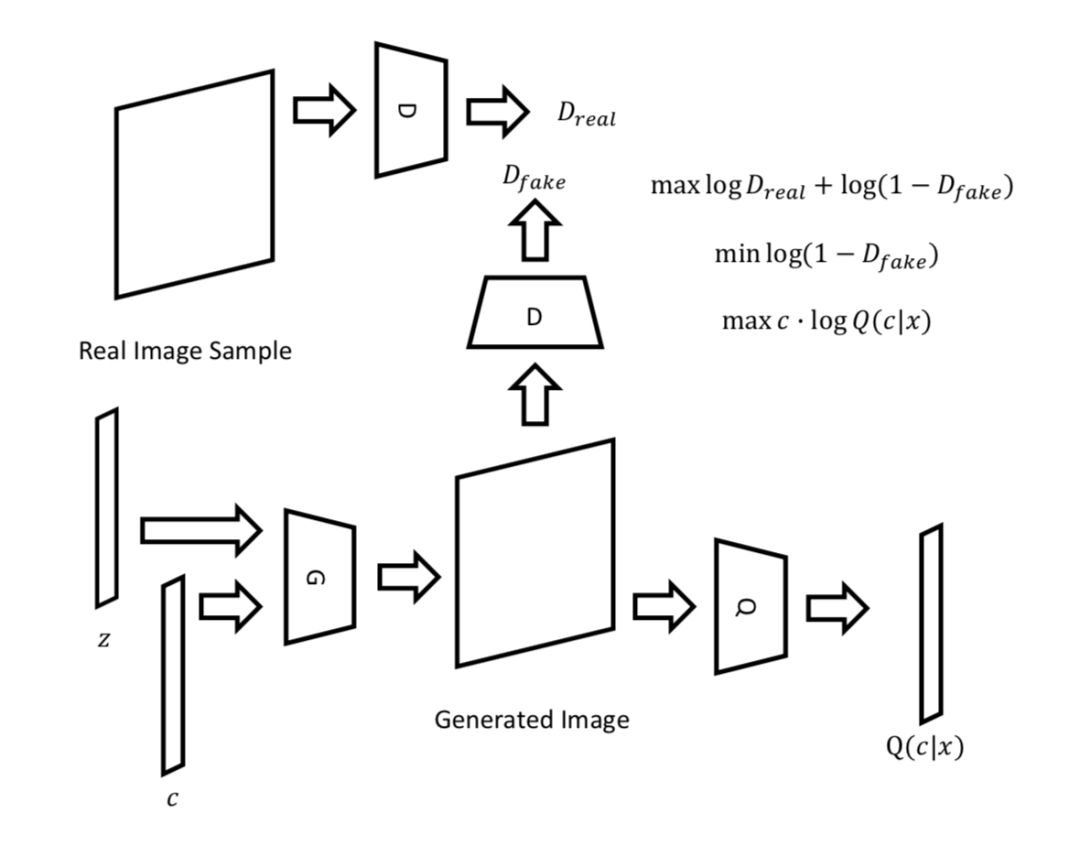
▲ 图1. InfoGAN的整体结构图
由上面的,对于一个极大化互信息的问题转化为一个极大化互信息下界的问题,我们接下来就可以定义:
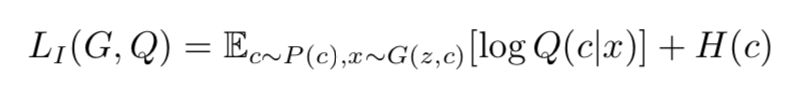
在论文的附录中,作者证明了:
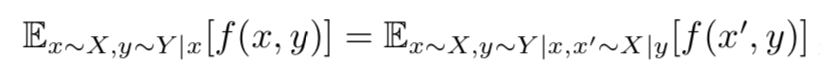
于是:
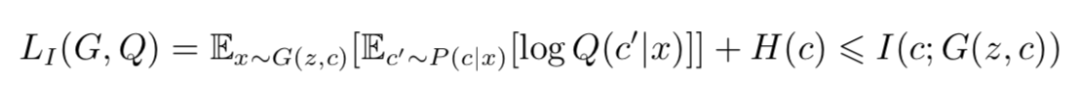
故 LI (G, Q) 是互信息的一个下界。作者指出,用蒙特卡罗模拟(Monte Carlo simulation)去逼近 LI (G, Q) 是较为方便的,这样我们的优化问题就可以表示为:

实现
在实现中,D(x)、G(z, c) 和 Q(x) 分别用一个 CNN (Convolutional Neural Networks)、CNN、DCNN (DeConv Neural Networks) 来实现。同时,潜码 c 也包含两部分:一部分是类别,服从 Cat(K = N,p = 1/N),其中 N 为类别数量;另一部分是连续的与生成数据有关的参数,服从 Unif(−1,1) 的分布。
在此应指出,Q(c|x) 可以表示为一个神经网络 Q(x) 的输出。对于输入随机变量 z 和类别潜码 c,实际的 LI(G, Q) 可以表示为:
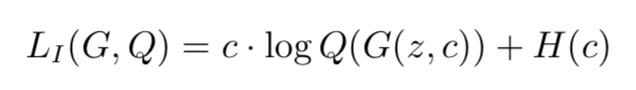
其中 · 表示内积(inner product),c 是一个选择计算哪个 log 的参数,例如 ci = 1 而 cj = 0(∀j = 1,2,···,i − 1,i + 1,···,n),那么 z 这时候计算出的 LI(G,Q) 就等于 log(Q(z,c)i)。这里我们可以消去 H(c),因为 c 的分布是固定的,即优化目标与 H(c) 无关:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









