







 本文从变分推断的角度出发,利用变分EM算法框架解析扩散模型,其中正向过程对应E步,逆向过程对应M步。通过对马尔可夫链上的变分推断,建立正向和逆向过程,并运用Tweedie定理。文章讨论了DDPM的训练和采样算法,以及如何通过分数匹配策略优化模型。同时,将这一框架拓展到基于分数的扩散模型,介绍了Score-SDE及其在密度和得分估计中的应用。
本文从变分推断的角度出发,利用变分EM算法框架解析扩散模型,其中正向过程对应E步,逆向过程对应M步。通过对马尔可夫链上的变分推断,建立正向和逆向过程,并运用Tweedie定理。文章讨论了DDPM的训练和采样算法,以及如何通过分数匹配策略优化模型。同时,将这一框架拓展到基于分数的扩散模型,介绍了Score-SDE及其在密度和得分估计中的应用。

©PaperWeekly 原创 · 作者 | 石壮威
单位 | 季华实验室
研究方向 | AI for Science

引言
扩散模型是当前深度学习领域最引人瞩目的算法之一,它不仅在一系列生成任务中取得优秀表现,推动了生成式人工智能的高歌猛进;更具有严密的理论基础,在探索深度学习可解释性的道路上迈出了坚实的一步。
扩散模型与此前的基于变分推断的生成式模型(例如变分自编码器和标准化流)一脉相承,而又具有独到之处。因此,本文以变分推断的视角,基于变分 EM 算法框架,认为扩散模型的正向(训练)和逆向(采样)过程分别对应变分 EM 算法的 E 步和 M 步,进而探讨了扩散模型中的分数匹配策略。

方法
2.1 马尔可夫链上的变分推断
目前最常用的扩散模型 DDPM(Denoising Diffusion Probabilistic Models)[1],将输入变量 通过马尔可夫链得到的在 时刻的一系列隐藏状态 视作隐变量。通过变分分布 来逼近原始分布 ,这等价于优化证据下界(ELBO)。
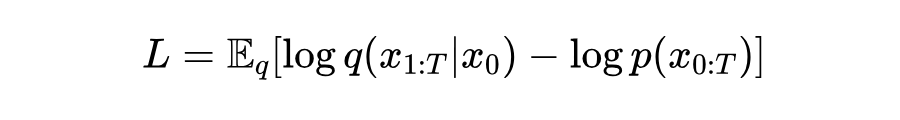
由马尔可夫性可知
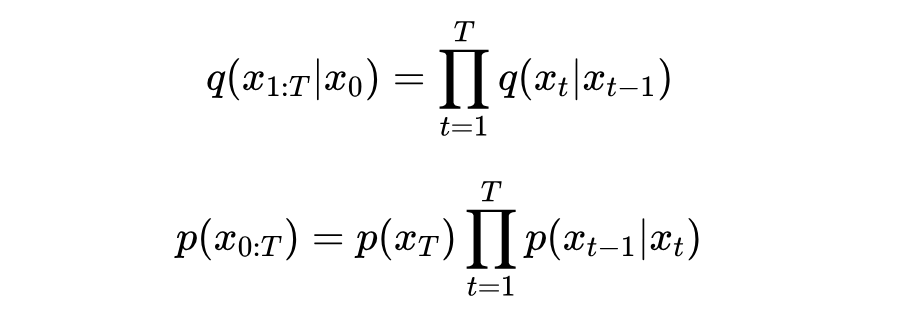
于是可写出马尔可夫链的正向和逆向过程
正向:输入 在马尔可夫链 上以状态转移概率 得到 。具体而言,通过在状态转移的每一步添加高斯噪声 ,使得最终 。
逆向:输入 在马尔可夫链 上以状态转移概率 生成 。
于是 ELBO
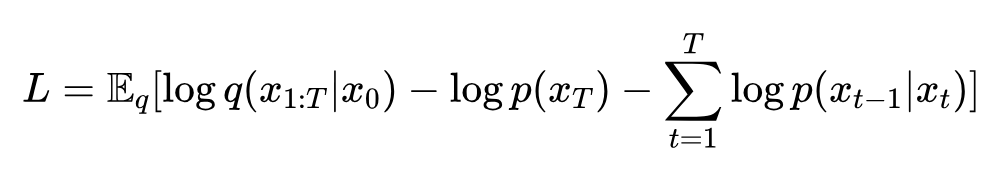
采用变分 EM 算法优化 ELBO,交替执行:
E 步(优化 q):因为 , 无需优化,所以 的优化目标是使之与 尽量接近。
M 步(优化 p):从 q 中对 p 进行采样,最大化 。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









