








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
众所周知,目前主流的 LLM,都是基于 Causal Attention 的 Decoder-only 模型(对此我们在《为什么现在的LLM都是Decoder-only的架构?》也有过相关讨论),而对于 Causal Attention,已经有不少工作表明它不需要额外的位置编码(简称 NoPE)就可以取得非平凡的结果。然而,事实是主流的 Decoder-only LLM 都还是加上了额外的位置编码,比如 RoPE、ALIBI 等。
那么问题就来了:明明说了不加位置编码也可以,为什么主流的 LLM 反而都加上了呢?不是说“多一事不如少一事”吗?这篇文章我们从三个角度给出笔者的看法:
1. 位置编码对于 Attention 的作用是什么?
2. NoPE 的 Causal Attention 是怎么实现位置编码的?
3. NoPE 实现的位置编码有什么不足?

位置编码
在这一节中,我们先思考第一个问题:位置编码对于 Attention 机制的意义。
在 BERT 盛行的年代,有不少位置编码工作被提了出来,笔者在《让研究人员绞尽脑汁的Transformer位置编码》也总结过一些。后来,我们在《Transformer升级之路:Sinusoidal位置编码追根溯源》中,试图从更贴近原理的视角来理解位置编码,并得到了最早的 Sinusoidal 位置编码的一种理论解释,这也直接启发了后面的 RoPE。
简单来说,位置编码最根本的作用是打破 Attention 的置换不变性。什么是置换不变性呢?在 BERT 时代,我们主要用的是双向 Attention,它的基本形式为:
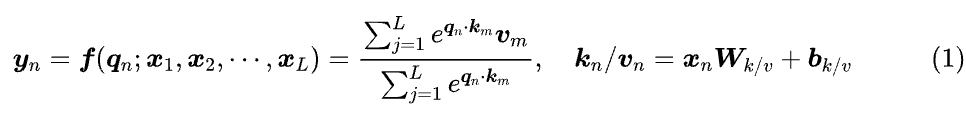
假设 是 的任意排列,那么置换不变性是指
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









