







 超级会员免费看
超级会员免费看
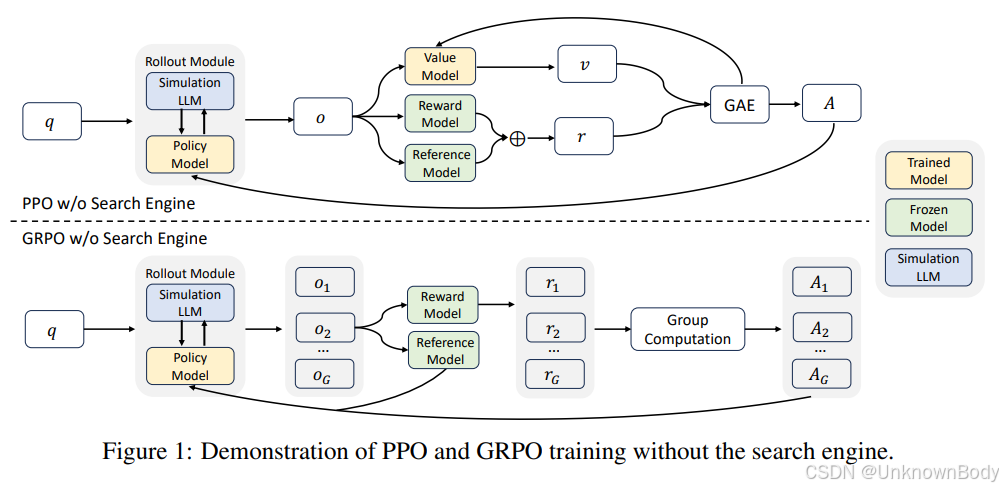
文章主要内容总结
本文提出了一种名为ZEROSEARCH的强化学习框架,旨在解决现有大语言模型(LLMs)在利用真实搜索引擎进行搜索能力训练时面临的两大挑战:文档质量不可控和API成本过高。该框架通过以下方式实现创新:
- 监督微调构建检索模块:通过轻量级监督微调将LLM转化为检索模块,使其能够根据查询生成相关文档和噪声文档,实现对文档质量的可控模拟。
- 基于课程的训练策略:在强化学习训练过程中,采用逐步降级文档质量的课程式展开策略,使模型在逐渐增加的挑战中提升推理能力。
- 高效可扩展的训练机制:无需依赖真实搜索引擎的API,通过GPU并行计算加速模拟文档生成,大幅降低训练成本。
实验结果表明,ZEROSEARCH在单跳和多跳问答基准测试中均优于依赖真实搜索引擎的基线方法。例如,70亿参数的检索模块性能可与谷歌搜索媲美,140亿参数模块甚至超越真实搜索。此外,该框架对不同参数规模的基础模型和指令微调模型具有良好的泛化能力,并兼容PPO、GRPO等多种强化学习算法。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











