






今天我要讲的文章是diffusion-LM improves controllable text generation,目前在arxiv上,2022.5月的,讲的是运用diffusion模型更好的进行可控文本生成

首先简单介绍本文要明白的一些知识点,一下文本生成的可控制性,文本生成是从一个与训练好的语言模型中采样一个序列的离散单词,可控文本生成指的是从条件分布中采样一个符合要求的离散单词序列,c为控制变量。比如c为一个正向情感类别,就要生成一个能被判定为正向情感类别的句子

Plug-and-play 即插即用的可控文本生成,指给一个通过无标签的大量文本数据训练后的语言模型plm(w),如GPT,以及一个针对特定任务数据训练的分类器,目标是使用两个模型来产生特定任务某一类别的文本,也就是获得一个新的针对特定分类任务的文本生成模型,根据贝叶斯法则,该模型可以由plm和分类器控制得到,其中语言模型如GPT控制文本生成的流畅性,分类器控制生成特定的文本。

自回归模型,指的是根据上文预测下文或根据下文预测上文,缺点是单方向,不能同时利用上下文信息,适用于特定的NLP下游任务,典型代表由GPT等

预训练:GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词; GPT是单向模型,无法利用上下文信息,只能利用上文;而BERT是双向模型。
模型效果: GPT 因为采用了传统语言模型所以更加适合用于自然语言生成类的任务 (NLG),因为这些任务通常是根据当前信息生成下一刻的信息。而 BERT 更适合用于自然语言理解任务 (NLU)。
模型结构: 模型结构:GPT 采用了 Transformer 的 Decoder,而 BERT 采用了 Transformer 的 Encoder。GPT 使用 Decoder 中的 Mask

介绍了上面的知识点后,来说一下本文的背景,自回归语言模型如GPT目前虽然可以用于高质量的文本生成,但是在实际的部署中需要进行可控的文本生成,即符合要求的文本;因此在不重新训练语言模型情况下控制语言模型生成行为是一个自然语言生成的开放性问题,虽然目前对于简单的句子属性控制上取得了成功,但是更复杂的,如语义结构方面的控制却少有进展

那么难题是什么呢?是因为对于GPT等语言模型来说,根据控制人物调整参数很困难,并且不允许多任务控制,(GPT-3具有1,750亿个参数,是具有170亿个参数的Turing-NLG模型的10倍),目前比较流行的即插即用的方法可以让语言模型冻结,根据外部的控制器来评估生成文本是否符合需求,从而控制语言模型生成特定的人物,但是控制一个冻结的自回归模型很困难,并且目前只在简单的任务上成功。

针对上述问题,作者便提出了运用diffusion到可控文本生成上,实现更复杂的控制
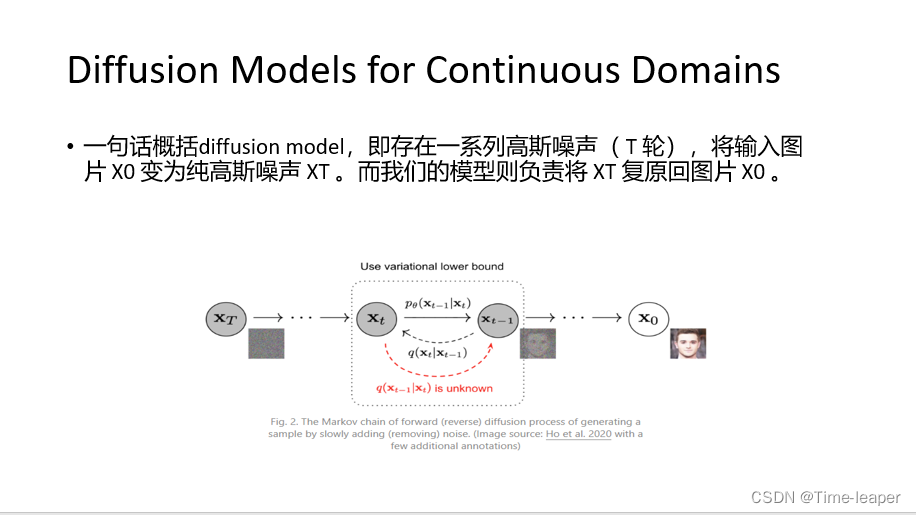
一句话概括diffusion model,即存在一系列高斯噪声( T 轮),将输入图片 X0 变为纯高斯噪声 XT 。而我们的模型则负责将 XT 复原回图片 X0 。在该过程中,逆向降噪过程是未知的,所以就需要学习降噪过程参数。后面简单来讲讲diffusion的推导

把β变为α,带入xt-1和xt-2就可以得到如下的表示,这里尾部标准差相加后等于方差相加

由于KL散度为正值,所以可以放缩为左边的形式,加上一个KL散度,让每一步的预测值的反向过程都接近真实的q分布
在这里插入图片描述
将前面的LVLBB转换为KL散度形式,LT项和L1项,由于前向 q 没有可学习参数,而 xT则是纯高斯噪声, LT 可以当做常量忽略。DDPM论文指出,从 x1 到 x0 应该是一个离散化过程,因为图像RGB值都是离散化的。DDPM针对 pθ(x0|x1) 构建了一个离散化的分段积分累乘,有点类似基于分类目标的自回归(auto-regressive)学习

左边通过都偶按高斯分布的KL散度秋节化为2(15)形式,然后将之前推导出来Xt的由X0和α的表达式,将其带入之前推导的公式中,进行重参数化

将绝对值外的加权项去除,最终得到简单形式的损失,diffusion训练的核心就是取学习标准高斯噪声 zt 和网络 zθ 之间的MSE。

Diffusion的训练和采样过程如图所示,左边训练即优化刚才的损失,右边对的采样即为通过训练好的网络一步一步的重现初始样本X0

本文将利用类似的简化方法来稳定训练和提高样本质量

然后来看本文提出的diffusion——LM,连续diffusion语言模型,本文提出了两个模块,端到端训练和舍入方法。端到端:设置一个科学系的word emebedding网络来学习词嵌入向量;舍入方法:将连续的向量变为离散的文本
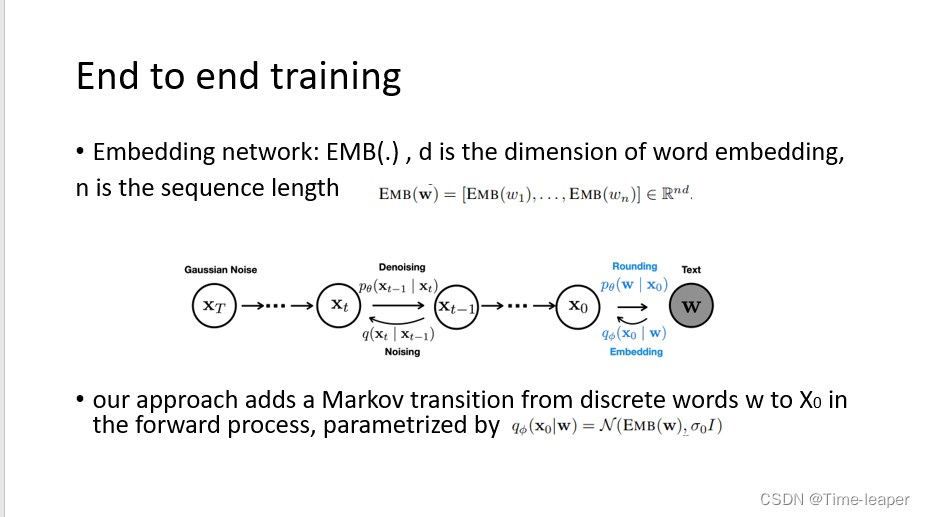
先看端到端,作者在X0后面添加了一个X0到文本w的过程,即diffusion 初始加噪声前加上一个文本embedding的马尔可夫前向过程,去噪完之后再加上将连续的X0转化为文本的过程。作者在实验中发现可学习的embedding过程效果比随机embedding更好

舍入方法:把最后的rounding过程参数化为这样,求生成文本的最大释然,后面转化为负对数进行优化

根据上面对diffusion的改造(添加了端到端和舍入),将diffusion原本的损失改为上面的样子

在原本的vlb损失上面添加round和end to end过程,共同学习扩散模型和嵌入参数,并且根据diffusion从Lvlb到Lsimple的推导类似的推导出简化形式
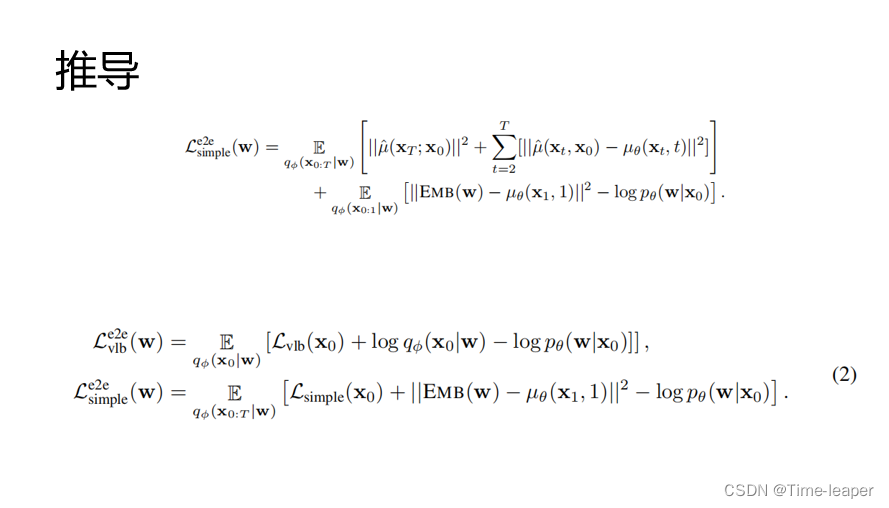
去除前面的平方项保留Lsimple(X0)得到优化损失

作者将发现学习得的embedding层对单词聚类后,相同词性的embedding聚在了一起
在舍入过程中,即将X0转换为离散的单词过程中,理想情况下是可以将x0恰好映射为某个单词,但是作者发现模型不能很好的将x0生成为单个单词

作者分析了原因,认为在优化目标中至于测了降噪步骤的均值,也就是降噪增加的正态分布的均值,而将X0 commit为一个单词embedding的约束只在接近0时刻的之前几步进行


针对上述的分析,对Lsimple进行重构,转换为下面的形式,直接在每一项中利用网络预测最终的重构样本X0,并且发现这样可以迅速的让X0集中于某一单词的embedding周围

推导过程为将原本的Lsimple展开,将逆向过程进行推导可以得到μ的表达形式,将预测的f作为x0带入转化为新的形式

然后作者采用了夹紧技巧,由diffusion正向过程可知,xt-1可以由预测的X0表示出来

所以作者在diffusion采样过程迫使预测向量提交到最近的一个词的embedding,使得向量预测更加精确,减少了舍入误差

上面讲完了对diffusion-LM的训练过程(预训练),下面是可控生成过程中,作者根据即插即用和贝叶斯法则,构造了如下的优化目标,1正比例于diffsuion的denose过程和分类器分类过程,所以进行负对数释然作为损失,由于都具有梯度,所以可以进行优化

作者在可控生成中加入文本流利性正则化超参数lamda,lamda控制diffusion生成文本的流畅性,越大越流畅,还执行了multiple gradient步骤,每次diffusion denose过程执行三次adagrad更新,并且为了加速可控生成,将diffusion步骤从2000减少到200

应用最小贝叶斯风险(MBR)解码来聚合一组从Diffusion-LM中抽取的样本S,并选择在损失函数L(例如,负BLEU分数)下实现最小预期风险的样本

实验前先在We train Diffusion-LM on two datasets: E2E and ROCStories 训练diffusion语言模型(相当于是预训练)
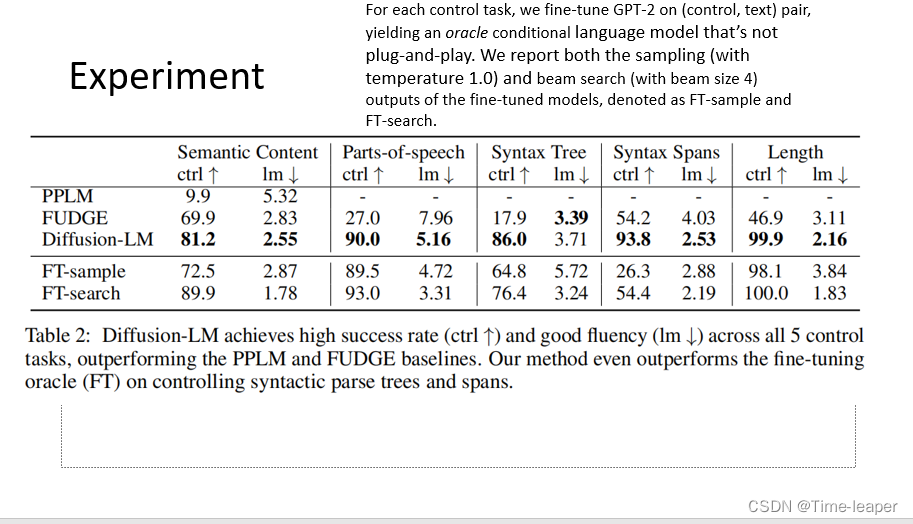
Fudge和pplm是传统的可控方法, FT是在GPT上进行微调
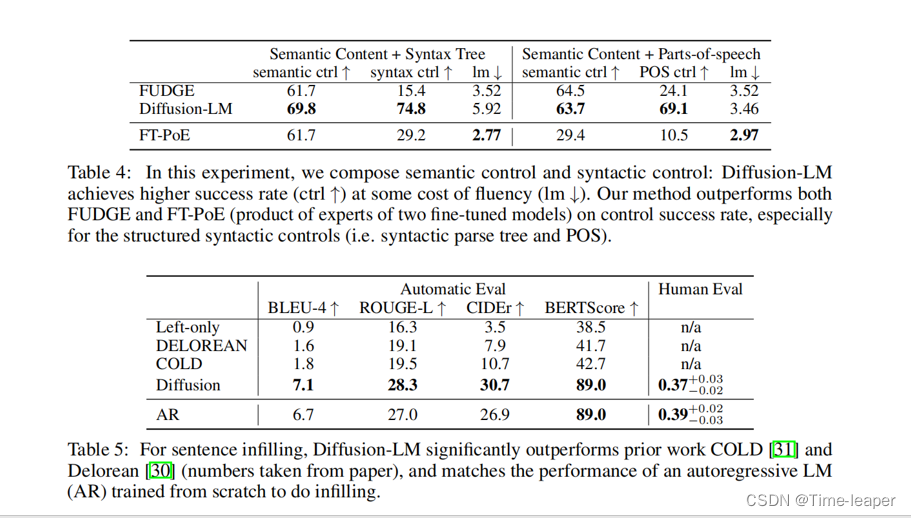
这里是其他组合实验的效果
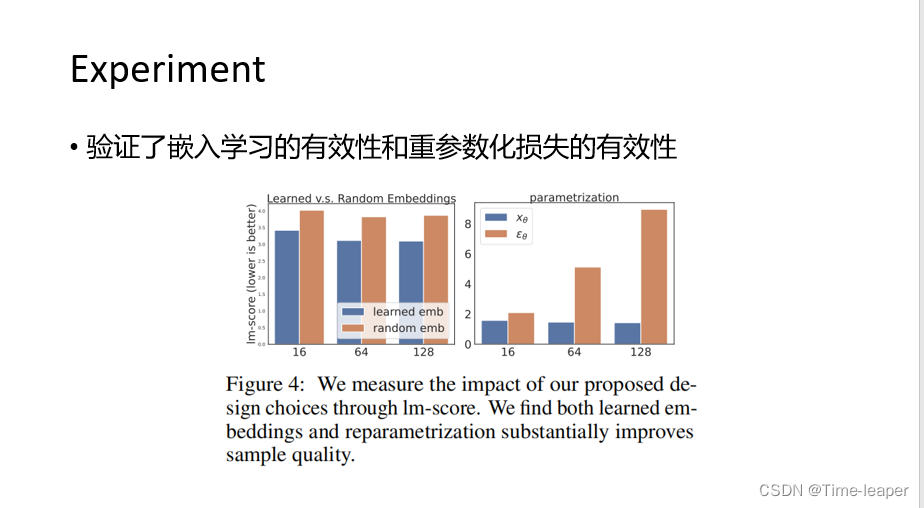
消融模块验证了嵌入曾学习和重参数化损失的有效性














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









