








跨小样本图像分类的深度度量学习:最新进展综述
引用:Li X, Yang X, Ma Z, et al. Deep metric learning for few-shot image classification: A review of recent developments[J]. Pattern Recognition, 2023, 138: 109381.
论文链接: https://arxiv.org/pdf/2105.08149
Abstract 摘要
Few-shot 图像分类是一个具有挑战性的问题,旨在仅基于少量的训练图像实现人类级别的识别能力。小样本图像分类的主要解决方案之一是深度度量学习。这些方法通过在由强大的深度神经网络学习到的嵌入空间中,根据未见样本与少量已见样本之间的距离进行分类,可以避免在小样本图像分类中对少量训练图像的过拟合问题,并且已经取得了最新的性能。在本文中,我们对2018年至2022年间用于小样本图像分类的深度度量学习方法进行了最新的综述,并根据度量学习的三个阶段,即学习特征嵌入、学习类表示和学习距离度量,将这些方法分为三类。通过这种分类法,我们识别了不同方法的新颖性及其面临的问题。我们最后通过讨论当前小样本图像分类中的挑战和未来趋势,来总结这篇综述。
引言
图像分类是机器学习和计算机视觉中的一项重要任务。随着深度学习的快速发展,近年来该领域取得了突破性进展1234。然而,这些进展依赖于收集和标注大量数据(数量级达数百万),这既困难又昂贵。更严重的是,这种学习机制与人类的学习方式形成了鲜明对比,人类通常只需要一个或少量的例子就可以学习一个新的概念5。因此,为了减少对数据的需求并模仿人类智能,许多研究人员开始关注小样本分类678,即从少量(通常为1-5个)标记样本中学习分类规则。
小样本分类面临的最大挑战是模型在少量标记训练样本上容易过拟合。为了解决这个问题,研究人员提出了多种方法,如元学习方法、迁移学习方法和度量学习方法。元学习方法通过在多个不同的分类任务上训练一个元学习器,提取可推广的知识,从而能够在少数样本上快速学习新的相关任务79。迁移学习方法假设源域和目标域之间共享知识,并对在丰富的源数据上训练的模型进行微调,以适应少量标记的目标样本1011。度量学习方法学习特征嵌入6和/或距离度量(或反之,即相似度度量)12,并基于未见样本与标记样本或类表示之间的距离进行分类;同类样本应在嵌入空间中靠近,而不同类样本则应相距较远。需要注意的是,上述方法可以同时应用,例如,通过元学习策略学习度量学习方法的特征嵌入7。
在本文中,我们对近年来用于小样本图像分类的深度度量学习方法进行了综述。度量学习方法值得特别关注,因为一旦度量被学习,它不需要为新类别学习额外的参数,从而能够避免在小样本学习中对新类别的少量标记样本过拟合。此外,它们在基准数据集上的分类性能也非常出色。此外,在本次综述中,我们将度量学习分为三个学习阶段:学习特征嵌入、学习类表示和学习距离度量。这样的分解有助于小样本图像分类和深度度量学习两个基础社区的研究人员之间的思想交流。例如,最新的通用特征嵌入学习进展可以应用于小样本图像分类,而类表示的一种类型——原型学习的思想——可以扩展到长尾视觉识别13。
关于小样本学习(FSL)的若干综述已发表或预印14。14 是关于小样本学习的首个综述,汇总了不同小样本学习场景下的方法,包括零样本学习和小样本学习,以及图像分类、目标检测、视觉问答和神经机器翻译等各种任务。由于该综述在2018年初进行,关于小样本分类的内容相对有限,特别是关于度量学习的方法。15 提供了第一个关于小样本学习的全面综述。除了定义小样本学习并将其与相关的机器学习问题区分开来,作者从监督学习中的误差分解基本角度讨论了小样本学习,并将所有方法按以下几类进行分类:通过增强训练数据来减少估计误差,利用先验知识学习模型以限制假设空间并减少近似误差,学习初始化或优化器以改进在假设空间中搜索最优假设。该综述对度量学习方法的覆盖有限,并将所有度量学习方法归类于学习嵌入模型,这不能完全描述这些方法的优点。16 是另一篇全面的综述,回顾了从2000年代到2020年的文献,并总结了小样本学习在各个领域的应用。该综述包括了早期的非深度度量学习方法,并且由于该综述侧重于元学习方法,因而将最近的深度方法大部分归类为学习度量。与16 将不同的元学习度量学习方法与三种经典方法关联起来相比,我们的综述更深入地探讨了度量学习方法如何演化,以便更好地泛化并在更接近现实的设置中更具适用性。此外,自15 和16 发表以来,小样本学习的快速发展导致提出了大量的新方法,这些新方法在本综述中进行了讨论。17 是2021年最新发表的关于小样本学习的综述,但它完全专注于元学习方法,与我们的工作几乎没有重叠。简而言之,本文提供了关于小样本图像分类的深度度量学习方法的最新综述,并对这些方法的不同组成部分进行了仔细的审查,以理解它们的优缺点。
本文的其余部分组织如下:首先,为了完整性,我们在第1节中给出了小样本分类的定义,并介绍了评估程序和常用的数据集。其次,在第2节中,我们回顾了经典的小样本度量学习算法以及2018年至2022年间发表的有影响力的最新工作。根据度量学习的过程,这些方法被分类为学习特征嵌入、学习类表示和学习距离或相似度度量。最后,我们在第3节讨论了现有方法中的一些剩余挑战及进一步发展的方向,并在第4节总结了本次综述。
1 The Framework of Few-Shot Image Classification
1.1 Notation and definitions
首先,我们通过推广小样本学习的定义12,建立符号并给出各种类型的小样本分类的统一定义。小样本分类涉及两个数据集,即基础数据集和新颖数据集。新颖数据集是执行分类任务的数据集。基础数据集是一个辅助数据集,用于通过迁移知识来帮助分类器的学习。我们用 D b a s e = { ( X i , Y i ) ; X i ∈ X b a s e , Y i ∈ Y b a s e } i = 1 N b a s e D_{base} = \{(X_i, Y_i); X_i \in X_{base}, Y_i \in Y_{base}\}_{i=1}^{N_{base}} Dbase={(Xi,Yi);Xi∈Xbase,Yi∈Ybase}i=1Nbase 表示基础数据集,其中 Y i Y_i Yi 是样本 X i X_i Xi 的类别标签;在图像分类的情况下, X i X_i Xi 表示第 i i i 个图像的特征向量。新颖数据集同样表示为 D n o v e l = { ( X ~ j , Y ~ j ) ; X ~ j ∈ X n o v e l , Y ~ j ∈ Y n o v e l } j = 1 N n o v e l D_{novel} = \{(\tilde{X}_j, \tilde{Y}_j); \tilde{X}_j \in X_{novel}, \tilde{Y}_j \in Y_{novel}\}_{j=1}^{N_{novel}} Dnovel={(X~j,Y~j);X~j∈Xnovel,Y~j∈Ynovel}j=1Nnovel。 D b a s e D_{base} Dbase 和 D n o v e l D_{novel} Dnovel 在标签空间上没有重叠,即 Y b a s e ∩ Y n o v e l = ∅ Y_{base} \cap Y_{novel} = \emptyset Ybase∩Ynovel=∅。为了训练和测试分类器,我们将 D n o v e l D_{novel} Dnovel 分为支持集 D S D_S DS 和查询集 D Q D_Q DQ。
定义 1.
假设支持集
D
S
D_S
DS 是可用的,并且
D
S
D_S
DS 中每个类别的样本量非常少(例如,每个类别有1到5个样本)。小样本分类任务的目标是从
D
S
D_S
DS 中学习一个分类器
f
:
X
n
o
v
e
l
→
Y
n
o
v
e
l
f: X_{novel} \to Y_{novel}
f:Xnovel→Ynovel,该分类器能够正确地对查询集
D
Q
D_Q
DQ 中的实例进行分类。特别地,如果
D
S
D_S
DS 包含
C
C
C 个类别且每个类别有
K
K
K 个标记样本,则该任务被称为
C
C
C-way
K
K
K-shot 分类;如果
D
S
D_S
DS 中每个类别的样本量为1,则该任务被称为 one-shot 分类。
在给出下一个定义之前,我们先介绍域的概念。一个域由两个组成部分构成,即特征空间 X X X 和特征空间上的边缘分布 P ( X ) P(X) P(X)18。
定义 2.
如果基础数据集和新颖数据集来自两个不同的域,即
X
b
a
s
e
≠
X
n
o
v
e
l
X_{base} \neq X_{novel}
Xbase=Xnovel 或
P
(
X
)
≠
P
(
X
~
)
P(X) \neq P(\tilde{X})
P(X)=P(X~),其中
X
∈
X
b
a
s
e
X \in X_{base}
X∈Xbase 且
X
~
∈
X
n
o
v
e
l
\tilde{X} \in X_{novel}
X~∈Xnovel,则小样本分类任务被称为跨域小样本分类任务。
定义 3.
广义小样本分类任务旨在学习一个分类器
f
:
X
n
o
v
e
l
∪
X
b
a
s
e
→
Y
n
o
v
e
l
∪
Y
b
a
s
e
f: X_{novel} \cup X_{base} \to Y_{novel} \cup Y_{base}
f:Xnovel∪Xbase→Ynovel∪Ybase,该分类器能够正确分类查询集
D
Q
D_Q
DQ 中的实例,其中
D
Q
D_Q
DQ 包含来自
D
b
a
s
e
D_{base}
Dbase 的实例-标签对以及现有的
D
n
o
v
e
l
D_{novel}
Dnovel 中的实例-标签对。
1.2 Evaluation procedure of few-shot classification
我们在算法1中提供了评估
C
C
C-way
K
K
K-shot 分类器性能的一般步骤。该评估过程包括多个
e
p
i
s
o
d
e
episode
episode(即任务)。在每个
e
p
i
s
o
d
e
episode
episode中,我们首先从新颖标签集中随机选择
C
C
C 个类别,然后从这
C
C
C 个类别中的每个类别随机选择
K
K
K 个样本组成支持集,并从剩余的样本中选择
M
M
M 个样本组成查询集。令
X
(
e
)
X^{(e)}
X(e) 和
Y
(
e
)
Y^{(e)}
Y(e) 分别表示第
e
e
e 个
e
p
i
s
o
d
e
episode
episode 中查询集的实例集合和标签集合。一个学习算法在接收到基础数据集和第
e
e
e 个支持集后,返回一个分类器
f
(
⋅
∣
D
b
a
s
e
,
D
S
(
e
)
)
f(\cdot | D_{base}, D^{(e)}_S)
f(⋅∣Dbase,DS(e)),该分类器预测查询实例的标签为
Y
^
(
e
)
=
f
(
X
(
e
)
∣
D
b
a
s
e
,
D
S
(
e
)
)
\hat{Y}^{(e)} = f(X^{(e)}| D_{base}, D^{(e)}_S)
Y^(e)=f(X(e)∣Dbase,DS(e))。令
a
(
e
)
a^{(e)}
a(e) 表示第
e
e
e 个
e
p
i
s
o
d
e
episode
episode 中的分类准确率。学习算法的性能通过所有\textit{episode} 的分类准确率的平均值来衡量。

1.3 Datasets for few-shot image classification
在本节中,我们简要介绍了用于小样本图像分类的基准数据集。数据集的统计信息和常用的实验设置如下所列,示例图像如图1所示。
• Omniglot19:这是评估小样本分类算法最广泛使用的数据集之一,包含来自50种语言的1,623个字符。通常通过旋转90度、180度和270度进行数据扩充,得到6,492个类别,这些类别被划分为4,112个基础类、688个验证类和1,692个新颖类。验证类用于模型选择。由于许多方法在5-way 1-shot分类任务上可以达到99%以上的准确率,因此该数据集在最新研究中使用较少。
• Mini-ImageNet 和 Tiered-ImageNet:这两个数据集均源自ImageNet数据集20。Mini-ImageNet包含100个选定的类别,每个类别有600张图像。该数据集最初由Vinyals等人提出7,但最近的研究遵循Ravi和Larochelle21提供的实验设置,将100个类别分为64个基础类、16个验证类和20个新颖类。Tiered-ImageNet是一个更大的数据集,具有层次结构22,它由34个超类构成,总共有608个类别,包括779,165张图像。这些超类被分为20个基础类、6个验证类和8个新颖超类,分别对应351个基础类、97个验证类和160个新颖类。
• CIFAR-FS 和 FC100:这两个数据集源自CIFAR-10023。CIFAR-FS24包含100个类别,每个类别有600张图像,分为64个基础类、16个验证类和20个新颖类。FC10025将100个类别划分为20个超类,每个超类包含五个类别。该数据集被分为12个基础超类、4个验证超类和4个新颖超类。
• Stanford Dogs26:这是一个用于细粒度分类任务的基准数据集,包含120种狗的品种(类别),共有20,580张图像。这些类别被分为70个基础类、20个验证类和30个新颖类。
• CUB-200-2011:这是一个细粒度鸟类分类数据集,包含200个类别,共有11,788张图像。根据27,该数据集通常被划分为100个基础类、50个验证类和50个新颖类。
• Mini-ImageNet → CUB:这是用于跨域小样本分类的数据集。Mini-ImageNet作为基础数据集,CUB-200-2011的50个类别作为验证类,剩下的50个类别作为新颖类。
• Meta-Dataset:这是一个用于评估小样本分类方法的新大型数据集,特别是跨域方法。最初由10个不同的图像数据集组成28,如ImageNet、CUB和MS COCO29,后来扩展了三个额外的数据集30。该数据集有两种训练程序和两种评估协议。在更常用的设置下,所有数据集上的训练(多域学习)303132,方法在前八个数据集的官方训练集上进行训练,并在相同数据集的测试集上评估域内性能,并在其余五个数据集上评估域外性能。另一种设置是仅在Meta-Dataset版本的ImageNet上训练(单域学习),并在ImageNet的测试集上评估域内性能,而在其余12个数据集上评估域外性能。
2 Few-Shot Deep Metric Learning Methods
监督度量学习的目标是学习实例对之间的距离度量,该度量为语义上相似的实例分配较小的距离,为语义上不同的实例分配较大的距离。在小样本分类的情况下,度量是在基础数据集上学习的;新颖类别的查询图像通过计算它们与新颖支持图像相对于学习到的度量的距离来分类,随后应用基于距离的分类器,如 k k k 近邻(kNN)算法。传统的度量学习方法学习的是马氏距离(Mahalanobis distance),其等价于对原始特征进行线性变换的学习33。然而,在深度度量学习中,距离度量和特征嵌入通常是分开学习的,以捕捉非线性数据结构并生成更具判别性的特征表示。此外,许多小样本度量学习方法并不是与单个样本进行比较,而是与类表示(如原型和子空间)进行比较。在本节的剩余部分,我们对代表性的方法进行了回顾,并根据它们改进的方面分为三类:1)学习特征嵌入,2)学习类表示,3)学习距离或相似度度量。图2中提供了这些方法的总结。
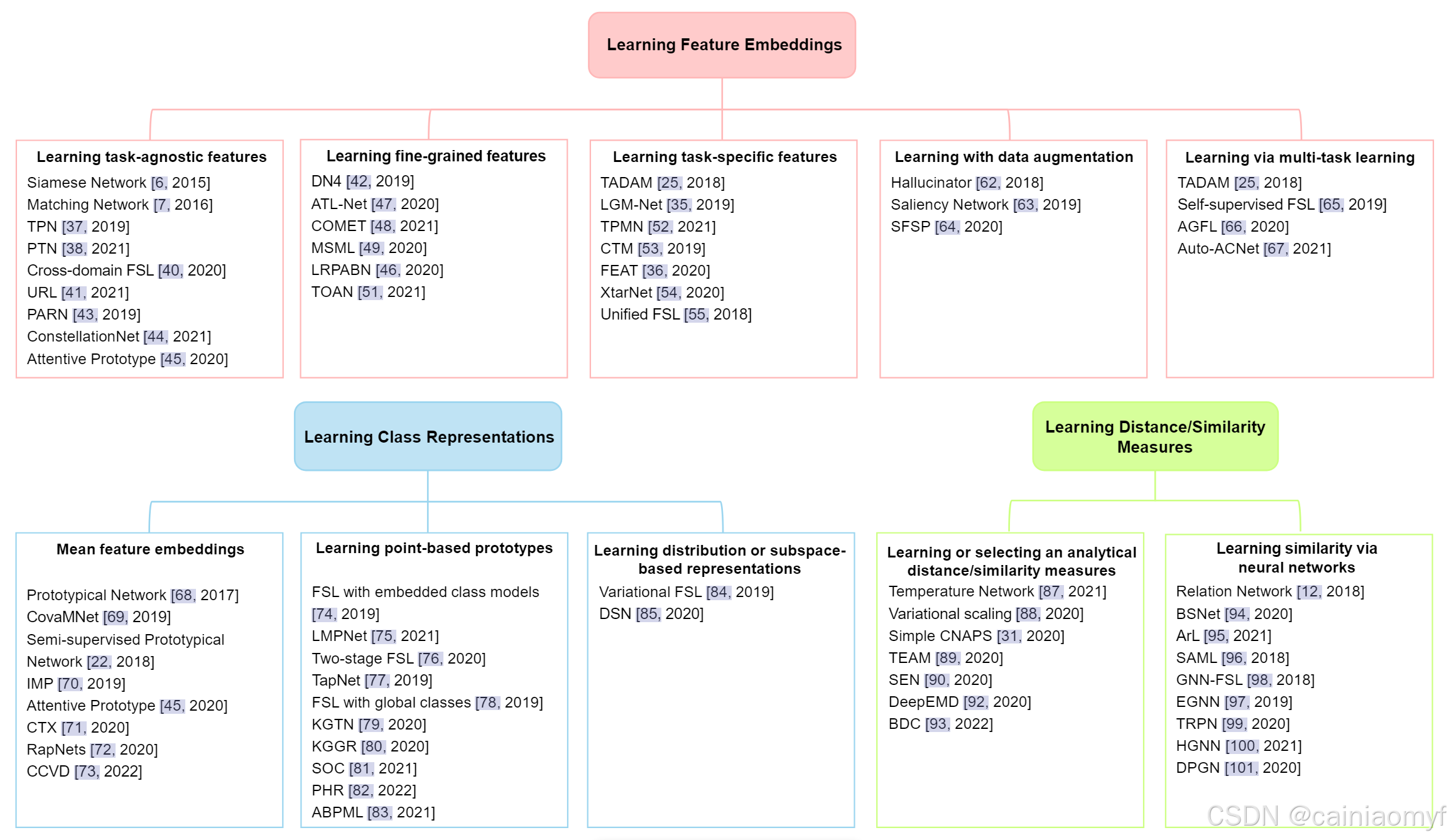
图2:本文回顾的少镜头深度度量学习方法的分类。一些方法有助于度量学习的两个方面,因此出现两次。
2.1 学习特征嵌入
学习特征嵌入的方法隐含假设网络能够提取具有判别性的特征,并且能够很好地泛化到新颖类。早期的方法旨在学习一个对任何任务都有效的任务无关的嵌入模型。近年来,研究人员更多地致力于学习任务特定的嵌入模型,以更好地区分当前的类别。此外,为了解决数据稀缺和过拟合的问题,利用了数据增强和多任务学习的技术。
2.1.1 学习任务无关的特征
Siamese卷积神经网络6 是第一个用于一次性图像分类的深度度量学习方法。Siamese网络最早由34 引入,它由两个具有相同架构和共享权重的子网络组成。6 采用了VGG风格的卷积层作为子网络,从两个图像中提取高级特征,并使用加权的 L 1 L_1 L1 距离作为两个特征向量之间的距离。网络的权重以及分量间距的权重是通过小批量梯度下降的传统技术进行训练的。
Matching Network7 在整个支持集的背景下使用不同的网络对支持图像和查询图像进行编码,并首次将情景训练引入小样本分类。支持图像通过一个双向LSTM网络进行嵌入,该网络不仅考虑图像本身,还考虑集合中的其他图像;查询图像通过带有注意机制的LSTM进行嵌入,以依赖于支持集。然而,双向LSTM的顺序特性导致特征嵌入会随着支持集中样本顺序的不同而变化。此问题可以通过应用池化操作35 或使用自注意力机制36 来规避。
Matching Network的分类机制非常适合小样本学习。网络通过计算所有支持样本的单热标签向量的凸组合输出标签分布,组合系数由余弦相似度上的softmax定义;具有最高概率的类别被选为预测类别。7 的另一个有价值的贡献是情景训练策略,许多后续工作采用了这一策略。遵循元学习的思想,基础数据集上的训练阶段应该模拟仅有少量支持样本的预测阶段。也就是说,梯度更新应在从基础标签集中随机采样的 C C C 个类别以及每个类别的 K K K 个示例上进行。
情景训练策略缩小了训练分布和测试分布之间的差距,从而减轻了在少量标记训练图像上的过拟合问题。通过利用查询实例(即排除查询标签)进行迁移推理,也可以从另一个角度解决这一问题。迁移传播网络(TPN)37 是第一个采用迁移推理用于小样本学习的工作,并引入了标签传播的思想。具体而言,该网络包含一个特征嵌入模块和一个图构建模块。图构建模块以特征嵌入为输入,学习一个标签传播图,以利用支持样本和查询样本的流形结构。特别是,使用高斯核构建一个 k k k 近邻图,其尺度参数是以示例为单位进行学习的。基于该图,标签从支持集传播到查询集;使用标签传播的封闭形式解来加速预测过程。泊松迁移网络(PTN)38 通过应用泊松学习算法39 改进了标签传播方案,该算法在理论上已被证明更加稳定和信息丰富,尤其是在标签极少的情况下。PTN主要用于半监督小样本分类,在查询样本之外还利用了额外的未标记数据,并通过对比自监督学习增强了特征嵌入,同时通过使用图切割方法改进了推理过程。
上述方法主要用于从同一域中分类新数据,当新数据来自不同域时效果会下降27。Tseng等人40 注意到这是由不同域中特征分布之间的巨大差异引起的,并提出在训练阶段模拟各种特征分布作为增强度量学习方法域泛化能力的一般解决方案。通过在特征提取器中插入多个特征变换层实现了这一点;每个变换模拟一个分布,仿射变换的超参数可以通过元学习方法进行调整,从而最优地适应特定的度量学习方法并捕捉特征分布中的复杂变化。Li等人41 提出了学习一个适用于多个域的通用特征表示。该技术应用了知识蒸馏,学习了一个多域网络以生成与多个单域网络特征一致的通用特征,最多只进行线性变换。
基于对象可能仅位于图像的某个区域,并且在不同图像中处于不同位置的观察,一系列关于特征嵌入的改进被提出,如通过学习局部特征42 和编码位置信息43。前者的类型虽然可以应用于通用的小样本图像分类,但对于细粒度图像分类特别有效。因此,我们将在下一小节中单独讨论它们,这里仅关注位置信息编码方法。Wu等人43 提出了位置感知关系网络(PARN),以减少关系网络(将在第2.3.2节中介绍)对语义对象空间位置的敏感性。PARN采用可变形卷积层来提取更有效的特征,过滤掉诸如背景等不相关的信息,并通过双相关注意模块将图像的每个空间位置与对比图像和图像本身的全局信息相结合,从而使后续的卷积操作,即使局限于局部连接,也能够感知和比较不同位置的语义特征。与使用较大卷积核或更多卷积层的标准方法相比,PARN的参数效率更高。Xu等人44 提出了ConstellationNet,通过使用显式的、可学习的位置编码,自注意机制来提取基于部分的特征,并编码这些表示之间的空间关系。通过使用胶囊网络,图像不同部分之间的空间关系在45 中也进行了编码。
2.1.2 针对细粒度图像分类的任务无关特征学习
细粒度图像分类旨在区分同一基本类别下的不同子类别。由于不同子类别之间存在细微差异,而同一子类别内部可能因对象姿势、尺度、旋转等变化而具有较大差异,这一任务尤其具有挑战性。因此,为了实现有效分类,提出了多种方法来提取局部特征、多尺度特征和二阶特征。
在深度最近邻神经网络(DN4)42中,特征嵌入模块从图像中提取多个局部描述符,实质上是通过CNN学习的特征映射,并在添加最终图像级池化层之前获得。在分类过程中,采用图像到类别级别的方式进行,这意味着将同一类别的支持图像的局部描述符放入一个池中,并针对每个查询局部描述符在每个类别池中搜索最近邻。所有局部描述符与最近邻的总距离即为查询图像与相应类别之间的距离。该方法在细粒度数据集上表现尤为出色,学习局部描述符的理念也被其他细粒度分类方法所采用46。自适应任务感知局部表示网络(ATL-Net)47通过使用学习阈值选择局部描述符,并根据情节化注意力为其赋予不同权重,从而改进了DN4方法。这种改进带来了比kNN更大的灵活性,并对类别之间的可区分性进行了调整。与在局部空间区域上学习一个特征嵌入不同,COMET 48在输入特征的不同部分上学习了多个嵌入函数。一组固定的二进制掩码,称为概念,被应用于输入特征,将图像分割成人类可解释的片段。对于每个概念,学习一个特征嵌入以将掩码后的特征映射到一个新的判别性特征空间。查询图像根据所有概念特定空间中聚合的距离进行分类。
多尺度度量学习(MSML)网络49同样构建了多个特征嵌入,但与COMET不同的是,每个嵌入对应于图像的不同尺度。支持和查询特征在每个尺度上的相似性通过关系网络进行计算。
Huang等人46提出了低秩成对对齐双线性网络(LRPABN),该网络在空间上对齐特征并提取区分性的二阶特征。在从基础图像中学习一阶特征后,该方法训练了一个包含两层的多层感知器(MLP)网络,使用两个设计的特征对齐损失将查询图像的特征位置转换为与支持图像匹配,并设计了一个低秩成对双线性池化层,该层适应了自双线性池化方法50,从一对支持和查询图像中提取二阶特征。分类过程与关系网络中的方法相同。在后续工作中,51通过使用跨通道注意力来生成空间匹配的支持和查询特征,并在池化层之前在卷积通道维度中对特征进行分组,以便每个组对应于一个语义概念,从而改进了空间对齐部分。
2.1.3 学习任务特定的特征
前面章节中回顾的方法,无论后续的分类任务是什么,对每张图像都生成相同的特征嵌入。虽然这避免了过拟合的风险,但这些通用特征可能不足以区分新的类别。因此,提出了任务特定的嵌入模型,将特征调整为特定任务;需要注意的是,这种调整是在基础数据集上学习的,并不涉及在新数据集上的重新训练。
TADAM 25 是第一个明确执行任务适应的度量学习方法。它利用条件批归一化技术,对任务无关特征提取器的每个卷积层进行任务特定的仿射变换。任务由类别原型的平均值表示,仿射变换的尺度和偏移参数则由一个独立的网络生成,称为任务嵌入网络(TEN)。由于TEN引入了更多的参数,导致优化难度增加,训练方案被调整为将标准训练(即区分基础数据集中的所有类别)作为辅助任务,加入到情节化训练中。
Li等人35 提出了一种元学习方法,可以将Matching Network的权重适应于新数据。所提出的LGM-Net包含一个称为MetaNet的元学习器和一个称为TargetNet的任务特定学习器。MetaNet模块学习从支持集生成每个任务的表示,并构建从该表示到TargetNet权重的映射。TargetNet模块设置为Matching Network,嵌入支持图像和查询图像并执行分类。这种元学习策略可用于其他度量学习方法的网络参数调整。Wu等人52也提出了学习任务特定参数的方法,但将其与局部特征相结合。所提出的任务感知部件挖掘网络(TPMN)学习生成用于提取基于部件特征的滤波器参数。
与上述两种生成任务特定嵌入层参数的工作不同,Li等人53提出了修改任务无关嵌入层输出的通用特征。一个任务特定的特征掩码由类别遍历模块(CTM)生成,该模块包括一个集成器单元和一个投射器单元,分别用于提取类内共性和类间独特性特征。值得注意的是,CTM可以很容易地嵌入到大多数少样本度量学习方法中,例如Matching Network、Prototypical Network和Relation Network;后两种方法将在后续章节中介绍。Ye等人36同样提出了直接调整特征的方法,但不是使用掩码,而是使用集合到集合的函数将任务无关特征转换为任务特定特征。这些函数可以对集合中图像的相互作用进行建模,从而实现对每张图像的协同适应。36中提出了四种集合到集合函数近似器,其中带有Transformer的函数,称为FEAT,显示出最有效的性能。
Yoon等人54提出了XtarNet来为广义少样本学习的新设置学习任务特定特征,其中模型在基础数据集上进行训练,在新数据集的支持集上进行适应,然后用于对基础和新类别的实例进行分类。XtarNet包含三个元学习器。MetaCNN模块针对每个任务调整特征嵌入。MergeNet模块生成用于混合预训练特征和元学习特征的权重。由于分类是通过将混合特征与类别原型进行比较来执行的,TconNet模块会调整基础和新类别的原型以提高区分性。Rahman等人55提出了一个统一的方法,用于零样本学习、广义零样本学习和少样本学习,该方法基于查询图像的语义表示与每个类别的文本特征之间的相似性进行分类。语义表示由两部分组成——一部分是基础样本语义特征的线性组合,另一部分基于从支持图像学习到的线性映射。
2.1.4 数据增强的特征学习
数据增强是一种通过人工或基于模型的方法使用保持标签不变的转换来扩展支持集的策略,因此在支持样本有限的情况下非常适用。常用的方法包括变形56 57 58,如裁剪、填充和水平翻转。此外,生成更多训练样本59 60和伪标签61也是常见的数据增强技术。
在少样本学习中,有一类方法将数据增强过程嵌入到模型中,即嵌入一个能够生成增强数据的生成器,以学习或想象数据的多样性。Wang等人62构建了一种端到端的少样本学习方法,其中训练数据通过两个流进入输出——一个是直接从原始数据到分类器,另一个则是通过一个“幻觉”网络对数据进行增强,然后再由增强后的数据进入分类器。Zhang等人63开发了一种基于显著性的数据生成策略,显著性网络获取图像的前景和背景,并利用这些信息来实现图像的幻觉生成。
在64中,提出了一种更简单的特征合成策略,通过扰动语义表示(即类别标签的词向量)并将其投射到视觉特征空间来合成新的特征。此外,在学习投影函数时,采用了一种竞争性学习公式,将合成的样本推向最可能的未见类别的中心,并远离次优类别的中心。
2.1.5 多任务特征学习
除了生成更多的训练数据外,一些研究尝试利用样本的辅助信息来执行多任务学习,从而产生正则化效果,帮助学习到更具区分性的特征。
如前所述,TADAM 25使用了在基础数据集上训练一个正常的全局分类器作为辅助任务,与少样本分类器一起进行协同训练;训练过程中以一定概率抽取该任务。Gidaris等人65提出了一种结合自监督学习的少样本学习方法,具体而言,将支持样本进行人工旋转到不同的角度。通过两个网络分支来学习共享的特征嵌入,一个用于原始分类任务,另一个用于识别旋转角度。
Zhu等人66指出,尽管基础类和新类是互不相交的,但可以通过一些视觉属性将它们连接起来。基于这一见解,他们将属性学习作为辅助任务。在训练期间,视觉属性作为附加信息提供,嵌入网络学习正确预测属性标签和类别标签。67同样利用了属性信息,但更为丰富,需要对图像对中的共同属性和不同属性进行额外预测。此外,神经架构搜索首次被引入到少样本学习中,以自动识别特征嵌入网络和属性学习网络中最佳的操作,例如最大池化、卷积、恒等映射等。
2.2 学习类别表示
早期的少样本度量学习方法,如Siamese Network和Matching Network,通过测量和比较查询样本与支持样本之间的距离来进行分类。然而,由于支持样本数量有限,它们在表示新类别时的能力受到限制。为了解决这一问题,一些研究人员提出使用类别原型,作为每个类别的参考向量。原型可以通过对特征嵌入进行简单或加权平均来构建,或通过端到端的方式学习以进一步提高其表示能力。除了基于点的原型外,一些工作还考虑了每个类别的分布,或使用子空间作为类别表示。
2.2.1 基于特征嵌入的原型
Prototypical Network68是一种经典的方法,它通过计算在学习嵌入空间中到类别原型的欧氏距离来进行分类。该方法基于这样一个假设:存在一个嵌入空间,在该空间中,每个类别可以由单个原型表示,所有实例都聚集在对应类别的原型周围。68中,每个类别的原型设定为该类别中支持样本特征嵌入的平均值。特征嵌入以及类别原型通过情节化训练进行学习,目标是最小化交叉熵损失。在69中,类别原型使用特征嵌入的协方差矩阵表示,同时还提出了基于协方差的度量,用于衡量查询样本与类别之间的相似性。
为了利用标记的支持样本和未标记样本,Ren等人22提出了半监督的Prototypical Network,这是首个半监督少样本学习工作。该方法采用软k-means计算未标记样本的分配得分,并基于分配得分将原型计算为加权样本的平均值。
考虑到数据集可能具有多模态特性,多个原型在这种情况下可能更为合适,Infinite Mixture Prototypes(IMP)70对每个类别中的多个簇进行建模,每个簇被建模为高斯分布。具体而言,样本遵循每个簇的高斯分布的概率决定了样本被分配到哪个簇。此外,需要学习的高斯分布的簇方差会影响类别原型的数量和IMP的性能。
Wu等人45提出了计算查询依赖原型的方法。为每个查询计算一个注意力原型,作为支持样本的加权平均值,权重由查询与支持样本之间的欧氏距离的高斯核确定。由于与查询更相关的支持样本对分类影响更大,该方法对支持样本中的异常值更具鲁棒性。查询依赖原型也在CrossTransformers(CTX)71中进行了研究,但它们是针对每个空间位置单独计算的。换句话说,查询图像的局部区域与特定于该查询和区域的注意力原型进行比较,查询与原型之间的总体距离是所有局部区域距离的平均值。此外,CTX通过自监督情节进行训练。
Lu等人72专注于增强原型对异常值和标签噪声的鲁棒性,提出了鲁棒注意力轮廓网络(RapNets)。该网络以非参数的方式将原始特征嵌入转换为相关特征,然后将这些特征输入到参数化的双向LSTM和全连接网络中,以生成作为权重的注意力得分,来组合支持图像。此外,训练情节进行了修订以包含噪声数据,并提出了一种新的评估指标来评估少样本分类方法的鲁棒性。
Ma等人73对Prototypical Network进行了几何解释,将其视为一种Voronoi图。此外,作者扩展了这一观点,提出了簇对簇Voronoi图(CCVD),该方法可以将不同数据增强下学习的模型进行集成,构建在单一或多重特征变换上,并使用线性或最近邻分类器。
2.2.2 基于点的可学习原型
Ravichaandran等人74采用了一种隐式的方法来学习类别表示,而不是像之前的方法那样确定类别原型。该方法将原型建模为一个可学习和参数化的函数,用于表示类别中标记样本的特征嵌入,并通过最小化样本特征嵌入与类别原型之间的距离来获得原型。同时,该函数与样本数量无关,允许在新数据中类别样本数目不平衡的情况。
在75中,原型由特征嵌入的加权平均表示,但与上一节讨论的22 45不同,权重通过情节化训练进行端到端学习。此外,除了使用图像级特征,75还结合了一个类别的局部描述符(借鉴了DN4的思想),并学习了多个权重向量来为每个类别生成多个原型。Das和Lee76提出了一种两阶段生成类别原型的方法。第一阶段中,学习特征嵌入,从中可以获得基础类和新类的粗略原型。第二阶段中,新类原型通过自身原型和相关基础原型的元可学习函数进行精化。
除了上述方法,TapNet77将类别原型显式建模为可学习参数。原型和特征嵌入在基础数据集上与Prototypical Network的训练流程一起同时学习。此外,为了使原型和特征嵌入更适应当前任务,二者通过线性投影矩阵投射到一个新的分类空间中。该投影矩阵通过线性零化操作获得,不包含任何可学习参数。Luo等人78提出在训练过程中同时包含新类的支持集,以同时学习基础类和新类的原型。在每个情节中,从样本合成模块中生成局部原型,以增加新类的多样性。然后在注册模块中使用这些原型来更新全局原型,以实现更好的可分离性。查询图像通过在全局原型中搜索最近邻来分类。由于基础和新类原型都是可学习的,该方法可直接应用于广义少样本学习设置。Chen等人79的目标与之相同,也是学习基础类和新类原型,但进一步利用了这些类别之间的语义关联。提出了知识图谱迁移网络(KGTN),该网络使用门控图神经网络将类别原型和关联分别表示为节点和边。通过在图上传播信息,相关基础类的信息被用于指导新原型的学习。这项工作在80中扩展到了多标签分类设置,采用了注意力机制和额外的图来学习类别特定的特征向量。
在81中,提出了共享对象集中器(SOC)算法,用于从支持图像的局部特征中为每个新类学习一系列原型。第一个原型与其中一个局部特征的余弦相似度最大,第二个原型与第二大的特征相似,依此类推。查询图像根据其局部特征与所有原型之间的相似度的加权和进行分类,权重以指数衰减来考虑原型的影响力递减。Zhou等人82提出了渐进式层次细化(PHR)方法,利用所有新数据迭代更新原型。在每次迭代中,将支持图像和一部分随机查询图像嵌入到局部、全局和语义级别的特征中,并使用定义在这些层次特征上的损失函数来细化原型以获得更好的类别间可分离性。由于每次更新基于随机查询子集,该方法不太可能对噪声查询样本过拟合,但它隐式假设存在大量查询样本。
Sun等人83提出将原型视为随机变量。通过使用摊销变分推理技术,学习潜在类别原型的后验分布,这种技术使得原型学习可以被表示为一个概率生成模型,而不会遇到严重的计算和推理困难。
2.2.3 基于分布或子空间的表示
考虑到单点度量学习对噪声敏感,Zhang等人84提出了一种用于少样本学习的变分贝叶斯框架,并使用Kullback-Leibler散度来衡量样本之间的距离。该框架可以通过基于神经网络估计每个类别的分布来计算将查询图像分配到每个类别的置信度。
Simon等人85提出了深度子空间网络(DSN),该网络使用奇异值分解从支持样本中构建每个类别的低维子空间。查询样本根据最近子空间分类器进行分类,即将查询分配给与其投影到类别特定子空间之间具有最短欧氏距离的类别。结果显示,该方法比Prototypical Network对噪声和异常值更具鲁棒性。
2.3 学习距离或相似度度量
第2.1和2.2节中回顾的方法侧重于学习区分性特征嵌入或获取准确的类别表示。在分类过程中,它们通常采用固定的距离或相似度度量,例如欧氏距离68和余弦相似度7。最近,研究人员开始尝试在这些固定度量中学习参数或定义新的度量,以进一步提高分类准确性。此外,还通过全连接神经网络或图神经网络(GNN)来学习相似度得分。
2.3.1 学习或选择解析的距离或相似度度量
在TADAM25中,Oreshkin等人对度量缩放对损失函数的影响进行了数学分析。从那时起,许多工作通过交叉验证来调整缩放参数47 86。Zhu等人87提出对真实类别和其他类别使用两个不同的缩放参数,确保同类距离远小于异类距离。此外,缩放参数在几个情节后逐步调整,实现了从易到难的自适应学习。Chen等人88在贝叶斯框架中学习缩放参数,假设一元或多元高斯先验,并采用随机变分推理技术来逼近后验分布,可以分别学习到缩放参数或缩放向量,进而在各维度上等比例或不同地调整距离。
传统的马氏距离通过使用协方差矩阵的逆来去相关和缩放特征。在Simple CNAPS31中,使用条件神经自适应过程(CNAPS)30的架构来提取特征,分类则基于查询样本和类别原型之间的马氏距离进行。任务特定的类别特定协方差矩阵作为任务样本和类别样本估计的样本协方差矩阵的凸组合,并正则化为单位矩阵。Transductive Episodic-wise Adaptive Metric(TEAM)89则从支持和查询样本中学习任务特定的度量。
Nguyen等人90提出了一种称为SEN的不相似度量,它结合了欧氏距离和L2范数的差异。最小化该度量将鼓励特征归一化,从而提升分类性能91。DeepEMD92结合了稠密图像表示上的结构距离、地球移动距离(EMD)和卷积特征嵌入来进行少样本学习。Xie等人93引入了基于随机向量特征函数的布朗尼亚距离协方差(BDC)度量,这一新度量对于离散特征向量具有闭式表达式。
2.3.2 通过神经网络学习相似度得分
Relation Network12首次将神经网络引入少样本学习中的特征嵌入相似度建模。它由嵌入模块和关系模块组成,嵌入模块将原始图像映射到嵌入空间,关系模块则通过两层卷积块和全连接层计算每对支持与查询图像之间的相似度。Li等人94提出单一相似度度量可能不足以学习细粒度图像分类的区分性特征,因此提出了双相似度网络(BSNet),它通过引入余弦模块来补充关系模块。
与Relation Network不同,语义对齐度量学习(SAML)95采用多层感知器(MLP)网络来计算相似度得分。SAML包含特征嵌入模块和语义对齐模块,在语义对齐模块中,首先通过固定的相似度度量和注意力机制计算局部特征层面的关系矩阵,然后将其输入MLP网络,输出查询与支持类之间的相似度得分。
最近,一些研究人员采用图神经网络(GNNs)进行少样本分类。Garcia等人96提出了首个基于GNN的少样本学习神经网络(GNN-FSL)。GNN-FSL包含两个模块:特征嵌入模块和GNN模块。在GNN模块中,每个节点表示一个样本,初始标签在第一层GNN中使用均匀分布,并在最后一层GNN中用于计算损失函数。
与GNN-FSL类似,边标记图神经网络(EGNN)97也包含特征嵌入模块和具有三层的GNN模块,但它对GNN层中的边进行标记,通过利用簇内相似性和簇间不相似性来显式地对样本进行聚类。
Transductive Relation-Propagation图神经网络(TRPN)98将支持-查询对视为图节点并显式建模它们的关系。在关系传播后,学习相似度函数来映射更新后的节点到相似度得分。分数和最高的类别即为预测类别。Hierarchical Graph Neural Network(HGNN)99旨在对类别内的层次结构进行建模,首先对支持节点进行下采样以构建层次结构图,然后上采样以重构所有支持节点进行预测。
之前的GNN方法侧重于样本对间的关系,分布传播图网络(DPGN)100则考虑样本与所有支持样本的全局关系,生成相似度向量的分布特征,采用双重完全图来独立处理样本级和分布级特征,并通过循环更新策略在两个图之间进行传播,分布图中的信息可细化样本级节点特征,从而基于边缘相似度提高分类性能。
3 Challenges and Future Directions
尽管小样本度量学习方法已经取得了令人期待的性能,但仍有几个重要的挑战需要在未来解决。
- 改进在少量样本上的泛化特征学习
关于特征学习,在现有的小样本度量学习方法中,甚至在整个小样本学习方法中,研究人员大多尝试基于注意力机制、数据增强、多任务学习等方法学习判别特征。为了从少量标记样本中学习具有良好泛化能力的特征,需要开发新的评估和特征学习方法。
- 重新思考情景训练策略的使用
虽然情景训练是训练小样本学习中的度量学习方法的常见做法,但要求每个训练\textit{episode}与评估\textit{episode}具有相同的类别数量和图像数量是刚性的。事实上,68 观察到使用更多类别进行训练有利于模型。此外,模型在接收到\textit{episode}后会立即更新,而不考虑其质量,因此容易受到如离群点等采样不佳的图像的影响。101 是首次尝试通过利用\textit{episode}之间的关系来缓解这一问题的工作,但需要更多的解决方案来识别高质量且对新任务有用的\textit{episode}。此外,我们注意到情景训练可能导致模型对基础数据集的欠拟合。一个可能的原因是,使用情景训练的方法会在从基础数据集中采样的众多任务上进行持续学习,从而遭受灾难性遗忘 102103,即模型从以前任务中学到的知识在学习新任务后被取代。因此,如何避免这一问题并增强度量学习方法在基础和新颖数据集上的拟合能力仍然是一个挑战。
- 提高对支持样本的稳定性和对对抗扰动及分布偏移的鲁棒性
尽管分类准确性不断提高,小样本分类方法在多种场景下仍然脆弱,这限制了它们在医疗图像分析等安全关键应用中的使用。现有工作表明,现有方法对输入或标签离群点 72、对支持图像104或查询图像105添加的对抗扰动(即数据的微小且视觉上无法察觉的变化,使分类器作出错误预测),以及支持集和查询集之间的分布偏移 106 均表现出非鲁棒性。在 107 中,甚至没有扰动且在分布内的支持图像也能显著降低一些流行方法的分类准确性。进一步探索现有方法中的脆弱性,并设计鲁棒且稳定的模型将非常有价值。
- 开发用于跨域小样本分类的度量学习方法
尽管在实际中基础数据集和新颖数据集可能来自不同的域,但目前只有少数工作关注跨域小样本分类。最近,108 报道了在存在较大域偏移时,所有经过元训练的方法(包括所述的40)都被简单的迁移微调方法超越,特别是在训练基于自然图像并在农业和卫星图像等领域进行评估时。困难在于基础数据和新数据通常具有不同的度量空间。因此,如何减轻训练和评估阶段之间的域偏移需要在未来进行探索。
4 Conclusions
本文对近年来的小样本深度度量学习方法进行了综述。我们首先提供了小样本学习的定义和一个通用的评估框架,然后对代表性的方法进行了分类和回顾,最后总结了主要的挑战。基于这些挑战,未来可以进一步探索几个新的研究方向。
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, pp. 1097– 1105, 2012. ↩︎
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014. ↩︎
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–9, 2015. ↩︎
J. Gu, Z. Wang, J. Kuen, L. Ma, A. Shahroudy, B. Shuai, T. Liu, X. Wang, and G. Wang, “Recent advances in convolutional neural networks,” arXiv preprint arXiv:1512.07108, 2015. ↩︎
F.-F. Li, R. Fergus, and P. Perona, “One-shot learning of object categories,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 4, pp. 594–611, 2006. ↩︎
G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for one-shot image recognition,” in International Conference on Machine Learning deep learning workshop, vol. 2, 2015. ↩︎ ↩︎ ↩︎ ↩︎
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, et al., “Matching networks for one shot learning,” in Advances in Neural Information Processing Systems, pp. 3630–3638, 2016. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap, “One-shot learning with memory-augmented neural networks. arxiv preprint,” arXiv preprint arXiv:1605.06065, 2016. ↩︎
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International Conference on Machine Learning, pp. 1126–1135, JMLR. org, 2017. ↩︎
M. Rohrbach, S. Ebert, and B. Schiele, “Transfer learning in a transductive setting,” inAdvances in Neural Information Processing Systems, pp. 46–54, 2013. ↩︎
Q. Sun, Y. Liu, T.-S. Chua, and B. Schiele, “Meta-transfer learning for few-shot learning,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 403–412, 2019. ↩︎
F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 1199–1208, 2018. ↩︎ ↩︎ ↩︎
Z. Liu, Z. Miao, X. Zhan, J. Wang, B. Gong, and S. X. Yu, “Large-scale long-tailed recognition in an open world,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2537–2546, 2019. ↩︎
J. Shu, Z. Xu, and D. Meng, “Small sample learning in big data era,” arXiv preprint arXiv:1808.04572, 2018. ↩︎ ↩︎
Y. Wang, Q. Yao, J. T. Kwok, and L. M. Ni, “Generalizing from a few examples: A survey on few-shot learning,” ACM Computing Surveys, vol. 53, no. 3, pp. 1–34, 2020. ↩︎ ↩︎
J. Lu, P. Gong, J. Ye, and C. Zhang, “Learning from very few samples: A survey,” arXiv preprint arXiv:2009.02653, 2020. ↩︎ ↩︎ ↩︎
X. Li, Z. Sun, J.-H. Xue, and Z. Ma, “A concise review of recent few-shot meta-learning methods,” Neurocomputing, vol. 456, pp. 463–468, 2021. ↩︎
S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345–1359, 2009. ↩︎
B. Lake, R. Salakhutdinov, J. Gross, and J. Tenenbaum, “One shot learning of simple visual concepts,” in Proceedings of the annual meeting of the cognitive science society, vol. 33, 2011. ↩︎
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al., "ImageNet large scale visual recognition challenge,"International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015. ↩︎
S. Ravi and H. Larochelle, “Optimization as a model for few-shot learning,” International Conference on Learning Representations, 2017. ↩︎
M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semi-supervised few-shot classification,” International Conference on Learning Representations, 2018. ↩︎ ↩︎ ↩︎
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, 2009. ↩︎
L. Bertinetto, J. F. Henriques, P. H. Torr, and A. Vedaldi, “Meta-learning with differentiable closed-form solvers,” International Conference on Learning Representations, 2019. ↩︎
B. Oreshkin, P. R. López, and A. Lacoste, “TADAM: Task dependent adaptive metric for improved few-shot learning,” in Advances in Neural Information Processing Systems, pp. 721–731, 2018. ↩︎ ↩︎ ↩︎ ↩︎
A. Khosla, N. Jayadevaprakash, B. Yao, and F.-F. Li, “Novel dataset for fine-grained image categorization: Stanford dogs,” in CVPR Workshop on Fine-Grained Visual Categorization, vol. 2, 2011. ↩︎
W.-Y. Chen, Y.-C. Liu, Z. Kira, Y.-C. F. Wang, and J.-B. Huang, “A closer look at few-shot classification,” in International Conference on Learning Representations, 2019. ↩︎ ↩︎
E. Triantafillou, T. Zhu, V. Dumoulin, P. Lamblin, U. Evci, K. Xu, R. Goroshin, C. Gelada, K. Swersky, P. Manzagol, and H. Larochelle, “Meta-dataset: A dataset of datasets for learning to learn from few examples,” in International Conference on Learning Representations, 2020. ↩︎
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: common objects in context,” in European conference on computer vision, pp. 740–755, Springer, 2014. ↩︎
J. Requeima, J. Gordon, J. Bronskill, S. Nowozin, and R. E. Turner, “Fast and flexible multi-task classification using conditional neural adaptive processes,” in Advances in Neural Information Processing Systems, 2019. ↩︎ ↩︎ ↩︎
P. Bateni, R. Goyal, V. Masrani, F. Wood, and L. Sigal, “Improved few-shot visual classification,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14493–14502, 2020. ↩︎ ↩︎
W. Li, X. Liu, and H. Bilen, “Cross-domain few-shot learning with task-specific adapters,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. ↩︎
E. Xing, M. Jordan, S. J. Russell, and A. Ng, “Distance metric learning with application to clustering with side-information,” Advances in Neural Information Processing Systems, vol. 15, pp. 521–528, 2002. ↩︎
J. Bromley, J. W. Bentz, L. Bottou, I. Guyon, Y. LeCun, C. Moore, E. Säckinger, and R. Shah, “Signature verification using a “siamese” time delay neural network,” International Journal of Pattern Recognition and Artificial Intelligence, vol. 7, no. 04, pp. 669–688, 1993. ↩︎
H. Li, W. Dong, X. Mei, C. Ma, F. Huang, and B.-G. Hu, “LGM-Net: Learning to generate matching networks for few-shot learning,” in International Conference on Machine Learning, pp. 3825–3834, 2019. ↩︎ ↩︎
H.-J. Ye, H. Hu, D.-C. Zhan, and F. Sha, “Few-shot learning via embedding adaptation with set-to-set functions,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8808–8817, 2020. ↩︎ ↩︎ ↩︎
Y. Liu, J. Lee, M. Park, S. Kim, E. Yang, S. J. Hwang, and Y. Yang, “Learning to propagate labels: Transductive propagation network for few-shot learning,” in International Conference on Learning Representations, 2019. ↩︎
H. Huang, J. Zhang, J. Zhang, Q. Wu, and C. Xu, “PTN: A Poisson transfer network for semi-supervised few-shot learning,” in AAAI Conference on Artificial Intelligence, 2021. ↩︎
J. Calder, B. Cook, M. Thorpe, and D. Slepcev, “Poisson learning: Graph based semisupervised learning at very low label rates,” in International Conference on Machine Learning, pp. 1306–1316, 2020. ↩︎
H.-Y. Tseng, H.-Y. Lee, J.-B. Huang, and M.-H. Yang, “Cross-domain few-shot classification via learned feature-wise transformation,” in International Conference on Learning Representations, 2020. ↩︎ ↩︎
W.-H. Li, X. Liu, and H. Bilen, “Universal representation learning from multiple domains for few-shot classification,” in IEEE/CVF International Conference on Computer Vision, pp. 9526–9535, 2021. ↩︎
W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo, “Revisiting local descriptor based image-to-class measure for few-shot learning,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019. ↩︎ ↩︎
Z. Wu, Y. Li, L. Guo, and K. Jia, “PARN: Position-aware relation networks for few-shot learning,” in IEEE International Conference on Computer Vision, 2019. ↩︎ ↩︎
W. Xu, Y. Xu, H. Wang, and Z. Tu, “Attentional constellation nets for few-shot learning,” in International Conference on Learning Representations, 2021. ↩︎
F. Wu, J. S. Smith, W. Lu, C. Pang, and B. Zhang, “Attentive prototype few-shot learning with capsule network-based embedding,” in European Conference on Computer Vision, pp. 237–253, Springer, 2020. ↩︎ ↩︎ ↩︎
H. Huang, J. Zhang, J. Zhang, J. Xu, and Q. Wu, “Low-rank pairwise alignment bilinear network for few-shot fine-grained image classification,” IEEE Transactions on Multimedia, 2020. ↩︎ ↩︎
C. Dong, W. Li, J. Huo, Z. Gu, and Y. Gao, “Learning task-aware local representations for few-shot learning,” in International Joint Conference on Artificial Intelligence, 2020. ↩︎ ↩︎
K. Cao, M. Brbic, and J. Leskovec, “Concept learners for few-shot learning,” in International Conference on Learning Representations, 2021. ↩︎
W. Jiang, K. Huang, J. Geng, and X. Deng, “Multi-scale metric learning for few-shot learning,” IEEE Transactions on Circuits and Systems for Video Technology, 2020. ↩︎
X.-S. Wei, P. Wang, L. Liu, C. Shen, and J. Wu, “Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples,” IEEE Transactions on Image Processing, vol. 28, no. 12, pp. 6116–6125, 2019. ↩︎
H. Huang, J. Zhang, L. Yu, J. Zhang, Q. Wu, and C. Xu, “TOAN: Target-oriented alignment network for fine-grained image categorization with few labeled samples,” IEEE Transactions on Circuits and Systems for Video Technology, 2021. ↩︎
J. Wu, T. Zhang, Y. Zhang, and F. Wu, “Task-aware part mining network for few-shot learning,” in IEEE/CVF International Conference on Computer Vision, pp. 8433–8442, 2021. ↩︎
H. Li, D. Eigen, S. Dodge, M. Zeiler, and X. Wang, “Finding task-relevant features for few-shot learning by category traversal,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–10, 2019. ↩︎
S. W. Yoon, D.-Y. Kim, J. Seo, and J. Moon, “XtarNet: Learning to extract task-adaptive representation for incremental few-shot learning,” in International Conference on Machine Learning, pp. 10852–10860, 2020. ↩︎
S. Rahman, S. Khan, and F. Porikli, “A unified approach for conventional zero-shot, generalized zero-shot, and few-shot learning,” IEEE Transactions on Image Processing, vol. 27, no. 11, pp. 5652–5667, 2018. ↩︎
T. D. Kulkarni, W. F. Whitney, P. Kohli, and J. Tenenbaum, “Deep convolutional inverse graphics network,” in Advances in Neural Information Processing Systems, pp. 2539–2547, 2015. ↩︎
A. J. Ratner, H. Ehrenberg, Z. Hussain, J. Dunnmon, and C. Ré, “Learning to compose domain-specific transformations for data augmentation,” in Advances in Neural Information Processing Systems, pp. 3236–3246, 2017. ↩︎
L. Perez and J. Wang, “The effectiveness of data augmentation in image classification using deep learning,” arXiv preprint arXiv:1712.04621, 2017. ↩︎
A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb, “Learning from simulated and unsupervised images through adversarial training,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 2242–2251, 2017. ↩︎
A. Antoniou, A. Storkey, and H. Edwards, “Data augmentation generative adversarial networks,” International Conference on Learning Representations Workshop, 2018. ↩︎
A. J. Ratner, C. M. De Sa, S. Wu, D. Selsam, and C. Ré, “Data programming: Creating large training sets, quickly,” in Advances in Neural Information Processing Systems, pp. 3567– 3575, 2016. ↩︎
Y.-X. Wang, R. Girshick, M. Hebert, and B. Hariharan, “Low-shot learning from imaginary data,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 7278–7286, 2018. ↩︎
H. Zhang, J. Zhang, and P. Koniusz, “Few-shot learning via saliency-guided hallucination of samples,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 2770–2779, 2019. ↩︎
J. Guan, Z. Lu, T. Xiang, A. Li, A. Zhao, and J.-R. Wen, “Zero and few shot learning with semantic feature synthesis and competitive learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 7, pp. 2510–2523, 2020. ↩︎
S. Gidaris, A. Bursuc, N. Komodakis, P. Perez, and M. Cord, “Boosting few-shot visual learning with self-supervision,” in IEEE International Conference on Computer Vision, 2019. ↩︎
Y. Zhu, W. Min, and S. Jiang, “Attribute-guided feature learning for few-shot image recognition,” IEEE Transactions on Multimedia, vol. 23, pp. 1200–1209, 2020. ↩︎
L. Zhang, S. Wang, X. Chang, J. Liu, Z. Ge, and Q. Zheng, “Auto-FSL: Searching the attribute consistent network for few-shot learning,” IEEE Transactions on Circuits and Systems for Video Technology, 2021. ↩︎
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” inAdvances in Neural Information Processing Systems, pp. 4077–4087, 2017. ↩︎ ↩︎ ↩︎ ↩︎
W. Li, J. Xu, J. Huo, L. Wang, Y. Gao, and J. Luo, “Distribution consistency based covariance metric networks for few-shot learning,” in AAAI Conference on Artificial Intelligence, vol. 33, pp. 8642–8649, 2019. ↩︎
K. Allen, E. Shelhamer, H. Shin, and J. Tenenbaum, “Infinite mixture prototypes for few-shot learning,” in International Conference on Machine Learning, pp. 232–241, 2019. ↩︎
C. Doersch, A. Gupta, and A. Zisserman, “CrossTransformers: spatially-aware few-shot transfer,” in Advances in Neural Information Processing Systems, 2020. ↩︎
J. Lu, S. Jin, J. Liang, and C. Zhang, "Robust few-shot learning for user-provided data,"IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 4, pp. 1433–1447, 2020. ↩︎ ↩︎
C. Ma, Z. Huang, M. Gao, and J. Xu, “Few-shot learning via dirichlet tessellation ensemble,” in International Conference on Learning Representations, 2022. ↩︎
A. Ravichandran, R. Bhotika, and S. Soatto, “Few-shot learning with embedded class models and shot-free meta training,” in IEEE International Conference on Computer Vision, 2019. ↩︎
H. Huang, Z. Wu, W. Li, J. Huo, and Y. Gao, “Local descriptor-based multi-prototype network for few-shot learning,” Pattern Recognition, vol. 116, p. 107935, 2021. ↩︎ ↩︎
D. Das and C. G. Lee, "A two-stage approach to few-shot learning for image recognition,"IEEE Transactions on Image Processing, vol. 29, pp. 3336–3350, 2020. ↩︎
77 ↩︎
A. Li, T. Luo, T. Xiang, W. Huang, and L. Wang, “Few-shot learning with global class representations,” in IEEE International Conference on Computer Vision, 2019. ↩︎
R. Chen, T. Chen, X. Hui, H. Wu, G. Li, and L. Lin, “Knowledge graph transfer network for few-shot recognition,” in AAAI Conference on Artificial Intelligence, vol. 34, pp. 10575– 10582, 2020. ↩︎
T. Chen, L. Lin, X. Hui, R. Chen, and H. Wu, “Knowledge-guided multi-label few-shot learning for general image recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020. ↩︎
X. Luo, L. Wei, L. Wen, J. Yang, L. Xie, Z. Xu, and Q. Tian, “Rectifying the shortcut learning of background for few-shot learning,” in Advances in Neural Information Processing Systems, pp. 13073–13085, 2021. ↩︎
Y. Zhou, Y. Guo, S. Hao, and R. Hong, “Hierarchical prototype refinement with progressive inter-categorical discrimination maximization for few-shot learning,” IEEE Transactions on Image Processing, 2022. ↩︎
Z. Sun, J. Wu, X. Li, W. Yang, and J.-H. Xue, “Amortized bayesian prototype metalearning: A new probabilistic meta-learning approach to few-shot image classification,” inInternational Conference on Artificial Intelligence and Statistics, pp. 1414–1422, 2021. ↩︎
J. Zhang, C. Zhao, B. Ni, M. Xu, and X. Yang, “Variational few-shot learning,” in IEEE International Conference on Computer Vision, 2019. ↩︎
C. Simon, P. Koniusz, R. Nock, and M. Harandi, “Adaptive subspaces for few-shot learning,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4136–4145, 2020. ↩︎
B. Liu, Y. Cao, Y. Lin, Q. Li, Z. Zhang, M. Long, and H. Hu, “Negative margin matters: Understanding margin in few-shot classification,” in European Conference on Computer Vision, pp. 438–455, Springer, 2020. ↩︎
W. Zhu, W. Li, H. Liao, and J. Luo, “Temperature network for few-shot learning with distribution-aware large-margin metric,” Pattern Recognition, vol. 112, p. 107797, 2021. ↩︎
J. Chen, L.-M. Zhan, X.-M. Wu, and F.-l. Chung, “Variational metric scaling for metricbased meta-learning,” in AAAI Conference on Artificial Intelligence, vol. 34, pp. 3478–3485, 2020. ↩︎
L. Qiao, Y. Shi, J. Li, Y. Wang, T. Huang, and Y. Tian, “Transductive episodic-wise adaptive metric for few-shot learning,” in IEEE International Conference on Computer Vision, 2019. ↩︎
V. N. Nguyen, S. Løkse, K. Wickstrøm, M. Kampffmeyer, D. Roverso, and R. Jenssen, “SEN: A novel feature normalization dissimilarity measure for prototypical few-shot learning networks,” in European Conference on Computer Vision, vol. 12368, pp. 118–134, Springer, 2020. ↩︎
Y. Zheng, D. K. Pal, and M. Savvides, “Ring loss: Convex feature normalization for face recognition,” in IEEE conference on computer vision and pattern recognition, pp. 5089–5097, 2018. ↩︎
C. Zhang, Y. Cai, G. Lin, and C. Shen, “DeepEMD: Few-shot image classification with differentiable earth mover’s distance and structured classifiers,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12203–12213, 2020. ↩︎
J. Xie, F. Long, J. Lv, Q. Wang, and P. Li, “Joint distribution matters: Deep brownian distance covariance for few-shot classification,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. ↩︎
X. Li, J. Wu, Z. Sun, Z. Ma, J. Cao, and J.-H. Xue, “BSNet: Bi-similarity network for few-shot fine-grained image classification,” IEEE Transactions on Image Processing, vol. 30, pp. 1318–1331, 2020. ↩︎
F. Hao, F. He, J. Cheng, L. Wang, J. Cao, and D. Tao, “Collect and select: Semantic alignment metric learning for few-shot learning,” in IEEE International Conference on Computer Vision, 2019. ↩︎
V. Garcia and J. Bruna, “Few-shot learning with graph neural networks,” International Conference on Learning Representations, 2018. ↩︎
J. Kim, T. Kim, S. Kim, and C. D. Yoo, “Edge-labeling graph neural network for few-shot learning,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 11–20, 2019. ↩︎
Y. Ma, S. Bai, S. An, W. Liu, A. Liu, X. Zhen, and X. Liu, “Transductive relationpropagation network for few-shot learning,” in International Joint Conference on Artificial Intelligence, pp. 804–810, 2020. ↩︎
C. Chen, K. Li, W. Wei, J. T. Zhou, and Z. Zeng, “Hierarchical graph neural networks for few-shot learning,” IEEE Transactions on Circuits and Systems for Video Technology, 2021. ↩︎
L. Yang, L. Li, Z. Zhang, X. Zhou, E. Zhou, and Y. Liu, “DPGN: Distribution propagation graph network for few-shot learning,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13390–13399, 2020. ↩︎
N. Fei, Z. Lu, T. Xiang, and S. Huang, “MELR: Meta-learning via modeling episode-level relationships for few-shot learning,” in International Conference on Learning Representations, 2021. ↩︎
M. McCloskey and N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem,” in Psychology of Learning and Motivation, vol. 24, pp. 109–165, Elsevier, 1989. ↩︎
S. Gidaris and N. Komodakis, “Dynamic few-shot visual learning without forgetting,” inIEEE Conference on Computer Vision and Pattern Recognition, pp. 4367–4375, 2018. ↩︎
E. T. Oldewage, J. F. Bronskill, and R. E. Turner, “Attacking few-shot classifiers with adversarial support poisoning,” in ICML Workshop on Adversarial Machine Learning, 2021. ↩︎
M. Goldblum, L. Fowl, and T. Goldstein, “Adversarially robust few-shot learning: A meta-learning approach,” Advances in Neural Information Processing Systems, vol. 33, pp. 17886–17895, 2020. ↩︎
E. Bennequin, V. Bouvier, M. Tami, A. Toubhans, and C. Hudelot, “Bridging few-shot learning and adaptation: new challenges of support-query shift,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 554–569, Springer, 2021. ↩︎
M. Agarwal, M. Yurochkin, and Y. Sun, "On sensitivity of meta-learning to support data,"Advances in Neural Information Processing Systems, vol. 34, pp. 20447–20460, 2021. ↩︎
Y. Guo, N. C. Codella, L. Karlinsky, J. V. Codella, J. R. Smith, K. Saenko, T. Rosing, and R. Feris, “A broader study of cross-domain few-shot learning,” in European Conference on Computer Vision, pp. 124–141, Springer, 2020. ↩︎

















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









