








利用伪标签优化的半监督少样本学习
引用:Li, Pan, et al. “Semi-supervised few-shot learning with pseudo label refinement.” 2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2021.
论文地址:下载地址
Abstract
少样本分类旨在通过极少量的带标签样本识别新的类别。尽管已经取得了许多重要成果,但由于带标签样本的稀缺性,少样本分类仍然具有挑战性。最近的研究倾向于利用未标记数据通过伪标签扩展训练集,但这种策略通常会带来显著的标签噪声。在本研究中,我们通过迭代伪标签优化引入了一种新的半监督少样本学习基线方法,以减少噪声。随后,我们研究了标签噪声传播问题,并通过一个去噪网络改进了基线方法,该网络通过混合模型学习干净和带噪声伪标记样本的分布。这有助于估计伪标记样本的置信值,并选择噪声较少的可靠样本,用于迭代优化少样本分类器。在 miniImagenet、tieredImagenet 和 CIFAR-FS 三个广泛使用的基准数据集上的大量实验表明,我们提出的方法优于当前最先进的方法。
1. Introduction
少样本分类是一项具有挑战性的任务,旨在通过有限的带标签数据识别新类别。传统的深度神经网络在此任务中往往表现不佳,因为它们包含大量的模型参数,容易对稀少的带标签数据发生过拟合。为了解决这一问题,近年来提出了许多少样本学习的解决方案1,2,3,4。一种通用的流程是使用基础类别中充足的带标签数据训练一个识别模型,然后为新类别微调一个新的分类器。然而,由于新类别中带标签样本的稀缺性,传统的少样本分类方法通常表现较差。
为了缓解这一缺陷,一些研究5,6,7通过利用来自新类别的额外未标记数据,采用半监督少样本学习(SS-FSL)来解决该问题。当前的 SS-FSL 方法主要遵循元学习流程,并使用伪标签估计(例如带掩码的软 k-means 聚类5、标签传播6和使用硬伪标签与软伪标签的自训练方法7)来同时利用稀少的带标签数据和大量的未标记数据来学习一个元学习器。然而,这些方法需要在元训练和元测试阶段模拟 SS-FSL 任务,导致复杂的 episodic 学习过程和较差的扩展能力。另一方面,最近的一项研究8采用了迁移学习流程,通过预训练一个特征提取器,为新类别打印分类器权重,并使用现成的半监督学习方法更新模型。然而,未经仔细调整的这种简单结合现成半监督学习方法的方式,通常会导致 SS-FSL 的次优性能。
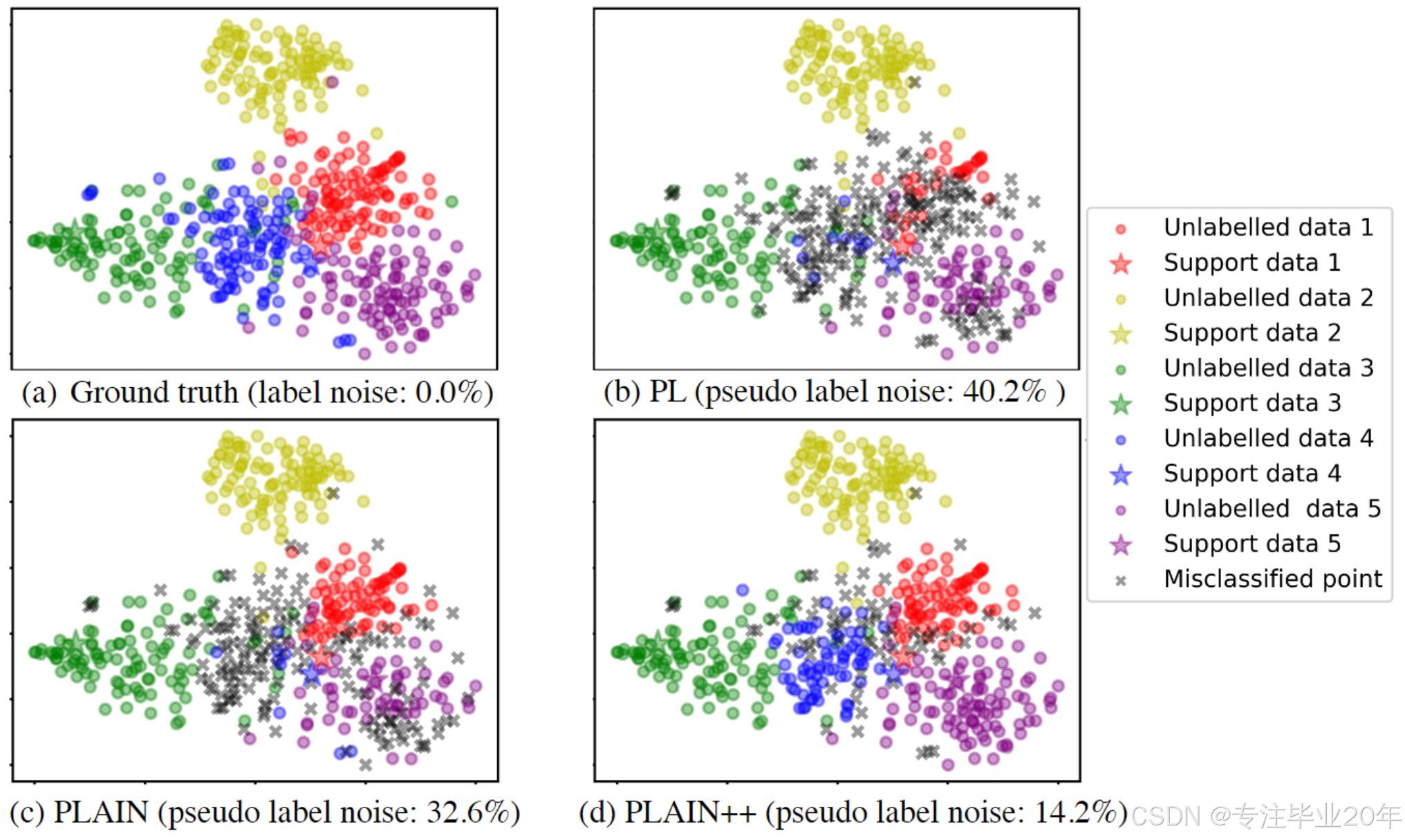
图 1:在 miniImagenet 数据集上每类包含 100 个未标记数据的 5 类 1-shot 任务中嵌入的可视化结果。(a) 显示了带有真实标签的支持样本和未标记数据的分布;(b)、©、(d) 分别显示了伪标签方法(PL)、PLAIN 和 PLAIN++ 估计的伪标签对应的支持样本和未标记数据的分布。圆点、星形和黑色交叉分别表示未标记数据、支持样本和被误分类的数据点。
在本研究中,我们通过引入伪标签优化(PLAIN),对迁移学习框架进行改进,提出了一种简单的半监督少样本学习(SS-FSL)基线方法。伪标签方法9是为新类别中的未标记样本分配标签的关键技术之一。常见的做法是使用初始分类器为未标记数据估计伪标签,然后使用伪标记数据更新分类器。然而,这种方法通常会受到伪标签噪声的影响,从而导致预测不准确(例如图 1 (b) 中的蓝色点)。因此,在本研究中,我们开发了一种名为 PLAIN 的方法,通过将迭代自训练与可靠伪标签选择相结合,集成到迁移学习框架中以用于 SS-FSL。如图 2 (a)、(b) 和 (c-1) 所示,我们首先预训练一个特征提取器,然后使用新类别的分类权重微调一个基于余弦相似性的识别模型,最后迭代优化伪标签,从而无需精心采样元任务或采用现成的半监督学习方法即可学习分类器。这个基线方法虽然简单,但可以有效优化可靠的伪标签(例如图 1 © 中的红点和蓝点),从而学习少样本分类器。
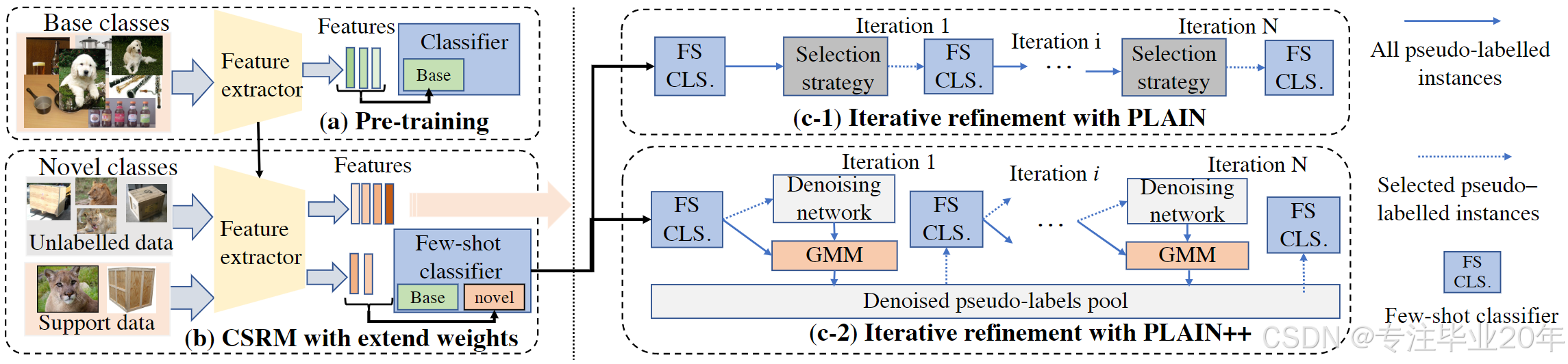
图 2:PLAIN 和 PLAIN++ 用于半监督少样本学习的整体框架。基线方法 PLAIN 包括 (a)、(b) 和 (c-1),而 PLAIN++ 包括 (a)、(b) 和 (c-2)。
由于在 PLAIN 方法中伪标签是通过固定的特征提取器进行迭代更新的,因此由特征提取器偏差产生的伪标签噪声在优化过程中容易被放大,从而导致标签噪声传播问题10。为了解决这一问题,我们对 PLAIN 方法进行了改进,提出了 PLAIN++,通过引入去噪网络和高斯混合模型(GMM)来减少伪标签噪声。去噪网络适应新类别的知识,GMM 用于学习干净和带噪声伪标签的分布,从而获得可靠的伪标记实例。这种改进形成了一种更先进的 SS-FSL 方法——PLAIN++。如图 2 (c-2) 所示,与 PLAIN 方法相比,PLAIN++ 需要使用高置信度的伪标记示例训练一个去噪网络。我们利用该去噪网络通过 GMM 评估伪标签的置信值,GMM 对干净和带噪声的伪标记示例分布进行建模,以便我们可以选择 η \eta η 比例的伪标签用于更新少样本分类器。这个过程以交替的方式执行,直到达到预定义的迭代次数。因此,PLAIN++ 可以通过每次迭代步骤中的伪标签选择来估计伪标记示例的置信值并缓解伪标签噪声(例如图 1 (d))。
我们的主要贡献如下:
- 我们为 SS-FSL 提出了一种简单但有效的基线方法(PLAIN)。虽然该方法借鉴了现有方法(如伪标签)的基本思想,但它是一种新的公式化方法,在与现有复杂 SS-FSL 方法的竞争中表现出了优异的性能。
- 我们讨论了标签噪声传播问题,并进一步提出了 PLAIN++,结合去噪网络和混合模型以缓解伪标签噪声。
- 我们在三个广泛使用的基准数据集(miniImagenet11、tieredImagenet5 和 CIFAR-FS12)上进行了大量实验,结果表明 PLAIN 和 PLAIN++ 优于最先进的方法。
2. Related Work
少样本分类可以分为基于度量的方法和基于梯度的方法。基于度量的方法11,1专注于学习一个通用的特征空间,使同一类别的数据可以通过距离度量轻松地与不同类别的数据区分开,而基于梯度的方法3,13则使用一个元学习器作为优化器,用于学习模型的元参数。然而,这些方法通常由于带标签数据的有限性导致固有缺陷,从而表现较差。
半监督少样本学习(SS-FSL)大多遵循元学习流程,并通过为未标记数据估计伪标签来更新分类器。Ren 等人5通过采用软 k-means 方法为未标记数据估计伪标签,提出了将 ProtoNet1 扩展到 SS-FSL 的方法。Li 等人7提出了一种自我训练学习(LST)方法,用于为未标记数据元学习一个软权重网络。然而,这些方法在动态识别新类别时表现出较差的扩展能力,并且需要 episodic 训练。最近,TransMatch8 使用一个迁移学习框架用于 SS-FSL,通过学习一个基于余弦相似性的识别模型而无需 episodic 训练,但它未考虑未标记数据的伪标签噪声,导致次优性能。
半监督学习旨在利用未标记数据来学习一个更好地拟合潜在数据分布的模型。传统的解决方案(例如一致性正则化14和熵最小化15)在半监督学习中表现出了有希望的性能,但由于带标签样本的稀缺性,它们无法直接用于 SS-FSL。
3. Methodlogy
问题定义:假设我们有一个大规模数据集
D
b
D_b
Db,其中包含来自基础类别
C
b
C_b
Cb 的充足带标签样本,以及一个小规模数据集
D
n
D_n
Dn,其中仅包含来自新类别
C
n
C_n
Cn 的少量带标签样本和一些未标记样本,其中
C
n
C_n
Cn 与
C
b
C_b
Cb 互不相交。SS-FSL 的目标是利用
D
n
D_n
Dn 中的少量带标签样本和未标记样本,以及
D
b
D_b
Db 中的带标签样本作为辅助数据,学习一个能够识别新类别的分类器。
通常,从
D
n
D_n
Dn 中采样一个包含
N
N
N 个类别的小型支持集,每个类别有
K
K
K 个带标签样本,这样形成一个
N
N
N 类
K
K
K-shot 问题。此外,从
N
N
N 个新类别或干扰类别中为每个类别额外采样
R
R
R 张未标记图像。
3.1 PLAIN: A Baseline Method for SS-FSL
如图 2 所示,PLAIN 方法包含三个步骤:(a) 预训练,(b) 基于余弦相似性的扩展权重识别模型,以及 (c-1) 迭代伪标签优化。
3.1.1预训练
我们学习一个基于余弦相似性的识别模型(Cosine-Similarity based Recognition Model,CSRM) f ( θ , W ) f(\theta, W) f(θ,W),其中包括一个特征提取器 Φ θ \Phi_\theta Φθ 和一个带分类权重 W = W b W = W_b W=Wb 的分类器 σ ( Φ θ ∣ W ) \sigma(\Phi_\theta | W) σ(Φθ∣W)。该模型在一个基础训练数据集 D b = ⋃ b = 1 C b { x b , i } i = 1 N b D_b = \bigcup_{b=1}^{C_b} \{x_{b,i}\}_{i=1}^{N_b} Db=⋃b=1Cb{xb,i}i=1Nb 上进行训练,该数据集包含 C b C_b Cb 个类别。我们通过优化交叉熵损失来训练该模型,其公式如下:
1 C b ∑ b = 1 C b 1 N b ∑ i = 1 N b loss ( x b , i , b ) , \frac{1}{C_b} \sum_{b=1}^{C_b} \frac{1}{N_b} \sum_{i=1}^{N_b} \text{loss}(x_{b,i}, b), Cb1b=1∑CbNb1i=1∑Nbloss(xb,i,b),
其中 loss ( x b , i , b ) = − log ( p b ) \text{loss}(x_{b,i}, b) = -\log(p_b) loss(xb,i,b)=−log(pb), p b p_b pb 是 x b , i x_{b,i} xb,i 属于第 b b b 类的概率。然后,我们在验证集上评估模型,以获得具有最佳泛化性能的特征提取器 Φ θ ∗ \Phi_\theta^* Φθ∗。
3.1.2 基于余弦相似性的扩展权重识别模型
在预训练后,我们得到一个 CSRM f ( θ ∗ , W b ) f(\theta^*, W_b) f(θ∗,Wb),并将其分类权重扩展为 W e = W b ∪ W n W_e = W_b \cup W_n We=Wb∪Wn,其中 W n W_n Wn 是新类别的分类权重。具体来说,假设每个类别有 N N N 个支持样本 x i sup x_i^\text{sup} xisup( i = 1 , . . . , N i = 1, ..., N i=1,...,N),我们通过对该类别的训练样本特征向量求平均来推断该类别的分类权重:
W sup = 1 N ∑ i = 1 N Φ θ ∗ ( x i sup ) . W^\text{sup} = \frac{1}{N} \sum_{i=1}^N \Phi_\theta^*(x_i^\text{sup}). Wsup=N1i=1∑NΦθ∗(xisup).
然后,我们将权重向量归一化为单位长度:
W n = W sup ∥ W sup ∥ . W_n = \frac{W^\text{sup}}{\|W^\text{sup}\|}. Wn=∥Wsup∥Wsup.
最后,我们将基础类别和新类别的权重拼接得到分类权重 W e = W b ∪ W n W_e = W_b \cup W_n We=Wb∪Wn,从而构建一个扩展的 CSRM f ( θ ∗ , W e ) f(\theta^*, W_e) f(θ∗,We),用于识别基础类别和新类别。在本研究中,我们使用 CSRM f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 作为少样本分类器来识别新类别。
3.1.3迭代伪标签优化
在完成前两个步骤后,我们通过迭代自训练的伪标签优化来学习一个包含未标记数据的分类器。具体来说,我们使用少样本分类器 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 基于概率为来自 C n C_n Cn 的未标记数据估计伪标签,然后选择具有高预测置信度的伪标签来微调 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 的分类权重 W n W_n Wn。微调方法是通过对支持样本和选中的伪标签实例的特征嵌入求平均实现的。如图 2(c-1) 所示,这一过程通过迭代执行,以缓解标签噪声并逐步提高分类器性能。我们在补充材料中的算法 1 中总结了 PLAIN 的训练过程。代码将在以下链接提供: https://github.com/panli93/SSFSL_PLAIN。
3.2. PLAIN++ for Resolving Label Nosie Propagation
3.2.1 标签噪声传播
在迭代优化过程中,一旦某个样本被分配了错误的标签(例如图 1 中的蓝色点),它可能会在后续迭代中由于错误预测被赋予更高的置信值。这会导致标签噪声传播问题(也称为确认偏差问题16)。为了解决这个问题,我们设计了一种去噪网络,以从新类别中学习可靠的知识,减少由基础类别带来的偏差,并使用高斯混合模型(GMM)对伪标签的损失分布建模,惩罚噪声伪标签,从而减少累积的标签噪声。
3.2.2 去噪网络
如图 2 (a)、(b) 和 (c2) 所示,PLAIN++ 包含三个步骤,其中前两个步骤与 PLAIN 相同,而第三个步骤通过伪标签去噪过程进行了改进。伪标签优化的迭代流程如图 3 所示。通过少样本分类器 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 分配伪标签 L pl L_\text{pl} Lpl,我们选择可靠的伪标记实例 D pl select D_\text{pl}^\text{select} Dplselect 和支持数据 D sup. D_\text{sup.} Dsup. 来训练去噪网络。一般来说,我们从 D unl. D_\text{unl.} Dunl. 中每类选择 ξ \xi ξ 百分比的高置信伪标记实例作为 D pl select D_\text{pl}^\text{select} Dplselect,并对这些实例和支持数据应用两种不同的随机数据增强方法,即弱增强(随机裁剪和随机翻转)和强增强(使用 RandAugment15 的三个不同增强项,幅度为 10),生成增强图像 X w X_\text{w} Xw 和 X r X_\text{r} Xr。由于高置信伪标签通常包含较少的噪声,随机增强数据则包含实例的潜在变换,因此可以用于学习新类别的更丰富的数据分布。
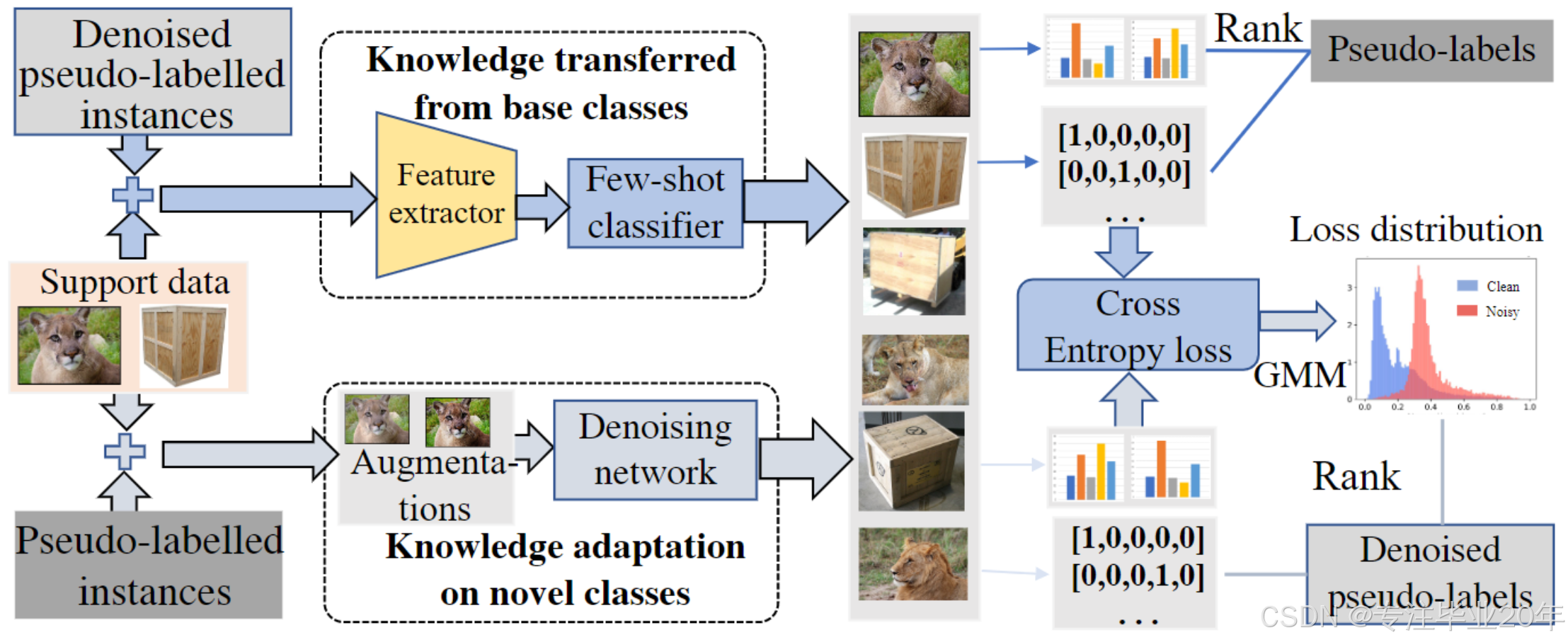
图 3:所提出的 PLAIN++ 中带有伪标签去噪的迭代伪标签优化流程。
然后,为了用这些数据训练去噪网络,我们使用分类的交叉熵损失 L CE L_\text{CE} LCE 并采用蒸馏损失 L KD L_\text{KD} LKD17,18 来学习软数据分布,这有助于提高去噪网络的泛化能力,从而缓解伪标签噪声。其中, L KD L_\text{KD} LKD 的公式为:
L KD = L KL ( p w ∥ p r ) + L KL ( p r ∥ p w ) , L_\text{KD} = L_\text{KL}(p_\text{w} \| p_\text{r}) + L_\text{KL}(p_\text{r} \| p_\text{w}), LKD=LKL(pw∥pr)+LKL(pr∥pw),
其中 L KL ( x ∥ y ) L_\text{KL}(x \| y) LKL(x∥y) 是基于 Kullback-Leibler(KL)散度的损失度量。
3.2.3 使用 GMM 去噪伪标签
在网络训练过程中,带噪标签通常比干净标签需要更长时间学习,因此带噪伪标签样本在早期阶段会产生更高的损失。这为我们提供了一个机会,通过它们的损失分布区分干净样本和带噪样本19。为此,我们使用一个双分量 GMM( J = 2 , l ∼ N ( μ j , Σ j ) J=2, l \sim N(\mu_j, \Sigma_j) J=2,l∼N(μj,Σj))对损失分布进行建模。对于每个伪标记样本,混合模型根据其损失估计伪标签的置信值,并惩罚不符合干净标签分布的样本,从而避免在下一次迭代中将高置信分配给错误预测的实例。
具体来说,使用训练好的去噪网络,我们首先获取未标记数据 D unl. ∪ D sup. D_\text{unl.} \cup D_\text{sup.} Dunl.∪Dsup. 的去噪伪标签 L dpl L_\text{dpl} Ldpl,并计算去噪网络预测与原始伪标签 L pl L_\text{pl} Lpl 之间的损失 l l l。然后,我们使用期望最大化算法20对 l l l 拟合 GMM,并根据后验概率 p ( g ∥ l i ) p(g \| l_i) p(g∥li)(其中 g g g 是具有较小损失的高斯分量)计算每个样本的置信值 w i w_i wi。对于给定样本,我们通过少样本分类器 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 和去噪网络获取两种伪标签,即 L pl L_\text{pl} Lpl 和 L dpl L_\text{dpl} Ldpl。由 GMM 产生的置信值用于从 L pl L_\text{pl} Lpl 或 L dpl L_\text{dpl} Ldpl 中选择可靠的伪标签。由于 L dpl L_\text{dpl} Ldpl 是由完全在新类别上训练的去噪网络分配的,因此我们采用选定的 L dpl L_\text{dpl} Ldpl 来优化少样本分类器 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn),从而防止 L pl L_\text{pl} Lpl 的标签噪声在迭代优化中被放大。
此外,为了进一步提高选定去噪伪标签的质量,我们对实例采用弱增强和强增强(RandAugment21),从而为每个样本生成两个具有置信值的预测,即 p w p_\text{w} pw(置信值 w w w_\text{w} ww)和 p r p_\text{r} pr(置信值 w r w_\text{r} wr)。然后,我们通过对齐两个预测更新去噪伪标签池,并选择 η \eta η 百分比的高置信样本 D dpl select D_\text{dpl}^\text{select} Ddplselect。接下来,少样本分类器 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 的分类权重 W n W_n Wn 通过 D dpl select D_\text{dpl}^\text{select} Ddplselect 和 D sup. D_\text{sup.} Dsup. 的特征嵌入平均值进行更新。
通过迭代地使用伪标签样本( D dpl select D_\text{dpl}^\text{select} Ddplselect 和 D pl select D_\text{pl}^\text{select} Dplselect)优化 f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn) 和去噪网络,因自训练引起的标签噪声传播问题被逐步减轻。我们在补充材料中的算法 2 中总结了 PLAIN++ 的训练过程。
4. EXPERIMENTS
数据集
- miniImagenet11 是 ILSVRC12 数据集22的一个子集,包含 100 个类别,每个类别有 600 张图像。按照文献13,我们使用 64 个类别作为基础集,16 个类别作为验证集,20 个类别作为新类别集。
- tieredImageNet5 是 ILSVRC12 的一个较大子集,包含 608 个类别,这些类别被语义分组为 34 个更广泛的类别。按照文献5,我们使用 20 个类别作为基础集,6 个类别作为验证集,8 个类别作为新类别集。
- CIFAR-FS12 是 CIFAR100 的一个子集,包含 100 个类别,每个类别有 600 张低分辨率图像。按照文献12,我们使用 64 个类别作为基础集,16 个类别作为验证集,20 个类别作为新类别集。
通过迭代地使用伪标签样本( D dpl select D_\text{dpl}^\text{select} Ddplselect 和 D pl select D_\text{pl}^\text{select} Dplselect)优化 $f(\theta^*, 对于每个数据集,我们将所有图像的大小调整为 84 × 84 84 \times 84 84×84。我们使用基础集对特征提取器进行预训练,并在验证集上选择性能最佳的特征提取器。我们从新类别集中随机选择 600 个任务,每个任务包含来自 N N N 个新类别的 K K K 个支持样本(带标签数据)、15 个查询样本以及每类 R R R 个未标记数据。
实现细节
通过迭代地使用伪标签样本( D dpl select D_\text{dpl}^\text{select} Ddplselect 和 D pl select D_\text{pl}^\text{select} Dplselect)优化 $f(\theta^*, 按照文献23,我们使用 ResNet-12 作为特征提取器的骨干网络。ResNet-12 包含 4 个残差块,每个块有三个 3 × 3 3 \times 3 3×3 的卷积层,每个卷积层后接一个 BatchNorm 层和一个 LeakyReLU 激活函数(斜率为 0.1)。我们在每个块中使用了 dropout,并在每个残差块末尾应用了一个 2 × 2 2 \times 2 2×2 的最大池化层。优化器使用带有 0.9 动量的 SGD 和 L2 权重衰减( 5 × 1 0 − 4 5 \times 10^{-4} 5×10−4)。初始学习率设置为 0.1,对于 CIFAR-FS 数据集训练 30 个 epoch,对于其他数据集训练 60 个 epoch。每个 epoch 中随机选择 8000 个 batch,每个 batch 的大小为 32。
通过迭代地使用伪标签样本( D dpl select D_\text{dpl}^\text{select} Ddplselect 和 D pl select D_\text{pl}^\text{select} Dplselect)优化 $f(\theta^*, 对于去噪网络,我们采用包含 4 个块的 ResNet-10 作为骨干网络。ResNet-10 的每个块由三个 3 × 3 3 \times 3 3×3 的卷积层组成,每个卷积层后接一个 BatchNorm 层。优化器同样使用带有 0.9 动量的 SGD 和权重衰减( 5 × 1 0 − 4 5 \times 10^{-4} 5×10−4)。批量大小和学习率分别设置为 64 和 5 × 1 0 − 3 5 \times 10^{-3} 5×10−3。当 η > 50 % \eta > 50\% η>50% 时,迭代次数 M M M 设置为 15,否则设置为 10。去噪网络的训练 epoch 数 T e T_e Te 在第一次迭代中设置为 12,其余迭代中设置为 6。
通过迭代地使用伪标签样本( D dpl select D_\text{dpl}^\text{select} Ddplselect 和 D pl select D_\text{pl}^\text{select} Dplselect)优化 $f(\theta^*, 对于每个 SS-FSL 任务,我们为每类使用 R unl. = 100 R_\text{unl.} = 100 Runl.=100 个未标记样本,并最多选择 η ⋅ R unl. \eta \cdot R_\text{unl.} η⋅Runl. 个伪标记实例更新 CSRM f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn)( η = { 50 % , 100 % } \eta = \{50\%, 100\%\} η={50%,100%})。在训练去噪网络时,对于 1-shot 和 5-shot 设置,我们分别将 ξ \xi ξ 设置为 60% 和 80%。
4.1. Comparison with State-of-the-Art Methods
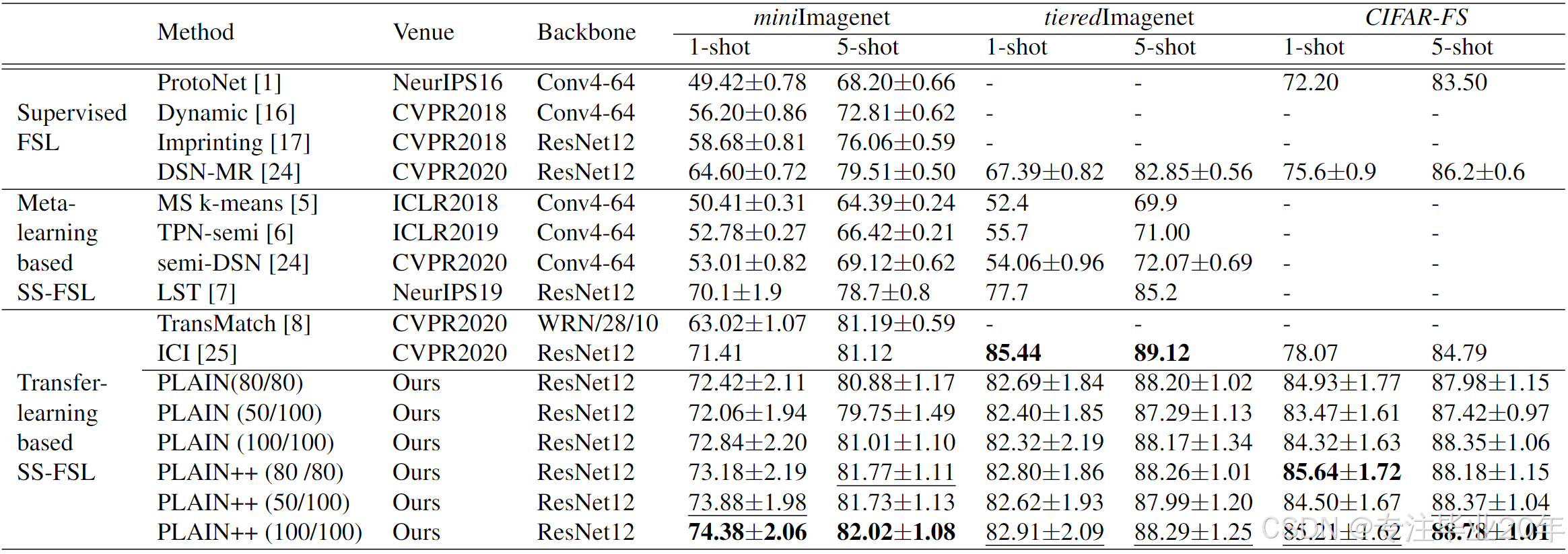
在表 1 中,我们将提出的方法与 10 种最先进的方法进行了比较。从表 1 可以看出:
- 与最先进的方法相比,尽管 PLAIN 方法简单,但其性能具有竞争力,这表明该基线方法的有效性;
- 通过伪标签去噪来解决标签噪声传播问题,PLAIN++ 在 miniImagenet 和 CIFAR-FS 数据集上进一步提升了 PLAIN 的性能,并且在 tieredImagenet 数据集上与 ICI 方法表现相当;
- 随着伪标记实例数量的增加,PLAIN 和 PLAIN++ 的性能逐渐提高。
表 1:在 miniImageNet、tieredImageNet 和 CIFAR-FS 数据集上 5 类 1/5-shot 任务的平均分类准确率(95% 置信区间)。(a/b) 表示在 5 类 1/5-shot 学习中,每类从
b
=
R
unl
b = R_\text{unl}
b=Runl 个未标记数据中最多选择
a
=
η
⋅
R
unl
a = \eta \cdot R_\text{unl}
a=η⋅Runl 个伪标记实例。加粗 和 下划线 分别表示最佳和次优结果。
4.2. Ablation Study
4.2.1 组件分析
为了验证 PLAIN 和 PLAIN++ 中各个组件的有效性,我们分别使用 CSRM ( f ( θ ∗ , W n ) f(\theta^*, W_n) f(θ∗,Wn))、带伪标签的 CSRM (CSRM+PL)、完整的 PLAIN 模型、结合 GMM 的 PLAIN(部分 PLAIN++ 模型)、结合弱增强和强增强 (WSA) 图像与 GMM 的 PLAIN(完整的 PLAIN++ 模型)进行了实验。如表 2 所示,与仅使用或不使用伪标签的 CSRM 相比,PLAIN 的伪标签优化在 1-shot 设置下实现了显著的性能提升。虽然在 5-shot 学习中,迭代伪标签优化的改进不太明显,但这可以归因于标签噪声传播问题。该问题可以通过所提出的 GMM 和 WSA 方法解决。如表 2 所示,在 1/5-shot 设置下,PLAIN+GMM 的性能显著优于 CSRM+PL 和 PLAIN,而 PLAIN+GMM+WSA 进一步提升了性能。
表 2:在 miniImageNet 数据集上使用 ResNet12 的组件有效性分析(5 类 1/5-shot 平均准确率 (%),95% 置信区间)。我们设置
R
unl.
=
100
R_\text{unl.} = 100
Runl.=100,
η
=
50
%
\eta = 50\%
η=50%。

4.2.2 不同骨干网络和伪标记样本比例的影响
在图 4 中,我们报告了使用 ResNet12 和 Conv4-12824 作为骨干网络时,CSRM+PL、PLAIN 和 PLAIN++ 在 miniImagenet 上不同 η \eta η 值下的结果。我们设置 η = { 0 , 10 , 20 , 30 , 40 , 50 , 80 , 100 } % \eta = \{0, 10, 20, 30, 40, 50, 80, 100\}\% η={0,10,20,30,40,50,80,100}%,并且 R unl. = 100 R_\text{unl.}=100 Runl.=100。从结果可以看出,随着使用更深的骨干网络,所有对比方法的性能都有所提升,其中 PLAIN++ 的性能最佳,PLAIN 的性能次之。此外,在不同的 η \eta η 值下,PLAIN++ 仍然整体表现最好。
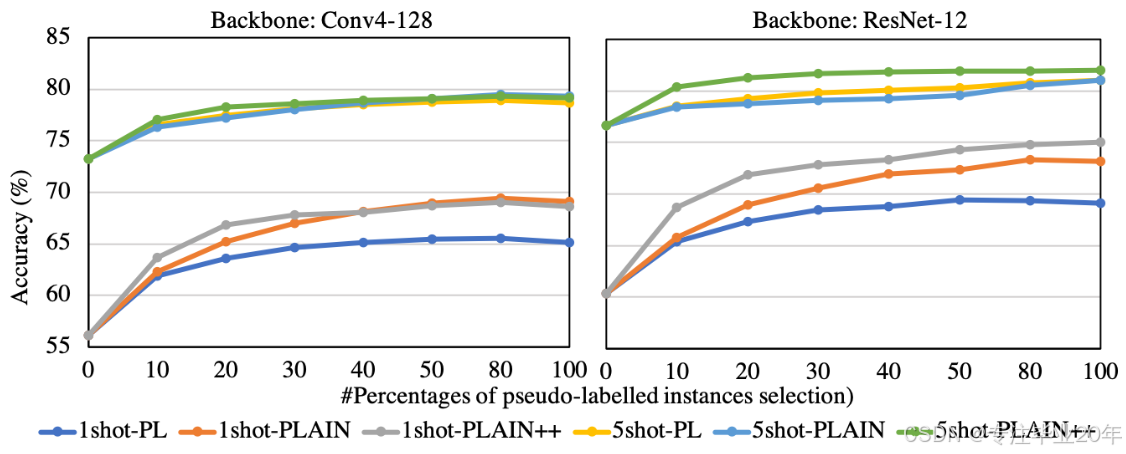
图 4:在 miniImageNet 数据集上,CSRM+伪标签(PL)、PLAIN 和 PLAIN++ 在不同样本比例
η
\eta
η 和不同骨干网络(Conv4-128 和 ResNet-12)下的比较。
4.2.3 每类未标记样本数量的影响
如表 3 所示,当每类有更多未标记数据可用时,所有对比方法的性能都得到了提升,其中 PLAIN++ 实现了最佳性能,这表明了我们方法的可扩展性。
表 3:在 miniImageNet 数据集上使用 ResNet12 的不同方法在
R
unl.
=
{
0
,
15
,
50
,
100
,
150
,
200
}
R_\text{unl.} = \{0, 15, 50, 100, 150, 200\}
Runl.={0,15,50,100,150,200} 下的分类准确率。我们在所有设置中均将
η
=
50
%
\eta = 50\%
η=50%。

4.2.4 抵抗干扰类别的鲁棒性
按照文献7, 8,我们将原始未标记数据与从测试集其他类别中随机选择的相同数量的每类样本(作为干扰项)混合,并在包含 1/2/3 个干扰类别的 SS-FSL 设置下对我们的方法进行了进一步评估。如图 5 所示,当包含干扰项时,所有对比方法的准确率都有所下降,但 PLAIN++ 和 PLAIN 仍然在与其他方法的比较中表现出较强的竞争力。

图 5:在 miniImageNet 数据集上,包含不同干扰项的 5 类 1-shot 任务的准确率(使用 ResNet12)。在 CSRM+PL、PLAIN 和 PLAIN++ 中,我们设置
η
=
20
%
\eta = 20\%
η=20%,
R
unl.
=
100
R_\text{unl.} = 100
Runl.=100。
5. CONCLUSIONS
在本研究中,我们提出了一种简单但有效的基线方法(伪标签优化,PLAIN)用于半监督少样本学习(SS-FSL),通过迭代优化伪标签来为新类别学习一个新的分类器。随后,我们讨论了标签噪声传播问题,并通过改进 PLAIN 提出了 PLAIN++,结合去噪网络生成去噪伪标签,以及混合模型学习干净和带噪伪标签样本的分布,以选择噪声较少的可靠伪标签实例。我们在 miniImagenet、tieredImagenet 和 CIFAR-FS 数据集上进行了大量实验。实验结果表明,PLAIN 和 PLAIN++ 相较于最先进的 SS-FSL 方法具有更高的有效性。
Jake Snell, Kevin Swersky, and Richard Zemel, “Prototypical networks for few-shot learning,” in NeurIPS, 2017. ↩︎ ↩︎ ↩︎
Chenrui Zhang and Yuxin Peng, “Visual data synthesis via gan for zero-shot video classification,” in IJCAI, 2018. ↩︎
Chelsea Finn, Pieter Abbeel, and Sergey Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in ICML, 2017. ↩︎ ↩︎
Andrei A Rusu, Dushyant Rao, Jakub Sygnowski, Oriol Vinyals, Razvan Pascanu, Simon Osindero, and Raia Hadsell, “Meta-learning with latent embedding optimization,” in ICLR, 2019. ↩︎
Mengye Ren, Eleni Triantafillou, Sachin Ravi, Jake Snell, Kevin Swersky, Joshua B Tenenbaum, Hugo Larochelle, and Richard S Zemel, “Meta-learning for semi-supervised few-shot classification,” in ICLR, 2018. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sung Ju Hwang, and Yi Yang, “Learning to propagate labels: Transductive propagation network for few-shot learning,” in ICLR, 2019. ↩︎ ↩︎
Xinzhe Li, Qianru Sun, Yaoyao Liu, Qin Zhou, Shibao Zheng, Tat-Seng Chua, and Bernt Schiele, “Learning to self-train for semi-supervised few-shot classification,” in NeurIPS, 2019. ↩︎ ↩︎ ↩︎ ↩︎
Zhongjie Yu, Lin Chen, Zhongwei Cheng, and Jiebo Luo, “Transmatch: A transfer-learning scheme for semi-supervised few-shot learning,” in CVPR, 2020. ↩︎ ↩︎ ↩︎
Dong-Hyun Lee, “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks,” in ICML Workshops, 2013, vol. 3. ↩︎
Antti Tarvainen and Harri Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” in NeurIPS, 2017. ↩︎
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al., “Matching networks for one shot learning,” in NeurIPS, 2016. ↩︎ ↩︎ ↩︎
Luca Bertinetto, Joao F Henriques, Philip Torr, and Andrea Vedaldi, “Meta-learning with differentiable closedform solvers,” in ICLR, 2019. ↩︎ ↩︎ ↩︎
Sachin Ravi and Hugo Larochelle, “Optimization as a model for few-shot learning,” in ICLR, 2016. ↩︎ ↩︎
Samuli Laine and Timo Aila, “Temporal ensembling for semi-supervised learning,” in ICLR, 2017. ↩︎
David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel, “Mixmatch: A holistic approach to semi-supervised learning,” in NeurIPS. 2019. ↩︎ ↩︎
Eric Arazo, Diego Ortego, Paul Albert, Noel E O’Connor, and Kevin McGuinness, “Pseudo-labeling and confirmation bias in deep semi-supervised learning,” in IJCNN, 2020. ↩︎
Xu Lan, Xiatian Zhu, and Shaogang Gong, “Knowledge distillation by on-the-fly native ensemble,” in NeurIPS. 2018. ↩︎
Guile Wu and Shaogang Gong, “Peer collaborative learning for online knowledge distillation,” in AAAI, 2021. ↩︎
Junnan Li, Richard Socher, and Steven CH Hoi, “Dividemix: Learning with noisy labels as semi-supervised learning,” in ICLR, 2020. ↩︎
Haim Permuter, Joseph Francos, and Ian Jermyn, “A study of gaussian mixture models of color and texture features for image classification and segmentation,” PR, vol. 39, no. 4, 2006. ↩︎
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le, “Randaugment: Practical automated data augmentation with a reduced search space,” in CVPR Workshops, 2020. ↩︎
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al., “Imagenet large scale visual recognition challenge,” IJCV, vol. 115, no. 3, 2015. ↩︎
Yikai Wang, Chengming Xu, Chen Liu, Li Zhang, and Yanwei Fu, “Instance credibility inference for few-shot learning,” in CVPR, 2020. ↩︎
Spyros Gidaris and Nikos Komodakis, “Dynamic fewshot visual learning without forgetting,” in CVPR, 2018. ↩︎

















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









