







人工神经网络笔记(一)后向传播、随机最优化、设定超参数
- Background propagation
- Stochastic optimization
- Hyper-parameter tuning
1、一个简单的神经网络
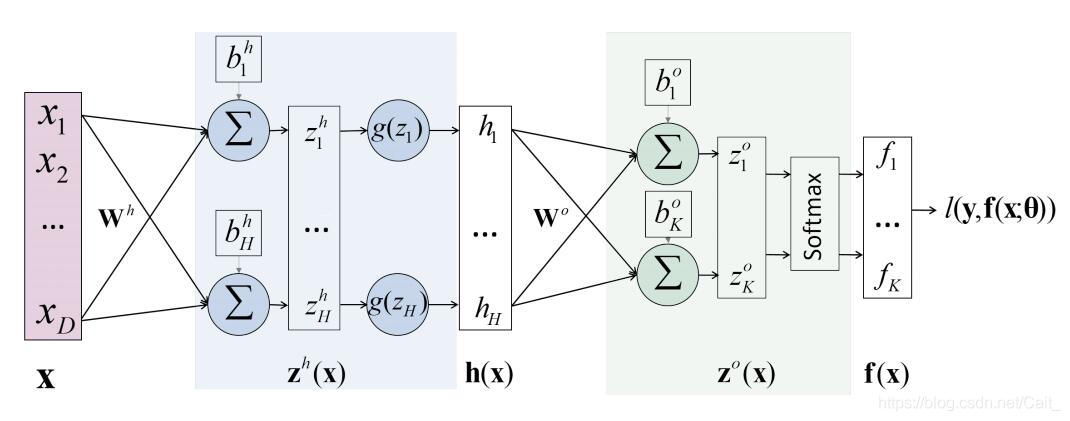
其中, l ( y , f ( x : θ ) l(y,f(x: \theta) l(y,f(x:θ) 代表损失函数,表示真实值和预测值之间的差距,模型参数 θ = [ W h , W o , b h , b o ] \theta =[W^h,W^o,b^h,b^o] θ=[Wh,Wo,bh,bo] ;
该神经网络的目标是找到使得 l l l最小的 θ \theta θ
后向传播(Background propagation):利用链式法则计算梯度,再更新模型参数;
例,对于 w 1 w_1 w1
δ l δ w 1 = δ l δ h 1 δ h 1 δ w 1 = ( δ l δ z 1 δ z 1 δ h 1 + δ l δ z 2 δ z 2 δ h 1 ) ∗ ( δ h 1 δ u 1 δ u 1 δ w 1 ) \frac{\delta l}{\delta w_1} = \frac{\delta l}{\delta h_1} \frac{\delta h_1}{\delta w_1} = (\frac{\delta l}{\delta z_1}\frac{\delta z_1}{\delta h_1}+\frac{\delta l}{\delta z_2}\frac{\delta z_2}{\delta h_1} )*(\frac{\delta h_1}{\delta u_1}\frac{\delta u_1}{\delta w_1}) δw1δl=δh1δlδw1δh1=(δz1δlδh1δz1+δz2δlδh1δz2)∗(δu1δh1δw1δu1)
w 1 = w 1 − l r ∗ δ l δ w 1 w_1 = w_1 - lr*\frac{\delta l}{\delta w_1} w1=w1−lr∗
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









