









 文章详细介绍了如何使用PyTorch构建一个多层感知机,包括数据加载、网络结构、ReLU激活函数、损失函数和训练过程,以Fashion-MNIST数据集为例进行演示。
文章详细介绍了如何使用PyTorch构建一个多层感知机,包括数据加载、网络结构、ReLU激活函数、损失函数和训练过程,以Fashion-MNIST数据集为例进行演示。
一、什么是多层感知机
多层感知机由感知机推广而来,最主要的特点是有多个神经元层,因此也叫深度神经网络(DNN: Deep Neural Networks)。
二、如何实现多层感知机
1、导入所需库并加载fashion_mnist数据集
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torch import nn
from torchvision import transforms
from d2l import torch as d2l
import warnings
warnings.filterwarnings("ignore")
# 用SVG清晰度高
d2l.use_svg_display()
from IPython import display
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)# 用于集中图像处理方法
mnist_train = torchvision.datasets.FashionMNIST(
root="data/", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="data/", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
train_iter, test_iter = load_data_fashion_mnist(256)2、设置变量以及要更新的参数
Fashion-MNIST中的每个图像由 28×28=784个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。
通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]torch.nn.Parameter()将一个不可训练的tensor转换成可以训练的类型parameter,并将这个parameter绑定到这个module里面。即在定义网络时这个tensor就是一个可以训练的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化
3、定义rulu激活函数
def relu(X):
a = torch.zeros_like(X) #用于生成和X相同shape的全零tensor
return torch.max(X, a)4、搭建模型

def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法如上图所示乘法
return (H@W2 + b2)5、定义损失函数
这里我们使用API内置的CrossEntropyLoss即包含了softmax也包含了交叉熵损失
loss = nn.CrossEntropyLoss(reduction='none')6、进行训练
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
7、模型测试
d2l.predict_ch3(net, test_iter)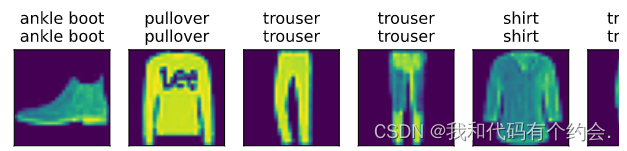
8、简单实现
使用Pytorch内置的高级API搭建网络架构
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torch import nn
from torchvision import transforms
from d2l import torch as d2l
import warnings
warnings.filterwarnings("ignore")
# 用SVG清晰度高
d2l.use_svg_display()
from IPython import display
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="data/", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="data/", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
train_iter, test_iter = load_data_fashion_mnist(256)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
lr, num_epochs = 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)这里面使用Sequential搭建了网络架构,其中先将图片进行展平(nn.Flatten)然后传入线形层,在经过relu激活函数,最后使用Linear进行输出。
使用init_weights进行初始化线行层参数,使其符合正态分布(如果全0模型训练不动)
最后进行训练就可。















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









