







 超级会员免费看
超级会员免费看
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/129062590
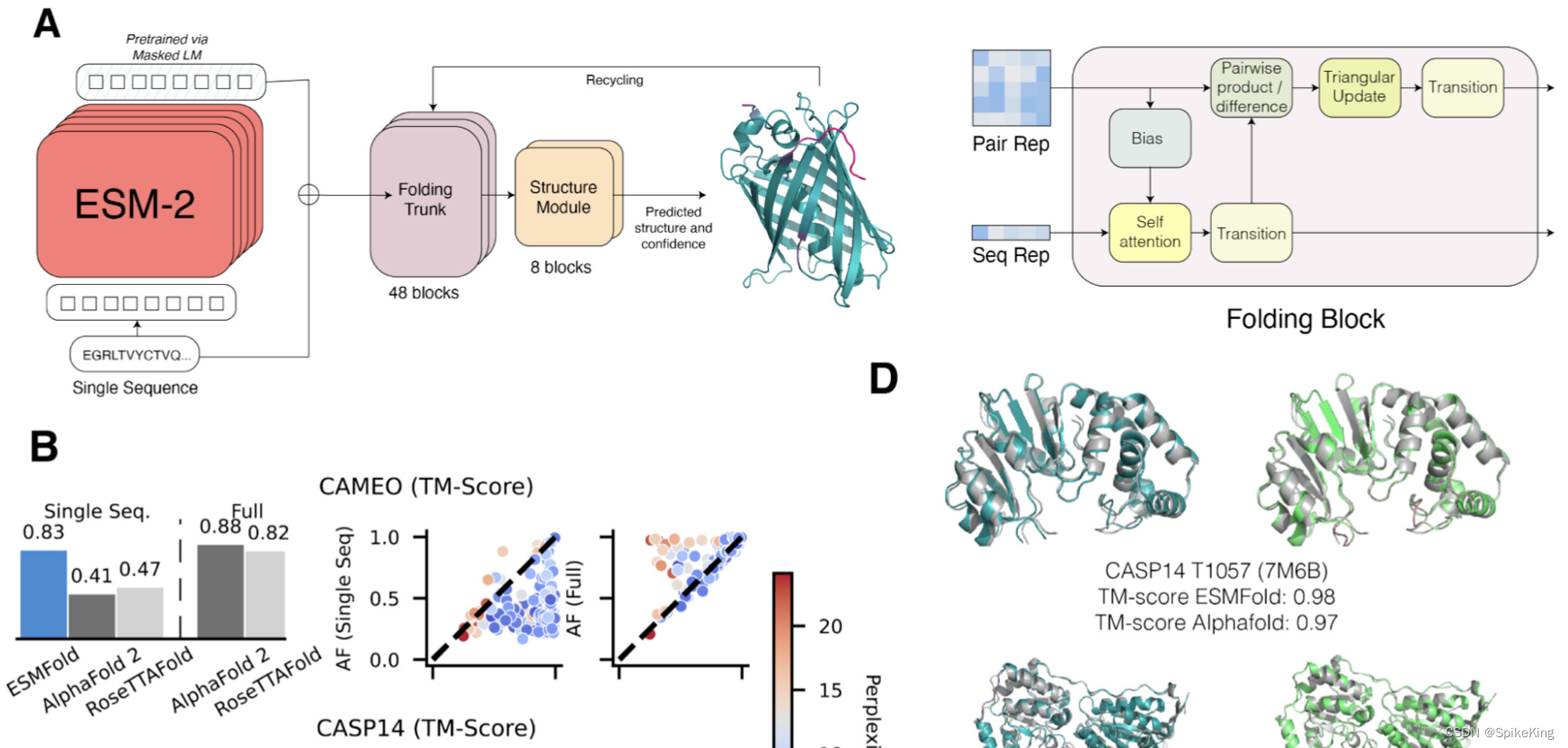
ESMFold 是一种基于预训练语言模型的蛋白质结构预测方法,主要思想是利用大规模预训练蛋白质语言模型来替代 MSA(多序列比对),并且语言模型的规模与结构预测效果具有明显的正相关。ESMFold 的流程分为两个部分:序列预训练和结构预测。
- 序列预训练部分:使用了一个 15 亿参数的 Transformer 模型,叫做 ESM-2,来学习蛋白质序列自身的表征。ESM-2 采用随机 Mask 掉残基来预测被mask残基类型的训练方式,类似于 BERT。ESM-2 还对位置编码做了修改,可以支持更长的氨基酸序列编码。
- 结构预测部分:将预训练好的语言模型 ESM-2 的蛋白质序列 Embedding 和 Attention Map 接入与 48 层 Folding Trunk 和 8 层 Structure Module,来预测蛋白质全原子的结构。Folding Trunk 是退化版的 Evoformer,因为只有单序列,所以 Axis Attention 机制就退化成了普通的 Self-Attention,而节点与边 Embbe

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 5119
5119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











