







 超级会员免费看
超级会员免费看
 本文介绍了大语言模型的分布式训练,包括并行策略(数据并行、模型并行、混合并行)、集群架构(参数服务器和去中心化架构)以及DeepSpeed库的优化技术,如ZeRO内存管理,旨在提高训练效率和资源利用率。
本文介绍了大语言模型的分布式训练,包括并行策略(数据并行、模型并行、混合并行)、集群架构(参数服务器和去中心化架构)以及DeepSpeed库的优化技术,如ZeRO内存管理,旨在提高训练效率和资源利用率。
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/136924304
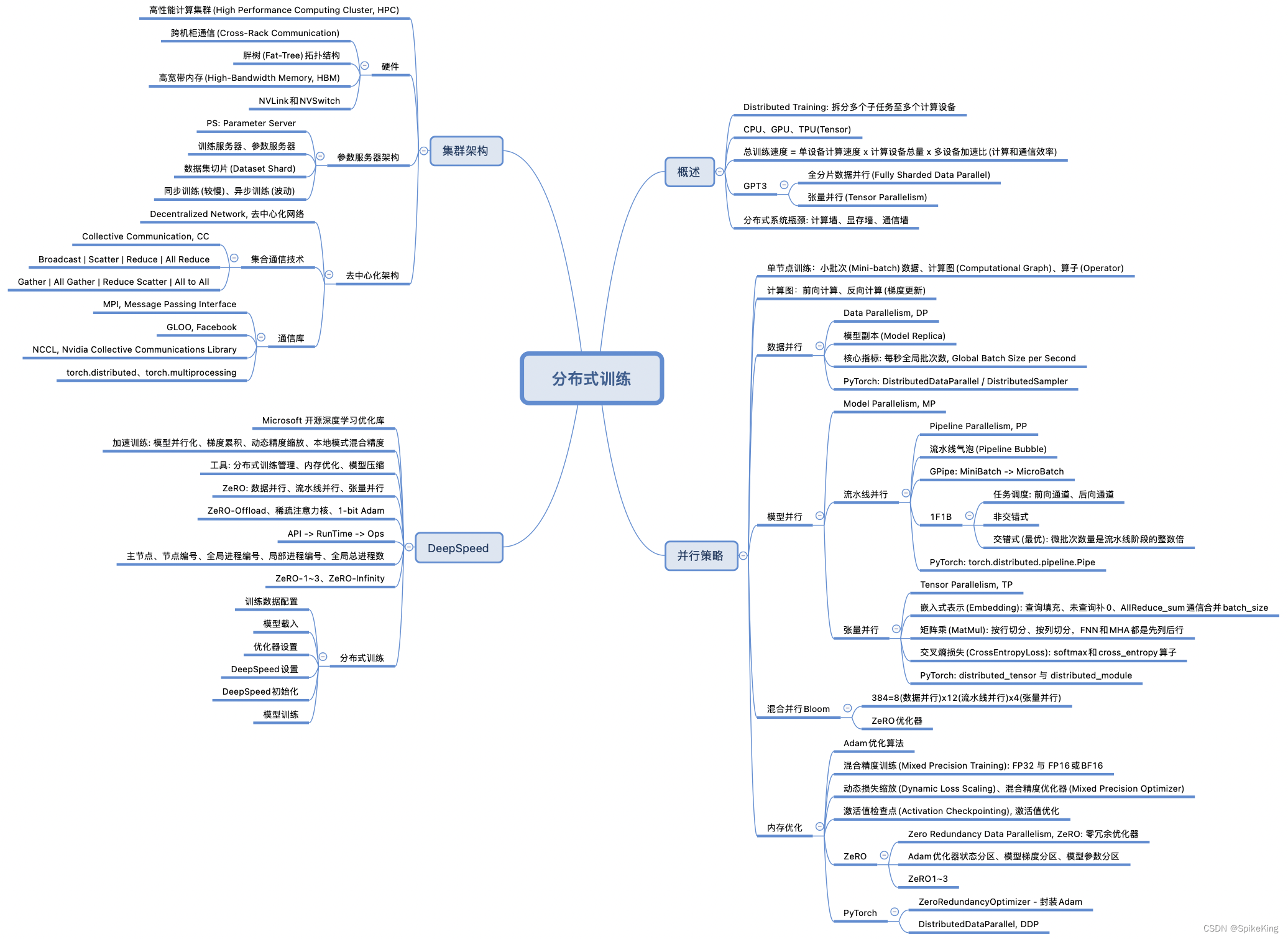
大语言模型的分布式训练是一个复杂的过程,涉及到将大规模的计算任务分散到多个计算节点上。这样做的目的是为了处理巨大的模型和数据集,同时,提高训练效率和缩短训练时间。
- 模型并行:这是分布式训练中的一个重要概念,涉及到将模型的不同部分放置在不同的计算节点上。例如,一个大型的Transformer模型可能会被分割成多个小块,每个小块在不同的GPU上进行计算。
- 数据并行:在数据并行中,每个计算节点都有模型的一个副本,并且每个节点都在模型的不同部分上工作,但是都在处理不同的数据子集。这样可以在多个节点上同时进行模型训练,从而提高效率。
- 通信优化

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











