







信息增益生成决策树 (ID3算法)
实现原理

先计算类标签的香农熵info(D),再计算某个属性的各属性值的香农熵乘以该属性值在其中的比例的和infoA(D),最后相减得出该属性的信息增益,ID3训练出的决策树就是依据信息增益的大小构建的。
实现代码
def chooseBestFeatureToSplit(dataSet): # 选择信息增益最大的特征
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subdataSet = splitdataSet(dataSet, i, value)
prob = len(subdataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subdataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
运行结果
训练出的决策树

运行输出部分截图

- ID3算法是一种贪心算法,以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例
- 算法主要的运行思路是先根据训练数据训练出一个决策树模型,再使用该决策树模型执行分类,达到预测的功能。在生成树的过程中,每次都先挑选出信息增益最大的属性,再根据训练模型里属性值的种类递归生成下一个叶节点。如此递归,停止的第一个条件是当这个叶节点都属于同一类别时,返回该类标签;第二个条件是使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
- 在分类的过程中,使用index方法查找当前列表中第一个匹配firstStr遍历的元素,然后递归遍历整棵树,比较测试数据中的值与树节点的值,如果达到叶子节点,则返回该叶子节点的类标签。
信息增益率决策树(C4.5)
实现原理
信息增益率和信息增益的算法差别就在于以什么方法来划分标准,信息增益率使用“分裂信息”值将信息增益规范化。
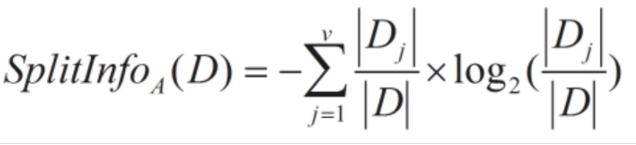
这个值表示通过将训练数据集D划分成对应于属性A测试的v个输出的v个划分产生的信息。

选择具有最大增益率的属性作为划分标准。
实现代码
def chooseBestFeatureToSplit(dataSet): # 选择信息增益最大的特征
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subdataSet = splitdataSet(dataSet, i, value)
prob = len(subdataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subdataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
运行结果
训练出的决策树

运行输出部分截图

- 可以从和信息增益的结果看出,信息增益率所训练出的决策树模型的正确率会较高。
- 如果纯看信息增益,会导致包含类别越多的特征的信息增益越大。为此,引入”分裂信息“值,当类别增多时,splitInfo的值也会增大,以此来制约信息增益大小与特征类别的正相关性质。
基尼指数决策树(CART)
实现原理
基尼指数,又称基尼不纯度,其计算和信息熵的类似,但是计算的速度会超过信息熵,因为没有计算对数的操作。基尼不纯度为这个样本被选中的概率乘以它被分错的概率,可以作为衡量不确定性大小的标准。当一个节点中所有样本都是一个类时,基尼不纯度为0。
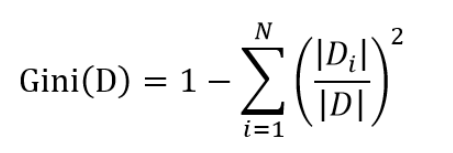
基尼指数的计算为总数1减去 (属性值个数除以属性总数的平方)的和。
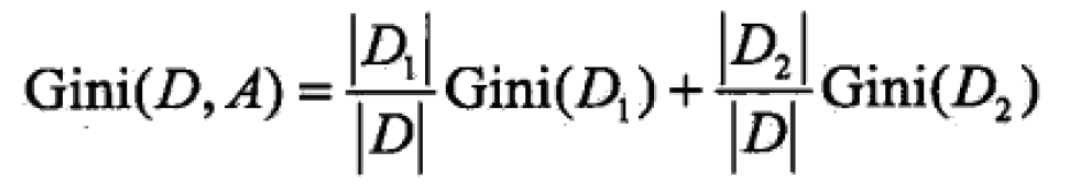
将样本分为D1、D2,即将该属性的一个属性值抽出与其它属性值进行概率分布基尼指数的计算。该基尼指数表示经过特征A的某个取值分割集合D后的不确定性。
实现代码
def countProb(subdataSet): #计算基尼指数
num=len(subdataSet)
featCount=0
feat=subdataSet[0][-1]
for i in subdataSet:
if i[-1]==feat:
featCount+=1
prob=float(featCount)/num
return prob
def GiniIndex(dataSet): # 计算以特征A为分割的最小基尼指数
dataSetLen=len(dataSet)
numFeatures = len(dataSet[0]) - 1
bestGini = 1.0 # 初始基尼指数
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
giniSplit=0.0
for value in uniqueVals:
subdataSet = splitdataSet(dataSet, i, value)
prob=countProb(subdataSet) # 计算p值
featSplit=featList.count(value)
newGiniPercent=float(featSplit)/dataSetLen # 计算该value的占比
giniSplit+=newGiniPercent*2*prob*(1-prob)
if giniSplit < bestGini:
bestGini = giniSplit
bestFeature = i
return bestFeature
运行结果
训练出的决策树

运行输出部分截图

基尼指数越大,集合的不确定性越高,这点和信息熵类似。故此,每次为决策树构建下一节点时总是取基尼指数小的属性。
数据集
数据集来自UCI:http://archive.ics.uci.edu/ml/datasets/Car+Evaluation
全代码
from math import log, pow
import operator
import matplotlib.pyplot as plt
def calcShannonEnt(dataSet): # 计算香农熵
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
def splitdataSet(dataSet, axis, value): # 分类数据
retdataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retdataSet.append(reducedFeatVec)
return retdataSet
def chooseBestFeatureToSplit(dataSet): # 选择信息增益最大的特征
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subdataSet = splitdataSet(dataSet, i, value)
prob = len(subdataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subdataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def GainRatio(dataSet): # 选择信息增益率最大的属性
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestGainRatio = 0.0 # 最佳信息增益率
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
splitInfo = 0.0 # 信息分类率
newEntropy = 0.0
for value in uniqueVals:
subdataSet = splitdataSet(dataSet, i, value)
prob = len(subdataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subdataSet)
splitInfo -= prob * log(prob, 2)
infoGain = baseEntropy - newEntropy
if splitInfo == 0.0: # 预防除数为0的情况
gainratio = 0.0
else:
gainratio = infoGain / splitInfo # 信息增益率计算
if gainratio > bestGainRatio:
bestGainRatio = gainratio
bestFeature = i
return bestFeature
def countProb(subdataSet): #计算基尼指数
num=len(subdataSet)
featCount=0
feat=subdataSet[0][-1]
for i in subdataSet:
if i[-1]==feat:
featCount+=1
prob=float(featCount)/num
return prob
def GiniIndex(dataSet): # 计算以特征A为分割的最小基尼指数
dataSetLen=len(dataSet)
numFeatures = len(dataSet[0]) - 1
bestGini = 1.0 # 初始基尼指数
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
giniSplit=0.0
for value in uniqueVals:
subdataSet = splitdataSet(dataSet, i, value)
prob=countProb(subdataSet) # 计算p值
featSplit=featList.count(value)
newGiniPercent=float(featSplit)/dataSetLen # 计算该value的占比
giniSplit+=newGiniPercent*2*prob*(1-prob)
if giniSplit < bestGini:
bestGini = giniSplit
bestFeature = i
return bestFeature
def majorityCnt(classList): # 多数决决定分类
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels): # 生成字典形式的树
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# bestFeat = chooseBestFeatureToSplit(dataSet) # 信息增益
# bestFeat = GainRatio(dataSet) # 信息增益率
bestFeat = GiniIndex(dataSet) # 基尼指数,无论那种分类标准,都是更改bestFeat
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitdataSet(dataSet, bestFeat, value), subLabels)
return myTree
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
# firstStr = myTree.keys()[0] 2.7的语法,3.6不适用
firstSides = list(myTree.keys())
firstStr = firstSides[0] # 找到输入的第一个元素
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 1
firstSides = list(myTree.keys())
firstStr = firstSides[0] # 找到输入的第一个元素
# firstStr = myTree.keys()[0] #注意这里和机器学习实战中代码不同,这里使用的是Python3,而在Python2中可以写成这种形式
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]) == dict:
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstSides = list(myTree.keys())
firstStr = firstSides[0] # 找到输入的第一个元素
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()
def classify(inputTree, featLabels, testVec): # 决策树执行分类
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
# print(secondDict)
featIndex = featLabels.index(firstStr)
try:
for key in secondDict.keys():
if testVec[featIndex] == key: # 查找测试样本中是否有标签与决策树中的相同
if type(secondDict[key]).__name__ == "dict":
classLabels = classify(secondDict[key], featLabels, testVec)
else:
classLabels = secondDict[key]
return classLabels
except:
if type(secondDict[key]).__name__ == "str":
return secondDict[key]
else:
return classify(secondDict[key], featLabels, testVec) # 如果树并未走到叶子节点就异常终止,则递归调用函数对其子节点进行决策
def file_train(filename): # 取数据集偶数作为训练集
fr = open(filename)
lines = fr.readlines()
# print(lines)
res = []
i = 0
for line in lines:
line = line.strip()
temp = line.split(",")
if i % 2 == 0: # 取总数据集里的偶数
res.append(temp)
i += 1
labels = ["buying", "maint", "doors", "person", "lug_boot", "safety"]
return res, labels
def file_test(filename): # 取数据集的奇数作为测试集
fr = open(filename)
lines = fr.readlines()
# print(lines)
res = []
i = 0
for line in lines:
line = line.strip()
temp = line.split(",")
if i % 2 == 1: # 取总数据集里的奇数
res.append(temp)
i += 1
labels = ["buying", "maint", "doors", "person", "lug_boot", "safety"]
return res, labels
def getAnswer(filename): # 获得真实的答案
fr = open(filename)
lines = fr.readlines()
i = 0
storage = []
for it in lines:
it = it.strip()
temp = it.split(",")
if i % 2 == 1:
storage.append(temp[-1])
i += 1
return storage
def test1():
# 训练模型
dataSet, labels = file_train("sum.txt")
labelsBackup = labels[:]
tree = createTree(dataSet, labels)
createPlot(tree)
dataSet_test, labels_test = file_test("sum.txt")
labels_testBackup = labels_test
j = 0
resTest = []
for item in dataSet_test:
testAns = classify(tree, labels_testBackup, item)
print("第%d次测试" % j, testAns)
resTest.append(testAns)
j += 1
aList = getAnswer("sum.txt")
count = 0
for x in range(len(aList)):
if resTest[x] == aList[x]:
count += 1
print("训练出的模型的正确率:", count / len(aList))
if __name__ == '__main__':
test1()
















 1177
1177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









