







一、背景介绍
Demucs是一个开源的音源分离项目。
Demucs在算法层面前后经历了三次大版本的进化,最原始的V1版本是:编解码+LSTM。具体算法原理图如下所示。该版本在时域进行音源分离。关于阅读笔记请点击这篇文章。
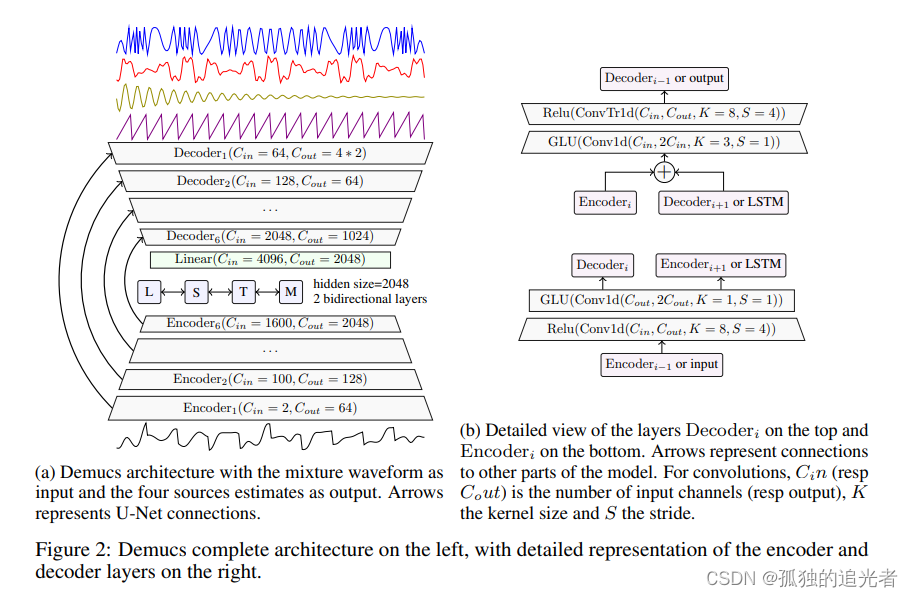
V1版本原理图
V2版本是同时使用时域和频域信息进行音源分离。关于阅读笔记请点击这篇文章。
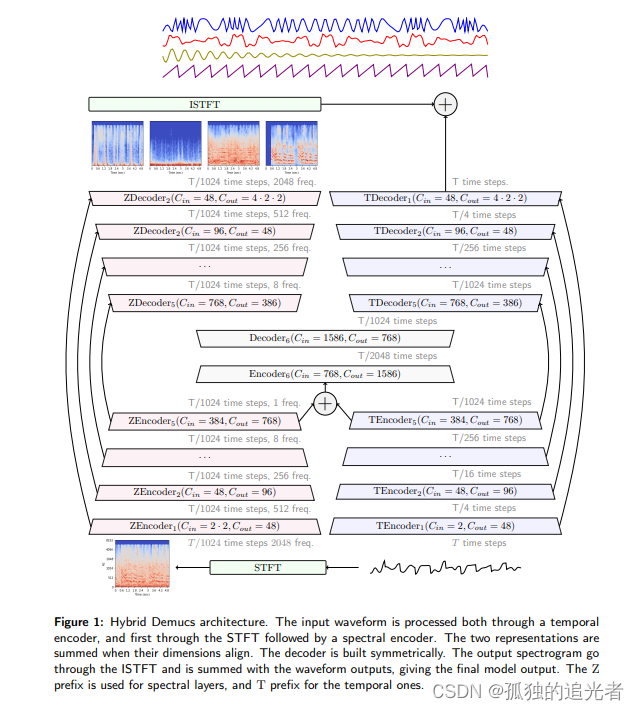
V2版本原理图
V3版本是在V2版本上使用Transformer进一步提升性能。关于阅读笔记请看这篇文章。
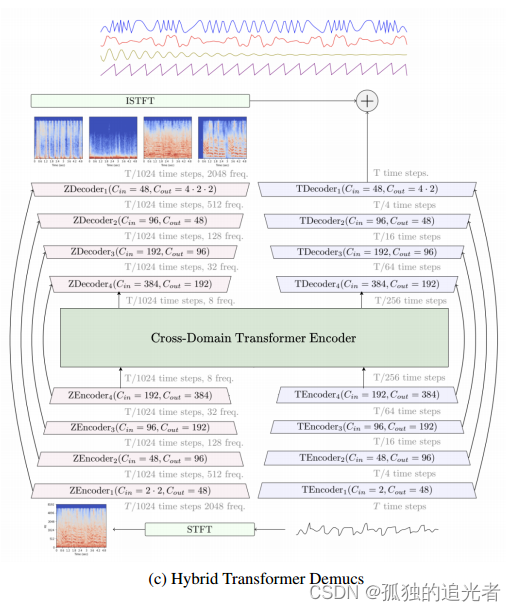
V3版本原理图
二 、准备工作
2.1 安装软件环境
关于驱动、和pytorch的安装可以看这篇文章Pytorch GPU版本安装-CSDN博客
关于pip 安装的包可以参看我安装的版本。
Package Version
------------------------- -----------
aiohttp 3.9.5
aiosignal 1.3.1
alembic 1.13.1
antlr4-python3-runtime 4.8
appdirs 1.4.4
async-timeout 4.0.3
attrs 23.2.0
audioread  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









