







目录
效果演示
【人声分离】田一名其实唱功了得 给我一首歌的时间_哔哩哔哩_bilibili
【人声分离】张靓颖 Dream it Possible 真正的实力_哔哩哔哩_bilibili
周杰伦吐字不清?夜曲去掉伴奏你再听!!_哔哩哔哩_bilibili
爷青回,王心凌《爱你》无伴奏版,女神唱功了得_哔哩哔哩_bilibili
Demucs介绍
Demucs是Facebook开源的声音分离模型,简单易用,结构简单,现在很多应用都以Demucs作为baseline进行优化。
Demucs提供了Demucs和Convs - tasnet作为backbone的实现,在MusDB数据集上进行了预训练。预训练模型可以分离鼓、贝斯、人声和其它,超过了以前基于波形或光谱图的方法。下面是官方给出的对比图,可以看出Demucs is SOTA!所以我们下面主要使用Demucs作为backbone,并简单介绍它的原理。
| Model | Domain | Extra data? | Overall SDR | MOS Quality | MOS Contamination |
|---|---|---|---|---|---|
| Open-Unmix | spectrogram | no | 5.3 | 3.0 | 3.3 |
| D3Net | spectrogram | no | 6.0 | - | - |
| Wave-U-Net | waveform | no | 3.2 | - | - |
| Demucs (this) | waveform | no | 6.3 | 3.2 | 3.3 |
| Conv-Tasnet (this) | waveform | no | 5.7 | 2.9 | 3.4 |
| Demucs (this) | waveform | 150 songs | 6.8 | - | - |
| Conv-Tasnet (this) | waveform | 150 songs | 6.3 | - | - |
| MMDenseLSTM | spectrogram | 804 songs | 6.0 | - | - |
| D3Net | spectrogram | 1.5k songs | 6.7 | - | - |
| Spleeter | spectrogram | 25k songs | 5.9 | - | - |
Demucs的使用
方法一:如果没有python环境,简单,我打了一个包。
链接:https://pan.baidu.com/s/1J-PkILFEoMyC2_S1rBsTMA
提取码:j9it
windows下解压缩,将要分离的文件放在separate/data/input目录,双击separate1.exe,等待。。。结果就会放在separate/data/output/demucs[音频文件名]/目录中,会生成4个文件,其中vocals.wav是人声。

方法二:如果有Python环境,也很简单。先安装依赖,依赖如下:
diffq>=0.1
lameenc>=1.2
julius>=0.2.3
numpy
torch>=1.8.1
torchaudio>=0.8
tqdm
1.安装
pip install demucs2.分离一个音频试试,就用cpu吧,执行下面命令
python -m demucs.separate [PATH_TO_AUDIO_FILE] -o [PATH_TO_OUT_DIR] --name demucs --mp3 -d cpu3.结果存在目录demucs/demucs/separated/demucs/[音频文件名]/,会生成4个文件,其中vocals.wav是人声。
Demucs的基本使用就介绍完成了,是不是很简单,如果只是单纯想使用的小伙伴,到这里就可以结束了,如果想深入研究的小伙伴,咱们继续。
Demucs原理
源码下载:https://github.com/facebookresearch/demucs/
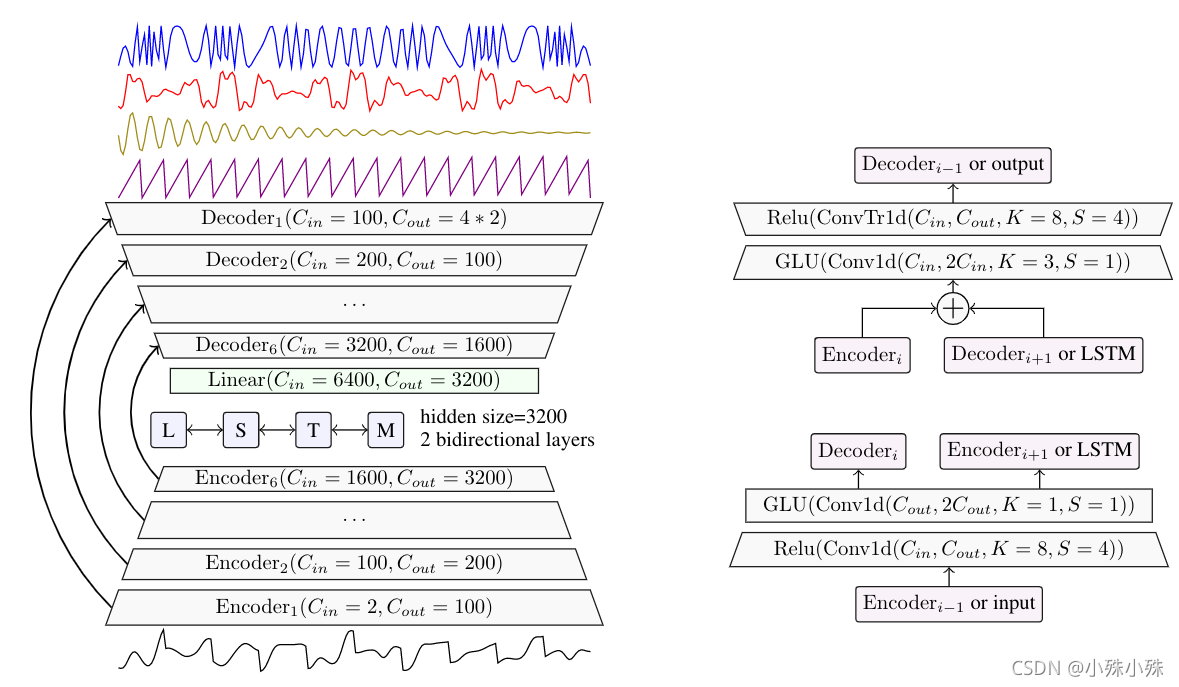
上面是官方提供的模型结构图,如果看不太明白可以看下面我画的那个,Demucs的结构并不复杂,一句话就能概括:Demucs基于U-Net卷积架构,Encoder和Decoder之间加入了BiLSTM。
U-Net卷积架构,灵感来自Wave-U-Net和SING,Decoder的Upsampling使用反卷积,整个模型在channel膨胀的Conv1d之后使用GLU激活函数。
Encoder的Downsampling单元:经过两个Conv1d,第一个使channel扩大到out_c大小、width缩为Input的1/4,后接一个ReLu;第二个使channel扩大到out_c的2倍、width不变,后接一个GLU,GLU使channel数变为1/2(具体为什么下面说),也就是out_c的大小。整个Downsampling的输出是channel根据需要变为out_c、width变为Input的1/4。

Dencoder的Upsampling单元:由一个Conv1d和一个反卷积组成,第一个Conv1d使channel扩大到in_c的2倍、width(因为是一维卷积,没有height)不变,后接一个GLU,GLU使channel数变为1/2,也就是in_c的大小;第二个反卷积使channel扩大到out_c的大小、width扩大到Input是4倍,后接一个ReLu。整个Upsampling的输出是channel根据需要变为out_c、width变为Input的4倍。

GLU(门控线性单元Gated linear units)激活函数
GLU出自2016年的论文Language Modeling with Gated Convolutional Networks,链接:https://arxiv.org/abs/1612.08083v1,论文原意是在处理语言任务时利用多层的CNN结构代替传统的RNN结构,从而解决RNN不能并行的问题,引入了这一激活函数。
表达式为:f(X) = (X * W + b) * O(X * V + c)
Relu激活单元:(X * W + b),加上一个Sigmoid激活单元:O(X * V + c),构成的gate unit,就构成了GLU单元。
在pytorch中有nn.GLU的门控线性激活函数,实现类似下面,可以看到输入被分成两份,一份线性变换一份sigmoid,然后做乘法,所以Input的width减半:
class GLU(nn.Module):
def __init__(self):
super(GLU, self).__init__()
def forward(self, x):
nc = x.size(1)
assert nc % 2 == 0, 'channels dont divide 2!'
nc = int(nc/2)
return x[:, :nc] * torch.sigmoid(x[:, nc:])
对GLU感兴趣的小伙伴可以去看一下论文,下面看一下模型的整体结构,并不复杂,而且保持了U-Net的美感。
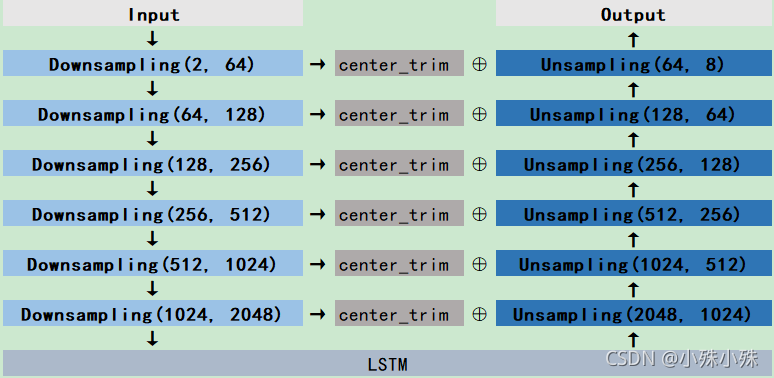
Input是2通道,我参考的预训练模型的depth=6,也就是Downsampling和Upsampling都是6次,每次channel变换2倍,width变化4倍。可以看到,模型就是U-Net中间加了一个LSTM,为了做残差使用了一个center_trim方法对齐size。输出channel=8,因为四种声音,每种声音2通道。
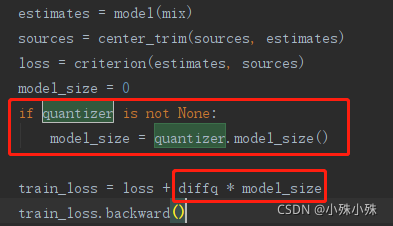
损失函数默认l1Loss,当然也可以选择mse,值得一提的是loss中加了一项:可微量化因子。它是通过在训练过程中在模型参数中加入独立的伪量化噪声,以近似量化算子的效果。其实就是一个惩罚项,主要作用是通过降低参数精度,达到压缩模型的目的,据说DiffQ将一个16层的transforme压缩了8倍,相当于4位精度,而只损失了0.5个点,当然训练时也可以设置diffq=0不使用这个功能。
DiffQ论文链接:https://arxiv.org/abs/2104.09987
Demucs主要结构就介绍到这里,Demucs没有论文只有代码,其实还有很多细节需要自己发现,我也只是一个小学生,欢迎大家批评指正。
关注订阅号了解更多精品文章

交流探讨、商务合作请加微信




















 4941
4941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











