







一、摘要
本文提出了基于Demucs架构的的时域+频域的分离模型。提出的模型在2021年索尼组织的音乐分离挑战中获胜。该架构还包括其他改进,如压缩残差分支、局部注意力或奇异值正则化。
在MusDB HQ数据集上,所有源的信噪比(SDR)平均提高了1.4 dB,这一改进得到了人类主观评估的确认,整体质量评分为2.83分(非混合Demucs为2.36分),污染程度评分为3.04(非混合Demucs为2.37,比赛中排名第二的模型为2.44)。
二、方法
2.1 引言
音乐源分离的研究集中在将鼓、贝斯、人声和其他伴奏分离的监督方式上。2021年索尼组织的音乐分离挑战(MDX)提供了一个新的在线比赛平台,用于评估分离模型在未知测试集上的表现。
2.2 方法
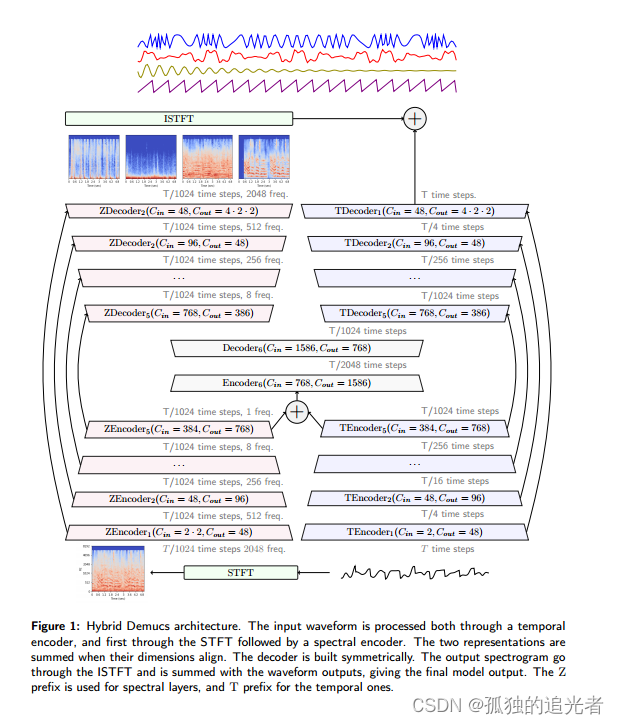
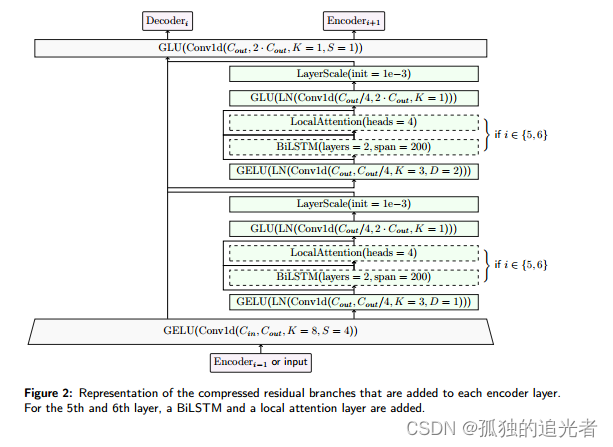
本研究扩展了Demucs架构,以执行混合波形、频谱域源分离。模型包括时间域和频率域的并行分支,并引入了压缩残差分支、局部注意力和奇异值正则化等改进。这些改进在MusD
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3623
3623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









