







有界流处理
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建流式执行环境
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文件
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
//3.转换计算
SingleOutputStreamOperator<Tuple2<String,Long>> wordAndOneTuple=lineDataStreamSource.flatMap((String line, Collector< Tuple2<String,Long>> out) -> {
String[] words=line.split(" ");
for(String word:words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING,Types.LONG));
//4.分组
KeyedStream<Tuple2<String,Long>,String> wordAndOneKeyedStream=wordAndOneTuple.keyBy(data->data.f0);
//5.求和
SingleOutputStreamOperator<Tuple2<String,Long>> sum=wordAndOneKeyedStream.sum(1);
//6.打印
sum.print();
//7.启动执行
env.execute();
}
}
无界流处理
在虚拟机开启一台服务器hadoop102,并且输入 nc -lk 7777
7777是指设定一个端口号
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建流式执行环境
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文本流
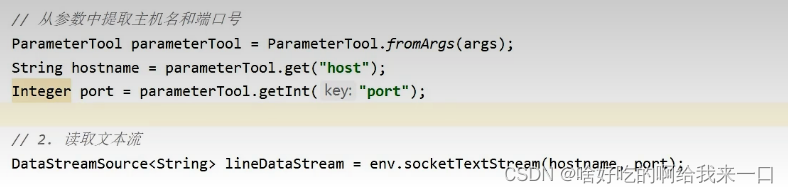
DataStreamSource<String> lineDataStream=env.socketTextStream("hadoop102",7777);
//3.转换计算
SingleOutputStreamOperator<Tuple2<String,Long>> wordAndOneTuple=lineDataStream.flatMap((String line, Collector< Tuple2<String,Long>> out) -> {
String[] words=line.split(" ");
for(String word:words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING,Types.LONG));
//4.分组
KeyedStream<Tuple2<String,Long>,String> wordAndOneKeyedStream=wordAndOneTuple.keyBy(data->data.f0);
//5.求和
SingleOutputStreamOperator<Tuple2<String,Long>> sum=wordAndOneKeyedStream.sum(1);
//6.打印
sum.print();
//7.启动执行
env.execute();
}
}
上面的做法是直接在程序中指出了主机名hostname和端口号port,在实际生产中是从参数或配置文件中读取。修改代码如图
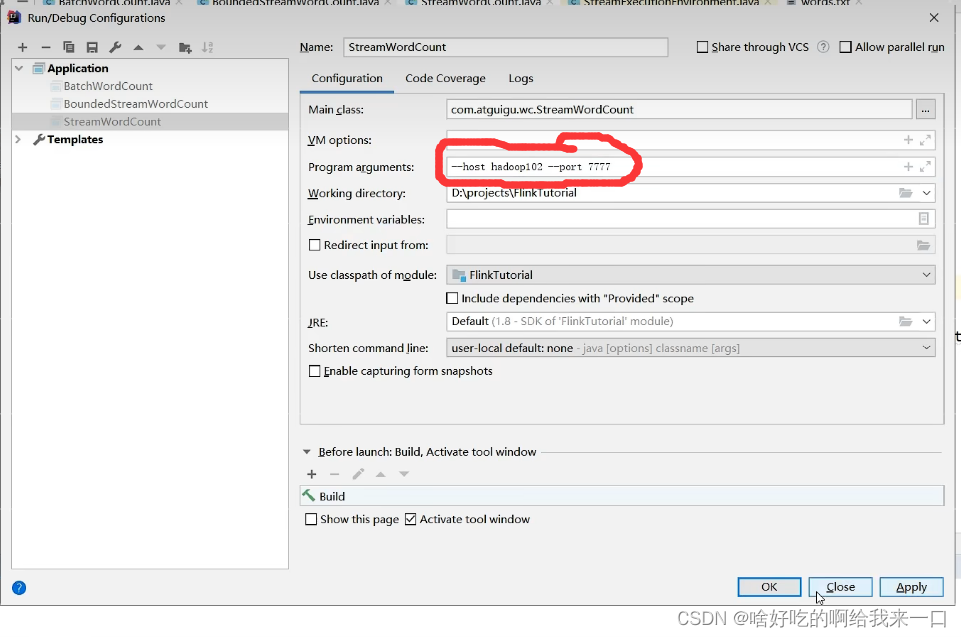
执行前还要修改一下配置信息














 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









