






本篇博客内容源于课程《强化学习的数学原理》 赵世钰老师 西湖大学,旨在记录学习强化学习的过程。
强化学习07——时序差分方法
TD算法
TD算法的思想
和MC算法一样,TD算法是一类无模型算法,TD算法在数学上干了一件什么事情呢?即求解给定策略的贝尔曼方程(Policy evaluation),它是一种在线的(Online)算法,可以立刻用得到的信息更新数据,因此可以解决一些Continuing tasks。
回到状态值函数state value的定义
v
π
(
s
)
=
E
[
R
+
γ
G
∣
S
=
s
]
,
s
∈
S
v_\pi(s)=\mathbb{E}\big[R+\gamma G|S=s\big],\quad s\in\mathcal{S}
vπ(s)=E[R+γG∣S=s],s∈S其中
G
G
G是折扣回报,我们有
E
[
G
∣
S
=
s
]
=
∑
a
π
(
a
∣
s
)
∑
s
′
p
(
s
′
∣
s
,
a
)
v
π
(
s
′
)
=
E
[
v
π
(
S
′
)
∣
S
=
s
]
\mathbb{E}[G|S=s]=\sum_a\pi(a|s)\sum_{s'}p(s'|s,a)v_\pi(s')=\mathbb{E}[v_\pi(S')|S=s]
E[G∣S=s]=a∑π(a∣s)s′∑p(s′∣s,a)vπ(s′)=E[vπ(S′)∣S=s]其中
S
′
S'
S′是下一时刻的状态,因此引出贝尔曼方程的另一种形式,即贝尔曼期望方程:
v
π
(
s
)
=
E
[
R
+
γ
v
π
(
S
′
)
∣
S
=
s
]
,
s
∈
S
.
v_\pi(s)=\mathbb{E}[R+\gamma v_\pi(S^{\prime})|S=s],\quad s\in\mathcal{S}.
vπ(s)=E[R+γvπ(S′)∣S=s],s∈S.同样反映的是不同状态的state value的关系。我们可以通过Robbins-Monro算法求解该方程。
定义
g
(
v
(
s
)
)
g(v(s))
g(v(s)):
g
(
v
(
s
)
)
=
v
(
s
)
−
E
[
R
+
γ
v
π
(
S
′
)
∣
s
]
g(v(s))=v(s)-\mathbb{E}\big[R+\gamma v_{\pi}(S')|s\big]
g(v(s))=v(s)−E[R+γvπ(S′)∣s]故求解上述贝尔曼转化为如下问题:
g
(
v
(
s
)
)
=
0.
g(v(s))=0.
g(v(s))=0.对应噪音观测:
g
~
(
v
(
s
)
)
=
v
(
s
)
−
[
r
+
γ
v
π
(
s
′
)
]
=
(
v
(
s
)
−
E
[
R
+
γ
v
π
(
S
′
)
∣
s
]
)
⏟
g
(
v
(
s
)
)
+
(
E
[
R
+
γ
v
π
(
S
′
)
∣
s
]
−
[
r
+
γ
v
π
(
s
′
)
]
)
⏟
η
.
\begin{aligned} \tilde{g}(v(s))& =v(s)-\begin{bmatrix}r+\gamma v_\pi(s')\end{bmatrix} \\ &\begin{aligned}&=\underbrace{\left(v(s)-\mathbb{E}\big[R+\gamma v_\pi(S')|s\big]\right)}_{g(v(s))}+\underbrace{\left(\mathbb{E}\big[R+\gamma v_\pi(S')|s\big]-\big[r+\gamma v_\pi(s')\big]\right)}_{\eta}.\end{aligned} \end{aligned}
g~(v(s))=v(s)−[r+γvπ(s′)]=g(v(s))
(v(s)−E[R+γvπ(S′)∣s])+η
(E[R+γvπ(S′)∣s]−[r+γvπ(s′)]).
r
,
s
′
r,s'
r,s′是
R
,
S
′
R,S'
R,S′的样本。因此利用Robbins-Monro算法求解
g
(
v
(
s
)
)
=
0
g(v(s))=0
g(v(s))=0有
v
k
+
1
(
s
)
=
v
k
(
s
)
−
α
k
g
~
(
v
k
(
s
)
)
=
v
k
(
s
)
−
α
k
(
v
k
(
s
)
−
[
r
k
+
γ
v
π
(
s
k
′
)
]
)
,
k
=
1
,
2
,
3
,
…
\begin{aligned} v_{k+1}(s)& \begin{aligned}=v_k(s)-\alpha_k\tilde{g}(v_k(s))\end{aligned} \\ &=v_k(s)-\alpha_k\Big(v_k(s)-\big[{r_k+\gamma}{v_\pi(s_k^{\prime})}\big]\Big),\quad k=1,2,3,\ldots \end{aligned}
vk+1(s)=vk(s)−αkg~(vk(s))=vk(s)−αk(vk(s)−[rk+γvπ(sk′)]),k=1,2,3,…其中
v
k
(
s
)
v_{k}(s)
vk(s)是对
v
π
(
s
)
v_{\pi}(s)
vπ(s)的第k次估计,
r
k
,
s
k
′
r_{k},s'_{k}
rk,sk′是
R
,
S
′
R,S'
R,S′的第k次采样。但有两个问题我们需要解决:
- 我们需要样本数据
{
(
s
,
r
,
s
′
)
}
\{(s,r,s^{\prime})\}
{(s,r,s′)}
解决办法:可以使用一个episode的序列样本 { ( s t , r t + 1 , s t + 1 ) } \{(s_t,r_{t+1},s_{t+1})\} {(st,rt+1,st+1)}。 - 尚不明确
v
π
(
s
k
)
v_{\pi}(s_k)
vπ(sk)
解决办法:使用 v k ( s k ′ ) v_{k}(s'_k) vk(sk′)代替 v π ( s k ) v_{\pi}(s_k) vπ(sk)(用一个样本或一次估计代替真实值)
有了这些分析,接下来正式引入TD算法。
TD算法
算法需要的数据:由给定策略
π
\pi
π生成的序列
{
(
s
t
,
r
t
+
1
,
s
t
+
1
)
}
\{(s_t,r_{t+1},s_{t+1})\}
{(st,rt+1,st+1)}
TD算法如下:
v
t
+
1
(
s
t
)
=
v
t
(
s
t
)
−
α
t
(
s
t
)
[
v
t
(
s
t
)
−
[
r
t
+
1
+
γ
v
t
(
s
t
+
1
)
]
]
,
{v_{t+1}(s_t)=v_t(s_t)-\alpha_t(s_t)}{\left[v_t(s_t)-[r_{t+1}+\gamma v_t(s_{t+1})]\right]},
vt+1(st)=vt(st)−αt(st)[vt(st)−[rt+1+γvt(st+1)]],
v
t
+
1
(
s
)
=
v
t
(
s
)
,
∀
s
≠
s
t
,
v_{t+1}(s)=v_t(s),\quad\forall s\neq s_t,
vt+1(s)=vt(s),∀s=st,
其中
t
=
0
,
1
,
2
,
…
t=0,1,2,\ldots
t=0,1,2,… ,
v
t
(
s
t
)
v_t(s_t)
vt(st)是
v
π
(
s
t
)
v_\pi(s_t)
vπ(st)的估计;
α
t
(
s
t
)
\alpha_t(s_t)
αt(st) 是
s
t
s_t
st 关于
t
t
t 的学习率。第二个式子表示只更新
t
t
t时刻访问到的状态。
TD算法注释如下:
v
t
+
1
(
s
t
)
⏟
new estimate
=
v
t
(
s
t
)
⏟
current estimate
−
α
t
(
s
t
)
[
v
t
(
s
t
)
−
[
r
t
+
1
+
γ
v
t
(
s
t
+
1
)
⏟
TD error
v
ˉ
t
TD target
v
ˉ
t
]
⏞
TD error
δ
t
]
,
\underbrace{v_{t+1}(s_t)}_{\text{new estimate}}=\underbrace{v_t(s_t)}_{\text{current estimate}}-\alpha_t(s_t)[\overbrace{v_t(s_t)-[\underbrace{r_{t+1}+\gamma v_t(s_{t+1})}_{\text{TD error }\bar{v}_t}^{\text{TD target }\bar v_{ t}}]}^{\text{TD error }\delta_t}],
new estimate
vt+1(st)=current estimate
vt(st)−αt(st)[vt(st)−[TD target vˉt
rt+1+γvt(st+1)]
TD error δt],
随着更新
v
t
(
s
t
)
→
v
ˉ
t
v_{t}(s_{t})\rightarrow \bar v_{ t}
vt(st)→vˉt,相应的
v
t
(
s
t
)
→
0
v_{t}(s_{t})\rightarrow 0
vt(st)→0。
TD算法的收敛性
注意Remark第二点,条件:
∑
t
α
t
(
s
)
=
∞
and
∑
t
α
t
2
(
s
)
<
∞
\sum_t\alpha_t(s)=\infty\text{ and }\sum_t\alpha_t^2(s)<\infty
t∑αt(s)=∞ and t∑αt2(s)<∞要求每个状态
s
s
s被访问的次数要足够多。

Sarsa算法
上一小节介绍的TD算法能对给定策略进行评估,但强化学习的最终目的是要找到最优策略,马上要介绍的Sarsa算法能直接对动作值函数action values进行评估,并给出最优策略,简单来讲Sarsa算法就是action values版本的TD算法。
假定我们有经验序列(experience):
{
(
s
t
,
r
t
+
1
,
s
t
+
1
)
}
t
\{(s_t,r_{t+1},s_{t+1})\}_{t}
{(st,rt+1,st+1)}t
Sarsa算法如下:
q
t
+
1
(
s
t
,
a
t
)
=
q
t
(
s
t
,
a
t
)
−
α
t
(
s
t
,
a
t
)
[
q
t
(
s
t
,
a
t
)
−
[
r
t
+
1
+
γ
q
t
(
s
t
+
1
,
a
t
+
1
)
]
]
,
q
t
+
1
(
s
,
a
)
=
q
t
(
s
,
a
)
,
∀
(
s
,
a
)
≠
(
s
t
,
a
t
)
,
\begin{aligned} q_{t+1}(s_{t},a_{t})& =q_t(s_t,a_t)-\alpha_t(s_t,a_t)\Big[q_t(s_t,a_t)-[r_{t+1}+\gamma q_t(s_{t+1},a_{t+1})]\Big], \\ q_{t+1}(s,a)& =q_t(s,a),\quad\forall(s,a)\neq(s_t,a_t), \end{aligned}
qt+1(st,at)qt+1(s,a)=qt(st,at)−αt(st,at)[qt(st,at)−[rt+1+γqt(st+1,at+1)]],=qt(s,a),∀(s,a)=(st,at),
其中
q
t
(
s
t
,
a
t
)
q_{t}(s_{t},a_{t})
qt(st,at)是
q
π
(
s
t
,
a
t
)
q_{\pi}(s_{t},a_{t})
qπ(st,at)的一次估计,学习率
α
t
(
s
t
,
a
t
)
\alpha_t(s_t,a_t)
αt(st,at)依赖于
s
t
,
a
t
s_t,a_t
st,at。而实际上Sarsa算法求解的就是关于动作值函数的贝尔曼期望方程
q
π
(
s
,
a
)
=
E
[
R
+
γ
q
π
(
S
′
,
A
′
)
∣
s
,
a
]
,
∀
s
,
a
.
q_\pi(s,a)=\mathbb{E}\left[R+\gamma q_\pi(S^{\prime},A^{\prime})|s,a\right],\quad\forall s,a.
qπ(s,a)=E[R+γqπ(S′,A′)∣s,a],∀s,a.
n-step Sarsa算法
我们知道可以如下分解:
q
π
(
s
,
a
)
=
E
[
R
t
+
1
+
γ
q
π
(
S
t
+
1
,
A
t
+
1
)
∣
s
,
a
]
,
∀
s
,
a
.
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
q
π
(
S
t
+
2
,
A
t
+
2
)
∣
s
,
a
]
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
γ
3
q
π
(
S
t
+
3
,
A
t
+
3
)
∣
s
,
a
]
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
.
.
.
+
γ
n
q
π
(
S
t
+
n
,
A
t
+
n
)
∣
s
,
a
]
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
.
.
.
∣
s
,
a
]
\begin{align} q_\pi(s,a)&=\mathbb{E}\left[R_{t+1}+\gamma q_\pi(S_{t+1},A_{t+1})|s,a\right],\quad\forall s,a.\\ &=\mathbb{E}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} q_\pi(S_{t+2},A_{t+2})|s,a\right]\\ &=\mathbb{E}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} q_\pi(S_{t+3},A_{t+3})|s,a\right]\\ &=\mathbb{E}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+...+\gamma^{n} q_\pi(S_{t+n},A_{t+n})|s,a\right]\\ &=\mathbb{E}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+...|s,a\right]\\ \end{align}
qπ(s,a)=E[Rt+1+γqπ(St+1,At+1)∣s,a],∀s,a.=E[Rt+1+γRt+2+γ2qπ(St+2,At+2)∣s,a]=E[Rt+1+γRt+2+γ2Rt+3+γ3qπ(St+3,At+3)∣s,a]=E[Rt+1+γRt+2+γ2Rt+3+...+γnqπ(St+n,At+n)∣s,a]=E[Rt+1+γRt+2+γ2Rt+3+...∣s,a]
而实际上n-step Sarsa算法求解的就是关于贝尔曼期望方程:
q
π
(
s
,
a
)
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
.
.
.
+
γ
n
q
π
(
S
t
+
n
,
A
t
+
n
)
∣
s
,
a
]
q_\pi(s,a)=\mathbb{E}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+...+\gamma^{n} q_\pi(S_{t+n},A_{t+n})|s,a\right]
qπ(s,a)=E[Rt+1+γRt+2+γ2Rt+3+...+γnqπ(St+n,At+n)∣s,a]
自然需要经验序列:
{
(
s
t
,
a
t
,
r
t
+
1
,
s
t
+
1
,
a
t
+
1
,
…
,
r
t
+
n
,
s
t
+
n
,
a
t
+
n
)
}
\{(s_t,a_t,r_{t+1},s_{t+1},a_{t+1},\ldots,r_{t+n},s_{t+n},a_{t+n})\}
{(st,at,rt+1,st+1,at+1,…,rt+n,st+n,at+n)}
n-step Sarsa算法如下:
q
t
+
1
(
s
t
,
a
t
)
=
q
t
(
s
t
,
a
t
)
−
α
t
(
s
t
,
a
t
)
[
q
t
(
s
t
,
a
t
)
−
[
r
t
+
1
+
γ
r
t
+
2
+
⋯
+
γ
n
q
t
(
s
t
+
n
,
a
t
+
n
)
]
]
.
\begin{aligned}q_{t+1}(s_t,a_t)&=q_t(s_t,a_t)\\&-\alpha_t(s_t,a_t)\Big[q_t(s_t,a_t)-[r_{t+1}+\gamma r_{t+2}+\cdots+\gamma^nq_t(s_{t+n},a_{t+n})]\Big].\end{aligned}
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−[rt+1+γrt+2+⋯+γnqt(st+n,at+n)]].
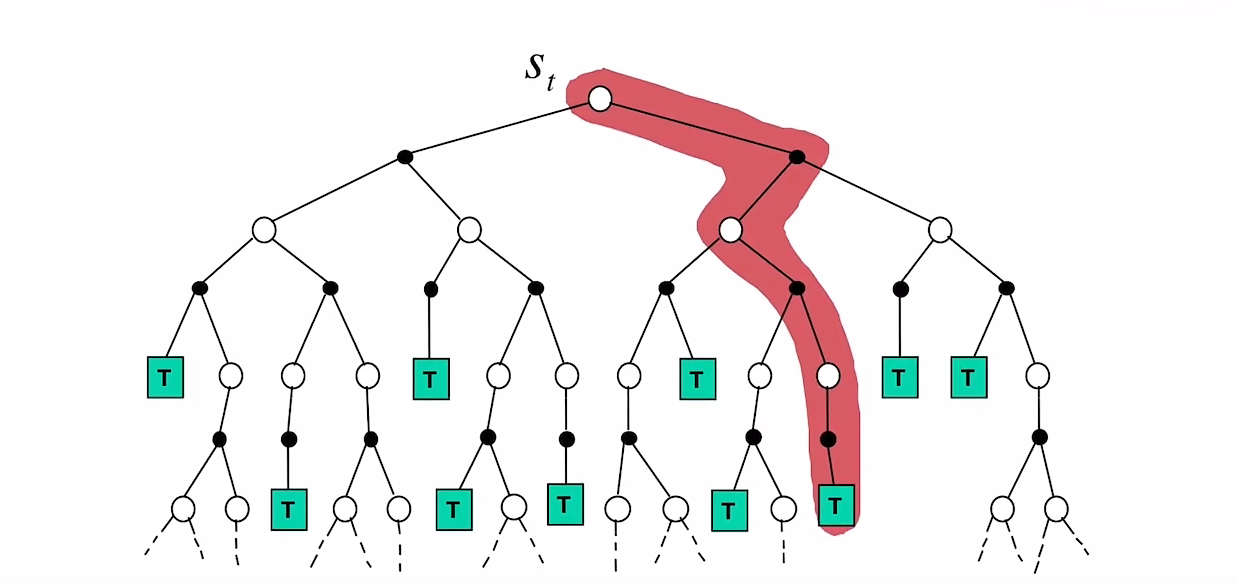
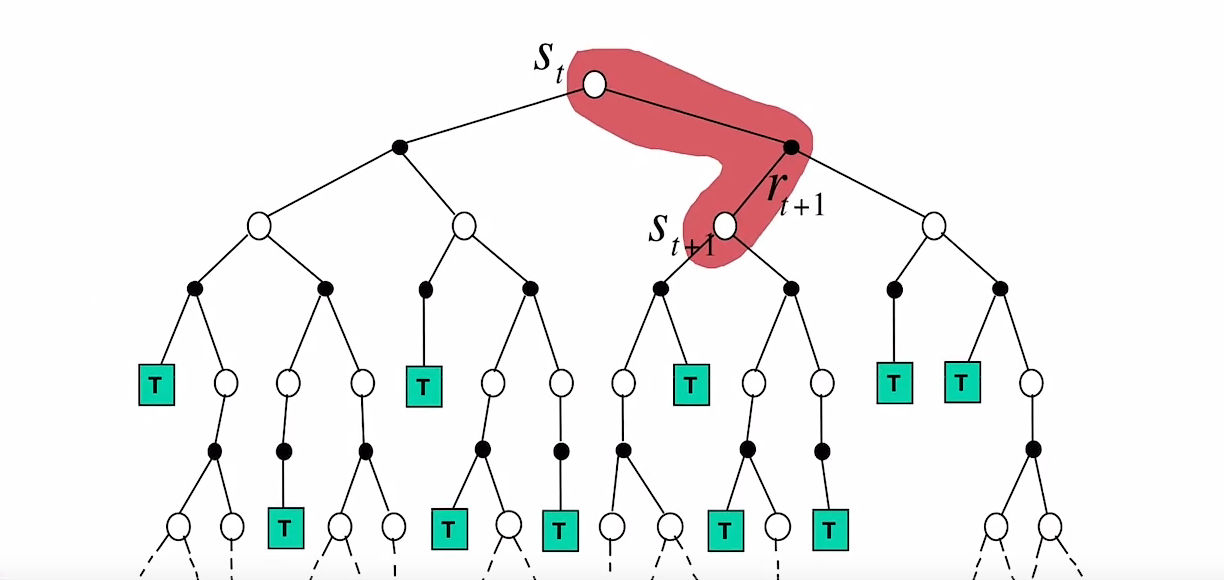
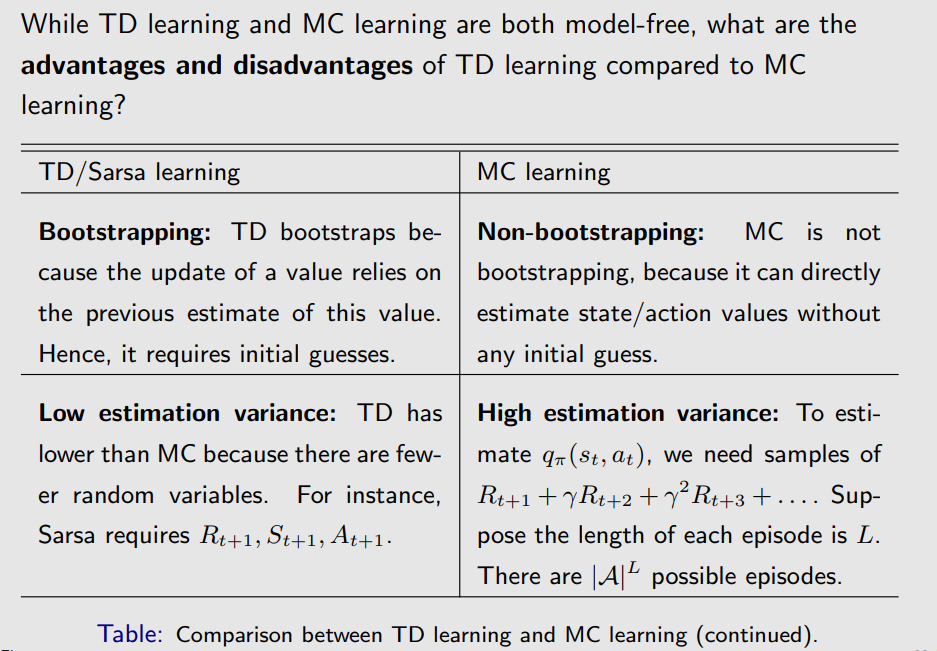
TD算法与MC算法的比较
TD算法是在线的,可以立刻用得到的信息更新数据,因此可以解决一些Continuing tasks,同时相比MC算法由估计结果有更低的方差。

Sarsa算法的收敛性
与TD算法证明类似。

Sarsa算法的伪代码
相比TD,Sarsa算法和policy improvement相结合,这里采用的是
ϵ
\epsilon
ϵ-greedy policy。

Q-learning
Q-learning与前面两个算法不同的是它是直接对贝尔曼最优方程进行求解。
Q-learning算法如下:
q
t
+
1
(
s
t
,
a
t
)
=
q
t
(
s
t
,
a
t
)
−
α
t
(
s
t
,
a
t
)
⌊
q
t
(
s
t
,
a
t
)
−
[
r
t
+
1
+
γ
max
a
∈
A
q
t
(
s
t
+
1
,
a
)
]
⌋
,
q
t
+
1
(
s
,
a
)
=
q
t
(
s
,
a
)
,
∀
(
s
,
a
)
≠
(
s
t
,
a
t
)
,
\begin{aligned} q_{t+1}(s_{t},a_{t})& =q_t(s_t,a_t)-\alpha_t(s_t,a_t)\left\lfloor q_t(s_t,a_t)-[r_{t+1}+\gamma\max_{a\in\mathcal{A}}q_t(s_{t+1},a)]\right\rfloor, \\ q_{t+1}(s,a)& =q_t(s,a),\quad\forall(s,a)\neq(s_t,a_t), \end{aligned}
qt+1(st,at)qt+1(s,a)=qt(st,at)−αt(st,at)⌊qt(st,at)−[rt+1+γa∈Amaxqt(st+1,a)]⌋,=qt(s,a),∀(s,a)=(st,at),
与Sarsa算法类似,唯一的不同点就是Q-learning的TD target是
r
t
+
1
+
γ
max
a
∈
A
q
t
(
s
t
+
1
,
a
)
r_{t+1}+\gamma\max_{a\in\mathcal{A}}q_t(s_{t+1},a)
rt+1+γmaxa∈Aqt(st+1,a)。
Q-learning算法求解的是关于动作值函数的贝尔曼最优方程:
q
(
s
,
a
)
=
E
[
R
t
+
1
+
γ
max
a
q
(
S
t
+
1
,
a
)
∣
S
t
=
s
,
A
t
=
a
]
,
∀
s
,
a
.
\left.q(s,a)=\mathbb{E}\left[R_{t+1}+\gamma\max_{a}q(S_{t+1},a)\right|S_{t}=s,A_{t}=a\right],\quad\forall s,a.
q(s,a)=E[Rt+1+γamaxq(St+1,a)
St=s,At=a],∀s,a.
on-policy learning and off-policy learning

如下是Q-learning 两种不同版本的伪代码(on-policy learning and off-policy learning)
















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









