






本篇博客内容源于课程《强化学习的数学原理》 赵世钰老师 西湖大学,旨在记录学习强化学习的过程。
强化学习——值迭代和策略迭代
文章脉络:给定模型的情况(即probability model p ( r ∣ s , a ) p(r|s, a) p(r∣s,a) 和 p ( s ′ ∣ s , a ) p(s'|s, a) p(s′∣s,a) 对于所有的 ( s , a ) (s, a) (s,a) 都是已知的)下如何求解贝尔曼最优方程?以下将介绍三个算法求解方程,即值迭代算法、策略迭代算法、截断策略迭代算法。实际上可以发现值迭代算法和策略迭代算法都是截断策略迭代算法的两种特殊情况。
值迭代算法
如何求解贝尔曼最优方程?在上一章证明贝尔曼最优方程
v
=
f
(
v
)
=
max
π
(
r
π
+
γ
P
π
v
)
v=f(v)=\max_{\pi}(r_{\pi}+\gamma P_{\pi}v)
v=f(v)=maxπ(rπ+γPπv)中的
f
f
f是压缩映射的过程中已经给出了一个迭代算法,并且我们已经证明了这个迭代算法是可以求解贝尔曼最优方程的,其实那个迭代算法就是值迭代算法。接下来将详细介绍值迭代算法。值迭代算法分为两步:Policy update和Value update。

Remark:应该注意迭代过程中的
v
k
v_{k}
vk不是state value,因为它不满足贝尔曼方程。
Policy update
在给定初始估计
v
k
v_{k}
vk,首先求解一个最优化问题,即找到使
r
π
+
γ
P
π
v
k
r_{\pi}+\gamma P_{\pi}v_{k}
rπ+γPπvk达到最大的策略
π
k
+
1
\pi_{k+1}
πk+1更新原有策略。
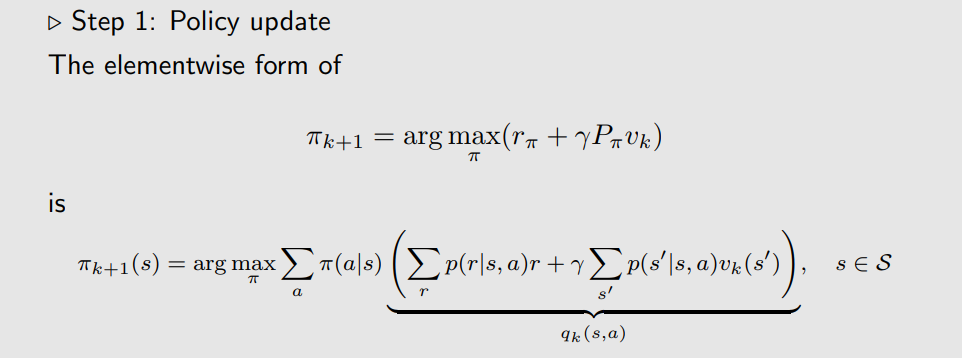
π
k
+
1
\pi_{k+1}
πk+1长什么样呢?实际上在每一步策略迭代中,由于
∑
a
π
(
a
∣
s
)
=
1
\sum_{a}\pi(a|s)=1
∑aπ(a∣s)=1,自然在最优化问题当中应当选择在状态
s
s
s下动作值函数
q
∗
(
s
,
a
)
q^{*}(s,a)
q∗(s,a)最大的所对应的动作
a
a
a,因此这样得到的策略也被叫做贪婪策略(Greed Plicy,不给其他动作一点机会),显然这样的策略是一种确定性策略。

Value update
得到新策略
π
k
+
1
\pi_{k+1}
πk+1后,根据迭代算法就能更新
v
k
v_{k}
vk得到
v
k
+
1
v_{k+1}
vk+1。由于
π
k
+
1
\pi_{k+1}
πk+1是贪婪策略,所以
v
k
+
1
=
max
a
q
k
(
a
,
s
)
v_{k+1}=\max_{a}q_{k}(a,s)
vk+1=maxaqk(a,s)。

Value iteration algorithm - Pseudocode

策略迭代算法
和值迭代算法相同,策略迭代算法同样分为两步,分别是Policy evaluation和Policy improvement。
Policy evaluation
给定一个初始策略
π
k
\pi_{k}
πk,通过迭代算法进行Policy evaluation(Policy evaluation在求解贝尔曼方程中已经介绍过了),并且已经证明过通过迭代得到的序列
{
v
π
k
j
}
j
\{v_{\pi_{k}}^{j}\}_{j}
{vπkj}j会收敛至
v
π
k
v_{\pi_{k}}
vπk。这意味着在整个大的策略迭代算法中的第一步包含一个小迭代算法。

Policy improvement
第二步的Policy improvement和值迭代算法的Policy improvement一样,只不过代入的
v
π
k
v_{\pi_{k}}
vπk是策略
π
k
\pi_{k}
πk对应的state value,而值迭代算法中代入的
v
k
v_{k}
vk不是。

Policy iteration algorithm - Pseudocode

理解策略迭代算法需要明白的几个问题
- 策略迭代算法中的Policy improvement中 π k + 1 \pi_{k+1} πk+1会替换 π k \pi_{k} πk,既然是improvement,如何证明 π k + 1 \pi_{k+1} πk+1好于 π k \pi_{k} πk?
- 如何证明策略迭代算法具有收敛性?即如何说明迭代得到的 { π k } \{\pi_{k}\} {πk}会收敛到最优策略?
如何证明 π k + 1 \pi_{k+1} πk+1好于 π k \pi_{k} πk?
证明状态值函数
v
π
k
+
1
≥
v
π
k
v_{\pi_{k+1}}\ge v_{\pi_{k}}
vπk+1≥vπk即可。
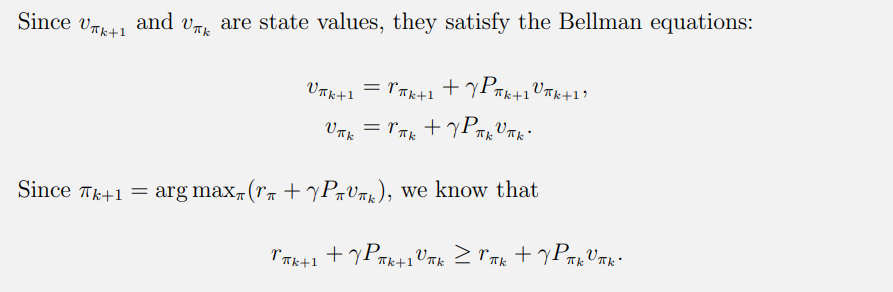
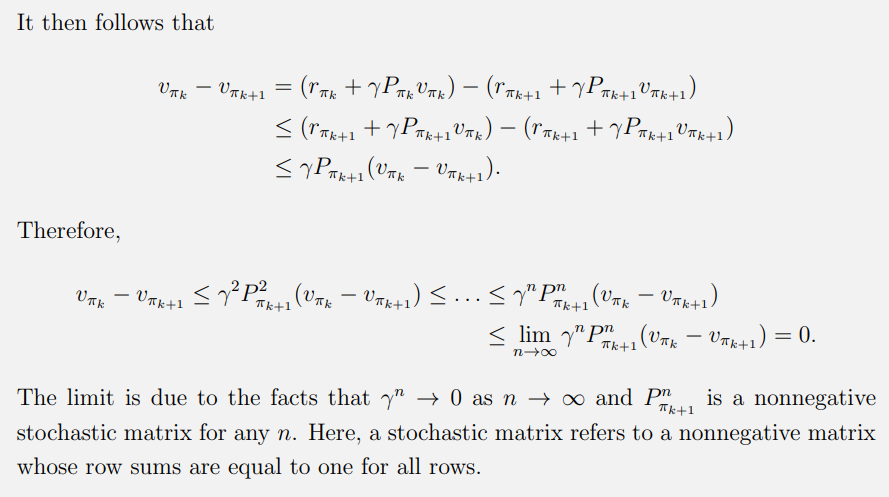
如何证明策略迭代算法具有收敛性?
我们已经说明了
π
k
+
1
\pi_{k+1}
πk+1好于
π
k
\pi_{k}
πk,那么一值迭代下去,
{
π
k
}
\{\pi_{k}\}
{πk}会收敛至最优策略
π
∗
\pi^{*}
π∗吗?我们知道通过策略迭代实际上能得到两个序列
{
π
k
}
\{\pi_{k}\}
{πk}和
{
v
π
k
}
\{v_{\pi_{k}}\}
{vπk},假定最优策略对应的state value为
v
∗
v^{*}
v∗,结合上一个问题得到的结论有
v
π
0
≤
v
π
1
≤
v
π
2
≤
.
.
.
≤
v
π
k
≤
.
.
.
≤
v
∗
v_{\pi_{0}}\leq v_{\pi_{1}}\leq v_{\pi_{2}}\leq...\leq v_{\pi_{k}}\leq...\leq v^{*}
vπ0≤vπ1≤vπ2≤...≤vπk≤...≤v∗即序列
{
v
π
k
}
\{v_{\pi_{k}}\}
{vπk}单调递增有上界,依据单调有界定理序列
{
v
π
k
}
\{v_{\pi_{k}}\}
{vπk}一定是收敛的,下面证明
{
v
π
k
}
\{v_{\pi_{k}}\}
{vπk}会收敛至
v
∗
v^{*}
v∗,即
{
π
k
}
\{\pi_{k}\}
{πk}会收敛至最优策略
π
∗
\pi^{*}
π∗。
思路就是证明策略迭代算法比值迭代算法收敛的快,即利用归纳法证明每一步迭代都有
v
∗
≥
v
π
k
≥
v
k
v^{*}\ge v_{\pi_{k}}\ge v_{k}
v∗≥vπk≥vk在贝尔曼方程那一章,我们已经证明
{
v
k
}
\{v_{k}\}
{vk}会收敛至
v
∗
v^{*}
v∗,那么根据夹逼定理,
{
v
π
k
}
\{v_{\pi_{k}}\}
{vπk}也会收敛至
v
∗
v^{*}
v∗。

截断策略迭代算法
先比较一下值迭代算法和策略迭代算法




实际情况下,不可能对
{
v
π
k
(
j
)
}
j
\{v_{\pi_{k}}^{(j)}\}_{j}
{vπk(j)}j进行无穷次迭代直至收敛到
v
π
k
v_{\pi_{k}}
vπk,现实的情况是在
v
π
k
(
j
)
v_{\pi_{k}}^{(j)}
vπk(j)迭代至一个提前给定的步数后就停止迭代。所以说值迭代算法和策略迭代算法都是截断策略迭代算法的两种极端情况。
截断策略迭代算法的伪代码如下:

那么这种截断是否会给算法的收敛性带来问题呢?答案是不会(挖一个坑)
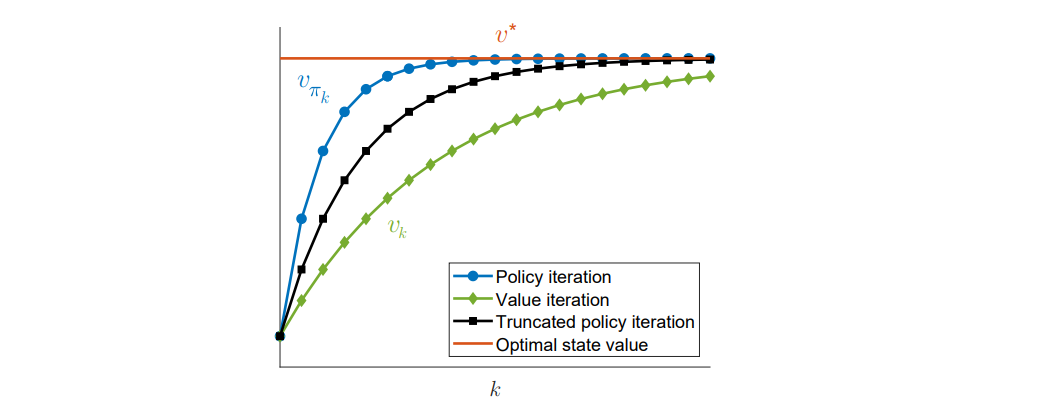
下图可以看到截断策略迭代算法收敛速度处于值迭代算法和策略迭代算法之间。















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









