







文章目录
- 老铁们✌,重要通知🙌!福利来了!!!😉
- 1.神经网络
-
- 1.1各个激活函数的优缺点?
- 1.2 为什么ReLU常用于神经网络的激活函数?
- 1.3 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?
- 1.4 如何确定是否出现梯度爆炸?
- 1.5 神经网络中有哪些正则化技术?
- 1.6 批量归一化(BN) 如何实现?作用?
- 1.7 谈谈对权值共享的理解?
- 1.8 对fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值?
- 1.9 什么是Dropout?原理?为什么有用?它是如何工作的?
- 1.10 如何选择dropout 的概率?
- 1.11 什么是Adam?Adam和SGD之间的主要区别是什么?
- 1.12 一阶优化和二阶优化的方法有哪些?为什么不使用二阶优化?
- 1.12 为什么Momentum可以加速训练?
- 1.13 什么时候使用Adam和SGD?
- 1.14 batch size和epoch的平衡
- 1.15 SGD每步做什么,为什么能online learning?
- 1.16 学习率太大(太小)时会发生什么?如何设置学习率?
- 1.17 神经网络为什么不用拟牛顿法而是用梯度下降?
- 1.18 BN和Dropout在训练和测试时的差别?
- 1.19 若网络初始化为0的话有什么问题?
- 1.20 sigmoid和softmax的区别?softmax的公式?
- 1.21 改进的softmax损失函数有哪些?
- 1.22 调参有哪些技巧?
- 1.23 调参要往哪些方向想?
- 1.24 训练中是否有必要使用L1获得稀疏解?
- 1.25 数据预处理方法有哪些?
- 1.26 如何初始化神经网络的权重?神经网络怎样进行参数初始化?
- 1.27 为什么构建深度学习模型需要使用GPU?
- 1.28 前馈神经网络(FNN),递归神经网络(RNN)和 CNN 区别?
- 1.29 神经网络可以解决哪些问题?
- 1.30 如何提高小型网络的精度,同时尽量不损失压缩模型?
- 1.31 模型压缩常用方法?
- 1.32 模型剪枝常用策略?
- 1.33 列举你所知道的神经网络中使用的损失函数
- 1.342 什么是鞍点问题?
- 1.35 网络设计中,为什么卷积核设计尺寸都是奇数?
- 1.36 影响神经网络速度的因素?
老铁们✌,重要通知🙌!福利来了!!!😉
【计算机视觉 复习流程剖析及面试题详解 】
【深度学习算法 最全面面试题(30 页)】
【机器学习算法 最全面面试题(61页)】
1.神经网络
1.1各个激活函数的优缺点?
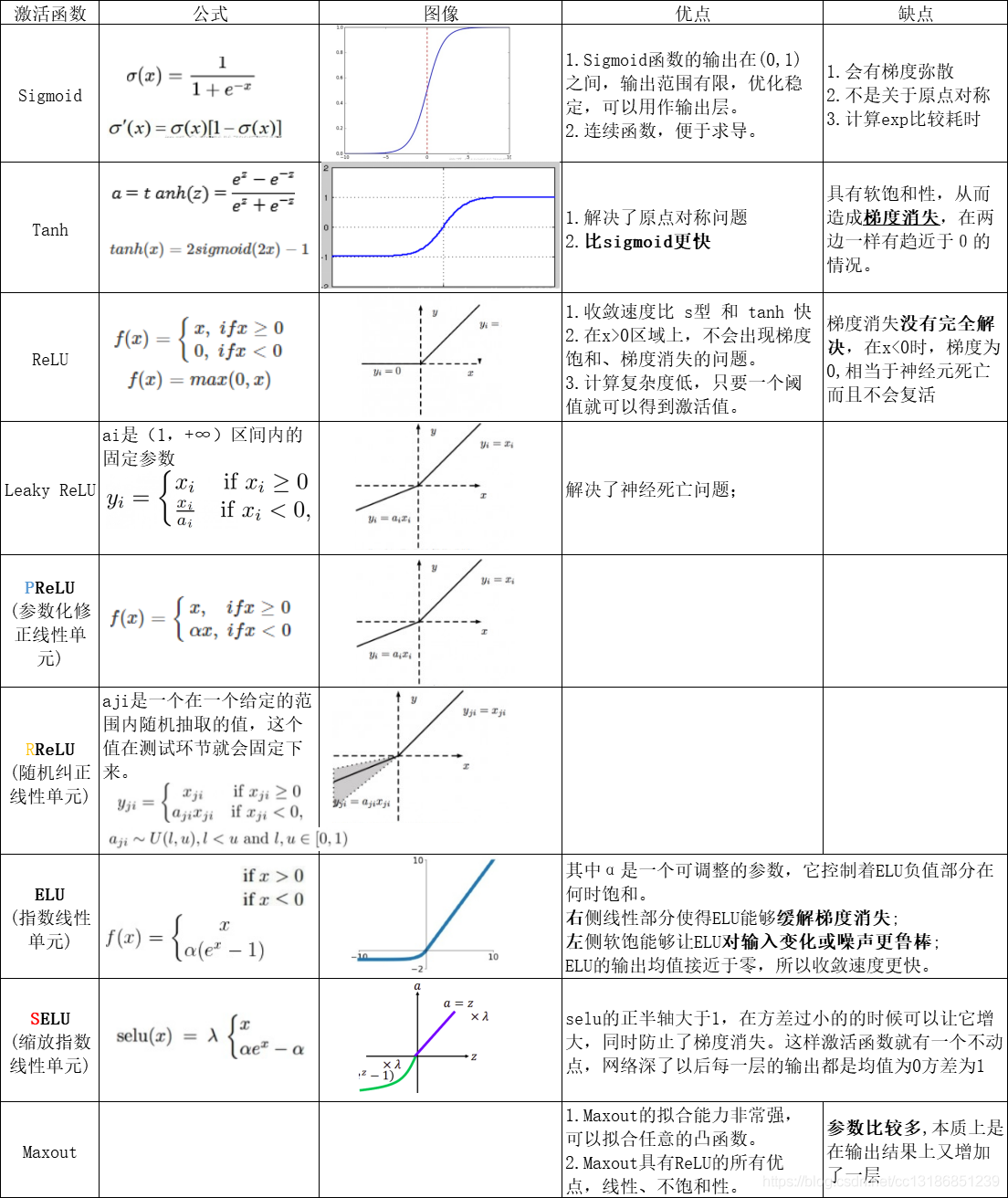
激活函数的选择顺序:
SELU>ELU>Leaky Relu及其变体>Relu>tanh>sigmoid
1.2 为什么ReLU常用于神经网络的激活函数?
1.在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;
2.避免梯度消失问题。对于深层网络,Sigmoid函数反向传播时,很容易就会出现梯度消失问题(在Sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
3.可以缓解过拟合问题的发生。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
4.相比Sigmoid型函数,ReLU函数有助于随机梯度下降方法收敛。
为什么需要激活功能?
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。
1.3 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?
梯度消失:靠近输出层的hidden layer 梯度大,参数更新快,所以很快就会收敛;
而靠近输入层的hidden layer 梯度小,参数更新慢,几乎就和初始状态一样,随机分布。
另一种解释:当反向传播进行很多层的时候,由于每一层都对前一层梯度乘以了一个小数,因此越往前传递,梯度就会越小,训练越慢。
梯度爆炸:前面layer的梯度通过训练变大,而后面layer的梯度指数级增大。
①在深度多层感知机(MLP)网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
②在RNN中,梯度爆炸会导致网络不稳定,无法利用训练数据学习,最好的结果是网络无法学习长的输入序列数据。

1.4 如何确定是否出现梯度爆炸?
模型不稳定,导致更新过程中的损失出现显著变化;
训练过程中模型梯度快速变大;
训练过程中模型权重变成 NaN 值;
训练过程中,每个节点和层的误差梯度值持续超过 1.0。
1.5 神经网络中有哪些正则化技术?
L2正则化(Ridge);
L1正则化(Lasso);
权重衰减;
丢弃法;
批量归一化;
数据增强;
早停法
对于所有权重,权重衰减方法都会为loss func 加上½λw2
1.6 批量归一化(BN) 如何实现?作用?
实现过程: 计算训练阶段mini_batch数量激活函数前结果的均值和方差,然后对其进行归一化,最后对其进行缩放和平移。
对每一个mini-batch数据的内部进行标准化处理吧使输出规范到N(0,1)的正态分布。
作用:
1.可以使用更高的学习率进行优化;
2.减少(取消)dropout;
3.降低L2权重衰减系数;起到正则化作用,简化网络结构。
4.调整了数据的分布,不考虑激活函数,它让每一层的输出归一化到了均值为0方差为1的分布,这保证了梯度的有效性,可以解决反向传播过程中的梯度问题。
moving-mean 计算:0.1当前均值 + 0.9上次训练的均值
1.6.1 BN为什么防止过拟合?
在训练中,BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果。
1.7 谈谈对权值共享的理解?
权值共享这个词是由LeNet5模型提出来的。以CNN为例,在对一张图偏进行卷积的过程中,使用的是同一个卷积核的参数。
比如一个3×3×1的卷积核,这个卷积核内9个的参数被整张图共享,而不会因为图像内位置的不同而改变卷积核内的权系数。
通俗说:就是用一个卷积核不改变其内权系数的情况下卷积处理整张图片。
1.8 对fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值?
使用预训练模型的好处:在于利用训练好的SOTA模型权重去做特征提取,可以节省我们训练模型和调参的时间。
理由:
1.CNN中更靠近底部的层(定义模型时先添加到模型中的层)编码的是更加通用的可复用特征,而更靠近顶部的层(最后添加到模型中的层)编码的是更专业化的特征。微调这些更专业化的特征更加有用,它更代表了新数据集上的有用特征。
2.训练的参数越多,过拟合的风险越大。很多SOTA模型拥有超过千万的参数,在一个不大的数据集上训练这么多参数是有过拟合风险的,除非你的数据集像Imagenet那样大。
1.9 什么是Dropout?原理?为什么有用?它是如何工作的?
背景:如果模型的参数太多,数据量又太小,则容易产生过拟合。为了解决过拟合,就同时训练多个网络。然后多个网络取均值。费时!
介绍:Dropout可以防止过拟合,在前向传播的时候,让某个神经元的激活值以一定的概率 P停止工作,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











