






由于不同病因之间症状的重叠,痴呆的鉴别诊断一直是神经学中的一大挑战,但它对于制定早期个性化管理策略至关重要。在本研究中,我们提出了一种利用广泛数据的人工智能(AI)模型,包括人口统计学信息、个人和家庭病史、药物使用、神经心理评估、功能评估以及多模态神经影像学数据,来识别个体痴呆的病因。该研究基于9个独立且地理分布广泛的数据集,涵盖了51,269名参与者,帮助识别了10种不同的痴呆病因。该模型将诊断与相似的管理策略对齐,即使在数据不完整的情况下也能确保稳健的预测。我们的模型在区分正常认知、轻度认知障碍和痴呆患者时,微平均接收者操作特征曲线下面积(AUROC)达到了0.94。同时,微平均AUROC在区分不同痴呆病因时为0.96。我们的模型在处理混合痴呆病例时表现出色,两个共同病理的平均AUROC为0.78。在随机选择的100个病例的子集中,AI模型辅助的神经科医生评估的AUROC比仅依靠神经科医生评估高出26.25%。此外,我们的模型预测与生物标志物证据一致,其与不同蛋白病的关联通过尸检结果得到了证实。我们的框架有潜力作为临床环境和药物试验中的痴呆筛查工具。需要进一步的前瞻性研究以确认其改善患者护理的能力。本文发表在Nature Medicine杂志。
正文
痴呆症是我们时代最紧迫的健康挑战之一。每年报告的新病例接近1000万,这种表现为认知功能的进行性下降、足以影响日常生活的综合症,继续带来巨大的临床和社会经济挑战。在2017年,世界卫生组织的全球行动计划突出了对痴呆症进行及时和精确诊断的需求,作为应对全球痴呆症病例不断增长的关键战略目标。因此,在痴呆症的不同病因中进行精确诊断仍然是一个关键但尚未解决的问题,尤其是在全球人口老龄化以及药物试验中对更准确筛查的需求增加的背景下。这一挑战主要源于不同类型痴呆症的临床表现重叠,且在磁共振成像(MRI)扫描中出现的异质性使得诊断更加复杂。考虑到预计将出现神经学家、神经心理学家和老年护理提供者等专家短缺,这一领域的改进需求愈加紧迫,这也凸显了创新和发展诊断工具的紧迫性。
痴呆症的准确鉴别诊断对开具针对性的治疗干预、提高治疗效果和减缓症状进展至关重要。尽管阿尔茨海默病(AD)是主要的病因,但其他类型如血管性痴呆(VD)、路易体痴呆(LBD)和前额颞叶痴呆(FTD)也很常见。这些病因往往可以共存,表现为症状重叠和症状强度的变化,进一步加大了诊断的复杂性。特别是在老年人中,伴随病症的存在导致的诊断错误较为常见,这些错误的诊断可能导致不当的药物使用和不良健康结果。例如,尽管早期AD患者可能是抗淀粉样蛋白治疗的候选人,但如果与其他病因(如VD)共同存在,可能会增加与淀粉样蛋白相关的影像学异常的风险。这一风险强调了准确评估痴呆症相关的病因因素,以指导适当的治疗策略并优化患者护理的必要性。
随着黄金标准测试获取困难的挑战,AD和相关痴呆症的可扩展诊断工具变得愈加紧迫。近期的监管批准已促进了脑脊液(CSF)和正电子发射断层扫描(PET)生物标志物从研究环境转向临床应用。尽管这些进展很有前景,但血液基础的准确生物标志物的临床整合仍是一个积极的研究领域。尽管取得了这些进展,这些诊断工具的可获取性仍然有限,不仅在偏远和经济欠发达地区,而且在城市的医疗中心也存在限制,例如,专家会诊的等待时间过长。这一挑战又被全球专家短缺问题加剧,例如行为神经学家和神经心理学家的缺乏,导致对认知评估的过度依赖,而这些评估可能因许多地区缺乏神经心理学正式培训项目而不适应不同文化的需求。尽管传统方法如临床评估、神经心理学测试和MRI仍然是前期痴呆症鉴别诊断的核心,但它们的有效性依赖于逐渐减少的专家临床医生数量。这一限制凸显了医疗系统需要迅速适应痴呆症诊断和治疗不断变化的动态需求。
机器学习(ML)有可能提高痴呆症诊断的准确性和效率。以前的ML方法主要集中在利用神经影像数据区分正常认知(NC)与轻度认知障碍(MCI)和痴呆患者,尤其是AD作为主要病因。然而,一些研究尝试通过将AD与其他类型的痴呆进行对比,发现AD的神经影像特征。然而,过于关注AD的研究在实际应用中有其局限性,因为其他病因的流行和共存。另外,单纯关注影像数据可能不足以提供对个体神经状况的全面理解。最近,我们提出了一种计算方法,通过结合影像数据和非影像数据(如人口统计学、病史和神经心理学评估),对个体进行分层,并从非AD痴呆类型中识别出可能的AD病例。这些研究开始揭示了导致痴呆的复杂因素矩阵。然而,为了使ML模型能够应用于临床实践,它们必须能够处理混合病因的复杂性,以及可能缺失或不适用的不同数据模式。因此,开发能够利用多模态数据的AI方法有助于准确量化各种痴呆病因,无论临床资源如何,从而使治疗策略与个体患者的情况对接。
在本研究中,我们提出了一种多模态ML框架,利用多种数据,包括人口统计学、个人和家庭病史、药物使用、神经心理学评估、功能评估和多模态神经影像学,来进行痴呆症的鉴别诊断。我们的模型旨在模拟现实场景,将诊断与类似的管理策略对接,并输出每种病因的概率。该方法旨在模仿临床推理,帮助实践者在痴呆筛查和治疗规划中。通过在独立的、地理分布广泛的数据集上进行验证,证明了该模型的稳健性。在比较分析中,我们发现AI增强的临床医生评估比仅依靠临床医生的评估具有更高的诊断准确性。通过将我们的模型与黄金标准的生物标志物和不同病因的尸检数据进行验证,我们进一步强调了该模型与痴呆症下病理生理学的一致性。我们的算法框架有潜力提高痴呆筛查,但需要进一步研究以评估其对医疗结果的影响。
结果
术语表:
-
NC: 正常认知;
-
MCI: 轻度认知障碍;
-
DE: 痴呆症;
-
AD: 阿尔茨海默病;
-
LBD: 路易体痴呆,包括路易体痴呆和帕金森病痴呆;
-
VD: 血管性痴呆、血管性脑损伤和血管性痴呆,包括中风;
-
PRD: 朊病毒病,包括克雅二氏病;
-
FTD: 前额颞叶变性及其变异,包括原发性进行性失语症、皮质基底变性和进行性核上麻痹,伴或不伴有肌萎缩侧索硬化;
-
NPH: 正常压力脑积水;
-
SEF: 系统性和环境因素,包括传染性疾病(包括HIV)、代谢疾病、物质滥用/酒精、药物、系统性疾病和谵妄;
-
PSY: 精神疾病,包括精神分裂症、抑郁症、双相障碍、焦虑症和创伤后应激障碍;
-
TBI: 中度/重度创伤性脑损伤、反复头部损伤和慢性创伤性脑病;
-
ODE: 其他痴呆症状,包括肿瘤、唐氏综合症、多系统萎缩、亨廷顿病和癫痫
利用来自不同队列获得的多模态数据的强大功能,我们的模型采用严格的方法进行痴呆症的鉴别诊断(图1)。该模型将个体分配到十三个诊断类别中的一个或多个类别(术语表1),这些类别是通过神经学专家团队的共识定义的。这种实际的分类方法考虑了临床管理路径,从而与现实场景相呼应。例如,我们将路易体痴呆(LBD)和帕金森病(PD)痴呆归为一个综合类别——LBD。此分类基于这样一个认识,即这些病症的护理通常遵循相似的路径,通常由一个由运动障碍专家组成的多学科团队负责。在血管性痴呆(VD)的背景下,我们包括了那些表现为中风症状、可能或明确为血管性痴呆或血管性脑损伤的个体。此设计涵盖了中风症状、认知网络中的囊性梗塞、大范围白质高信号和/或执行功能障碍作为观察到的认知障碍的主要贡献因素的病例。纳入标准基于这样的预期,即这些人通常会接受来自中风和血管疾病专科医生的护理。同样,我们将各种精神疾病(如精神分裂症、抑郁症、双相障碍、焦虑症和创伤后应激障碍)归为一个类别(PSY),承认这些病症的管理主要由精神科医护人员负责。通过将诊断类别与临床护理路径对接,我们的模型不仅用于分类个体的病情,还能指导适当的管理策略。
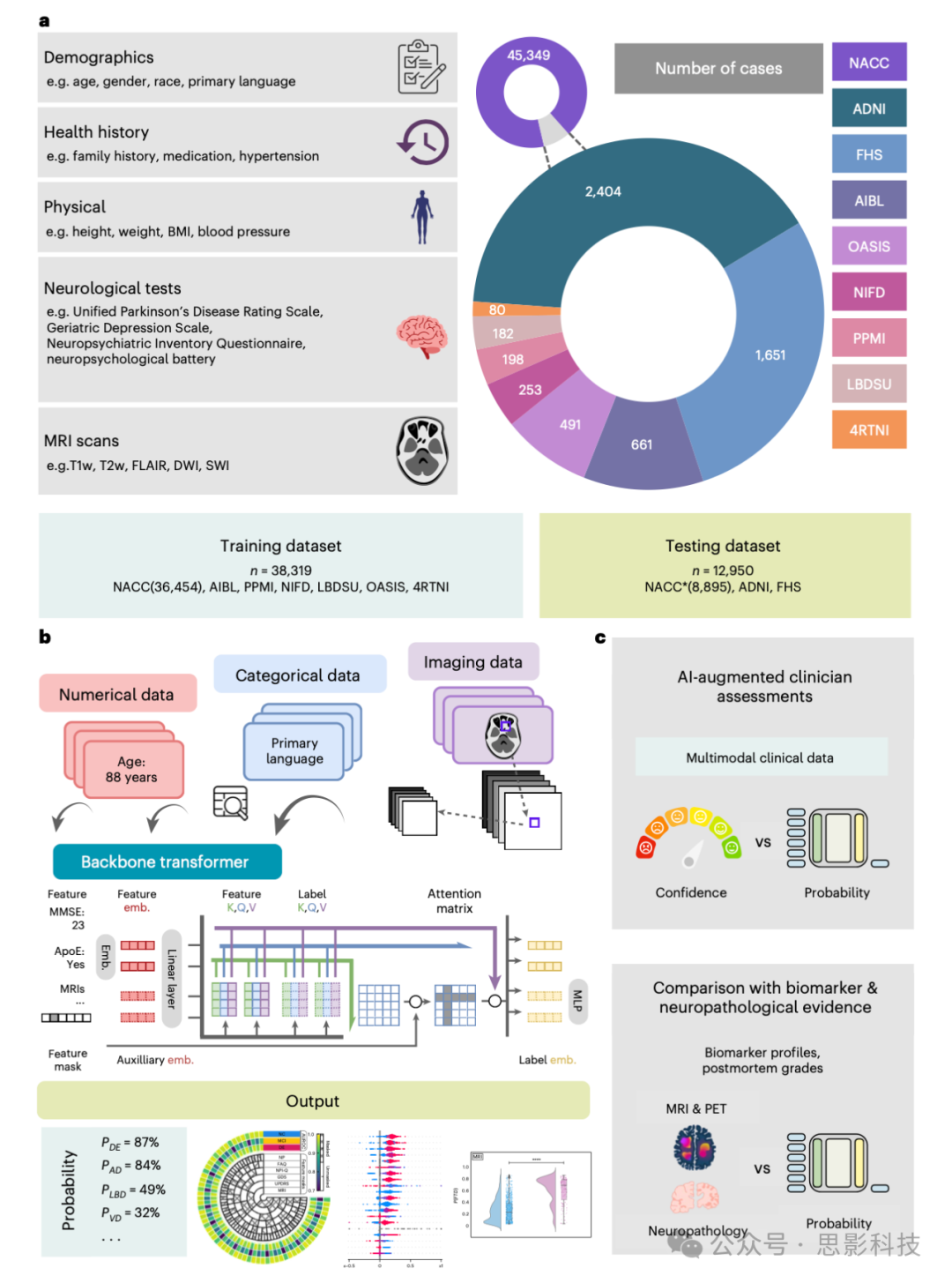
图1 数据、模型架构和建模策略
a, 我们的痴呆症鉴别诊断模型使用了多种数据模态,包括个体层面的人口统计信息、健康史、神经学测试、体格/神经学检查和多序列MRI扫描。这些数据来源在可用时来自九个独立的队列:4RTNI、ADNI、AIBL、FHS、LBDSU、NACC、NIFD、OASIS和PPMI(表1和S1)。对于模型训练,我们将来自NACC、AIBL、PPMI、NIFD、LBDSU、OASIS和4RTNI的数据合并。我们使用NACC数据集的一个子集进行内部测试。对于外部验证,我们利用了ADNI和FHS队列。
b, 该模型使用了一个变换器(transformer)作为基础架构。每个特征通过特定模态的嵌入(emb.)策略处理成固定长度的向量,并作为输入传入变换器。线性层被用来将变换器与输出预测层连接起来。
c, 随机选择NACC测试数据集的一个子集,进行AI模型增强下神经科医生表现与未增强表现的比较分析。类似地,我们还与实践中的神经放射科医生进行了比较评估,为他们提供了来自NACC测试队列的随机选择的已确诊痴呆病例样本,评估AI增强对其诊断表现的影响。在这些评估中,模型和临床医生使用相同的数据集进行分析。最后,我们通过将模型的预测与来自NACC、ADNI和FHS队列的生物标志物资料和病理等级进行比较,评估了模型的预测效果。
模型在正常认知(NC)、轻度认知障碍(MCI)和痴呆症上的表现
我们首先评估了模型在包括正常认知、轻度认知障碍和痴呆症个体的测试案例中的表现。接收者操作特征(ROC)曲线和精确率-召回率(PR)曲线反映了模型在不同平均方法下的强大表现(图2a,b)。在未用于训练的NACC数据、阿尔茨海默病神经影像学倡议(ADNI)和弗雷明汉心脏研究(FHS)数据的测试集中,我们的模型展示了在正常认知、轻度认知障碍和痴呆症的分类能力,微平均接收者操作特征曲线下面积(AUROC)为0.94,微平均精确率-召回率曲线下面积(AUPR)为0.90。此外,宏平均指标显示AUROC为0.93,AUPR值为0.84。加权平均AUROC和AUPR值进一步证明了模型的有效性,分别为0.94和0.87。此外,模型在不同年龄、性别和种族子组中的表现一致,正常认知、轻度认知障碍和痴呆症的微平均AUC超过0.88,微平均AUPR超过0.82。表S7和图S1、S3、S5分别提供了不同测试队列和人口学子组的附加模型表现指标。我们还通过将模型与基准机器学习算法CatBoost进行比较来评估模型的效果,使用相同的案例集进行比较。此比较在两个特征子集上执行,结果显示在NACC数据集上,模型和CatBoost的表现相似。相反,在ADNI和FHS数据集上,我们的模型超越了CatBoost,在所有诊断类别中实现了更高的AUROC和AUPR得分,AUROC的改进范围为0.02到0.21,AUPR的改进范围为0.03到0.17,具体数据见表S8。此比较突显了我们模型在诊断任务中相较于传统机器学习方法的更强泛化能力。
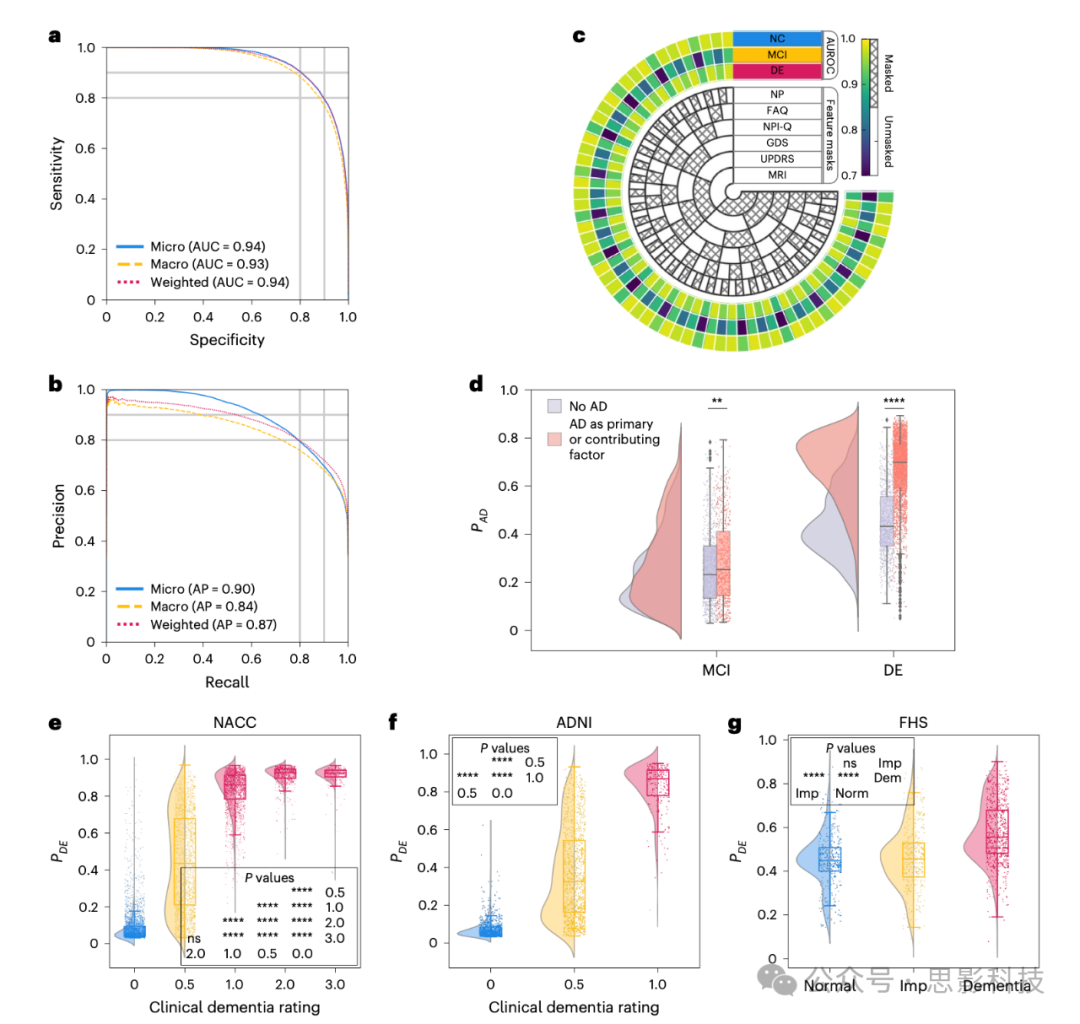
图2:模型在认知谱系个体中的表现
a,b, ROC和PR曲线,以及它们基于正常认知、轻度认知障碍和痴呆症标签的微平均、宏平均和加权平均计算。这些平均方法整合了模型在认知状态谱系中的表现。使用了来自NACC测试数据集的病例,以及来自ADNI和FHS队列的所有病例。
c, 图示了在缺失数据情况下模型表现的不同水平。内层同心圆表示特定测试信息的省略(屏蔽)或包含(解锁)情境。外层三圈描绘了模型的表现,通过AUROC衡量正常认知、轻度认知障碍和痴呆症标签的表现。
d, 雨云图用于展示模型对NACC队列中轻度认知障碍和痴呆症个体的预测阿尔茨海默病(AD)概率。使用Kolmogorov-Smirnov(KS)检验(双样本双侧无调整)比较认知障碍中AD病因的病例与非AD病因的病例(轻度认知障碍:n = 1,486,KS = 0.09,P = 4.29 × 10−3;痴呆症:n = 4,085,KS = 0.57,P < 1 × 10−200)。
e–g, 雨云图(带小提琴图和箱形图)显示NACC、ADNI和FHS队列中CDR评分(x轴)与模型预测痴呆概率(y轴)的分布。我们在NACC(n = 8,895,H = 6,921.71,P < 1 × 10−200)、ADNI(n = 2,400,H = 1,518.79,P < 1 × 10−200)和FHS(n = 1,651,H = 292.04,P = 3.84 × 10−64)队列中进行了Kruskal-Wallis H检验。随后进行了Dunn’s事后检验,并进行了Bonferroni校正,详细的统计结果见表S10。对于d–g,箱形图中的每个箱子呈现中位数和四分位范围(IQR), whiskers从箱子延伸至最大值和最小值,且不超过1.5倍IQR的距离。显著性水平标注为ns(不显著,P ≥ 0.05);*P < 0.05,**P < 0.01,***P < 0.001,****P < 0.0001。在g中,“Normal”表示认知正常个体,“Imp”表示认知障碍者,“Dem”表示轻度、中度和重度痴呆患者。
Shapley分析用于评估NACC测试集,确定哪些特征对模型的诊断决策影响最大(扩展数据图1)(编者注:Shapley分析是一种来自博弈论的数学方法,用于解释机器学习模型中的特征重要性。它通过计算每个特征对模型预测结果的贡献度来帮助我们理解模型决策的过程。Shapley值的核心思想是,考虑一个特征在所有可能的特征组合中的边际贡献,计算特征在每种可能情况下的增益,从而得出该特征对模型输出的影响)。对于正常认知(NC)的预测,关键特征包括基于神经心理学检查的认知状态、蒙特利尔认知评估(MoCA)的较高分数和记忆任务的较好表现。对于轻度认知障碍(MCI)的预测,除了与记忆相关的特征外,功能障碍和T1加权(T1w)MRI也被发现是重要的特征。最后,对于痴呆症的预测,最具影响力的特征包括功能障碍、较低的迷你心理状态检查(MMSE)时间和地点定向分数,以及APOE4等位基因的存在。总体而言,Shapley值提供了每个特征如何对模型的预测做出贡献的洞察,这对于理解和改善模型的可解释性和准确性至关重要。
模型在缺失数据上的表现
为了评估模型对缺失数据的适应能力,我们在NACC队列中人为引入了不同程度的数据缺失,并通过有选择性地移除数据部分来模拟不同的约束,评估其对预测性能的影响。如图2c所示,尽管面对缺失特征(如MRI、统一帕金森病评分量表、老年抑郁量表(GDS)、神经精神症状问卷、功能活动问卷(FAQ)、神经心理测试或其他参数),我们的模型仍能始终生成可靠的分数。这不仅增强了模型的预测稳定性,还证明了其在无法获得完整数据集的各种临床情境中的潜在适用性。例如,ADNI和FHS数据集作为外部测试数据集,ADNI队列与NACC相比缺失数据约为69%,但模型预测的加权平均AUROC为0.91,AUPR为0.86,适用于正常认知、轻度认知障碍和痴呆症分类。类似地,FHS数据集缺失94%的特征,模型在FHS数据上的表现也达到了加权平均AUROC和AUPR分别为0.68和0.53。
模型与前驱性阿尔茨海默病(AD)的一致性
我们评估了模型区分轻度认知障碍个体的能力,具体是根据阿尔茨海默病是否为其认知障碍的病因,通过比较有无AD的MCI病例的预测AD概率(P(AD))。为对比,我们还评估了模型在区分痴呆症个体时,阿尔茨海默病在其认知障碍中的作用。尽管我们的模型主要训练用于识别AD痴呆,而非其前驱阶段,但它始终将与AD相关的MCI病例的P(AD)预测值高于由其他原因引起的MCI病例,正如图2d和表S9所示。在痴呆症病例中,模型通常将AD作为主要病因的病例的P(AD)预测值较高。这一模式强化了模型在早期疾病检测中的作用,支持临床医生基于认知障碍的特定病因做出知情决策。我们的观察结果支持在AD连续体的管理中采取预防性干预方法,突出了模型的临床意义。
模型与临床痴呆评分(CDR)的一致性
我们比较了模型预测的痴呆症概率(P(DE))与NACC测试和ADNI队列中所有参与者的临床痴呆评分(CDR)分数(图2e,f和表S10)。尽管在模型训练时未将CDR作为输入,但我们的预测与CDR分数表现出强烈的相关性。在NACC数据集分析中,我们观察到P(DE)随着CDR评分的提高而逐渐增加,且在认知障碍谱系上存在统计学显著差异(P < 0.0001)。然而,在CDR为2.0和3.0之间,这一模式未能保持,未发现显著统计差异。在ADNI数据集中,我们发现P(DE)在基线CDR评级与较高级别之间存在统计学显著差异(P < 0.0001)。这一发现表明,模型能够敏感地反映临床痴呆评估中的逐步损害。在FHS数据集(图2g)中,FHS用共识小组的诊断分类(正常、轻度认知障碍和痴呆症)代替了CDR评分,在这些诊断分层中,P(DE)存在明显的统计学显著性(P < 0.0001),除了正常与轻度认知障碍之间。这一发现表明,当依赖有限的特征集时,模型在区分认知衰退的早期阶段存在挑战。这些局限性可能是由于FHS队列的社区基础特性以及FHS的共识小组评分的特定性所致(表S4)。这些发现共同揭示了模型在区分不同认知状态方面的强大能力,展示了其作为跨数据集识别认知障碍程度工具的潜力。
单一和共存痴呆症的评估
我们评估了模型在十种不同痴呆病因中的诊断能力。图3a,b中的ROC和PR曲线显示了模型在识别痴呆病因方面的整体评估表现,采用不同的平均方法,微平均AUROC和AUPR值分别为0.96和0.70。在宏平均方面,AUROC和AUPR分别为0.91和0.36。此外,加权平均的AUROC和AUPR值分别为0.94和0.73。模型的表现,特别是高微平均和加权平均AUROC和AUPR分数,突显了其在广泛痴呆病因中的诊断准确性。尽管较低的宏平均AUPR分数表明我们的模型在某些诊断上的表现可能优于其他诊断,但加权平均分数根据每种痴呆类型的流行率进行调整,支持模型在现实环境中的有效性,因为某些痴呆类型比其他类型更为常见。模型在不同人口学子组(即年龄、性别和种族)中的表现稳定,微平均AUC始终超过0.94,微平均AP超过0.66。更多的模型在不同人口学子组中的表现指标见图S2、S4和S6。
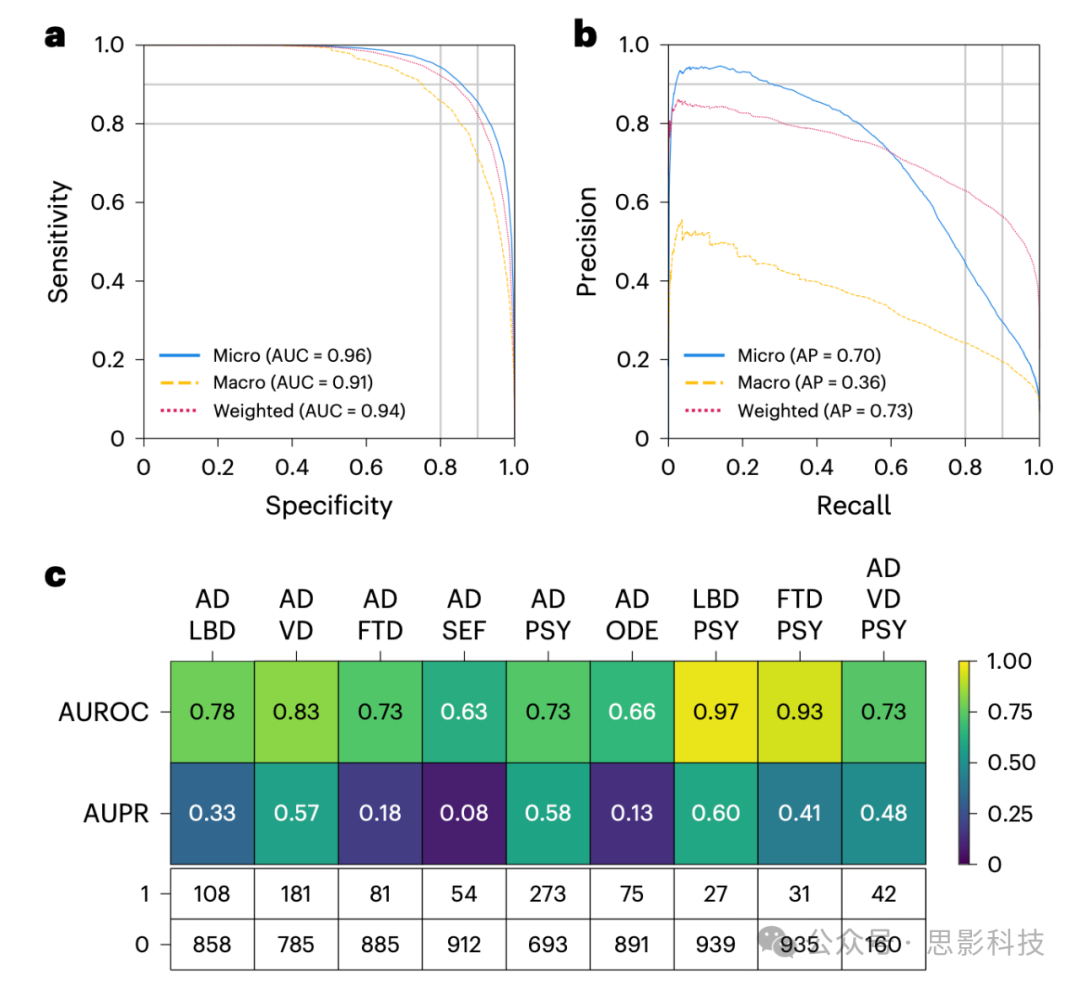
图3:模型在单一和共存痴呆症中的评估
a,b, 提供了ROC和PR曲线,使用微平均、宏平均和加权平均方法对所有痴呆症诊断标签进行评估。这些平均值的计算旨在综合所有痴呆病因的表现指标。仅使用了来自NACC测试的数据。
c, 热力图展示了模型在共存痴呆症中的表现。我们考虑了所有可能的病因组合,其中两个或更多病因在NACC测试队列中共存,前提是至少有25个阳性样本。这确保了AUROC计算在所有可能的连续分布中的最大方差上限为0.01。第一行显示AUROC值,第二行显示AUPR值。表格还显示了每个病例的样本量,1表示阳性病例,0表示阴性样本。仅使用了来自NACC测试的数据。
为了进一步评估模型在共存痴呆症上的表现,我们采用了AUROC计算的最大方差阈值为0.01。这一选择旨在平衡模型的敏感性和特异性,使其能够识别微妙的诊断差异。这导致了最小阳性样本量为25。在两种痴呆共存的情况下(图3c),模型的AUROC得分从0.63到0.97不等,反映了诊断准确性的一个谱系,其中LBD与PSY的组合获得了最高的AUROC。AUPR得分的范围从0.08到0.60,同样,LBD与PSY的组合录得了最高的AUPR值。在阿尔茨海默病(AD)与其他两种病因(VD和PSY)共存的情况下,AUROC得分为0.73,AUPR为0.48。尽管我们的模型表现出强大的诊断区分能力(AUROC得分较高),AUPR得分的变动可能反映了在数据集中持续识别较少见或更复杂的痴呆病因的挑战。值得注意的是,在随后对专家神经学家在诸如SEF和TBI等条件下的表现分析中发现了类似的模式(表S14和S15)。更多的性能指标和可视化图示说明了我们模型评估单一和共存痴呆症的能力,见补充材料(表S7和扩展数据图2)。
模型与生物标志物的验证
模型预测的AD、FTD和LBD的概率与相应的生物标志物的存在一致,如图4和表S11中的雨云图所示。对于AD,P(AD)与NACC和ADNI队列中的Aβ、tau和FDG PET生物标志物相关,表明生物标志物阴性和阳性组之间存在统计学显著差异(P < 0.0001)。值得注意的是,P(AD)在Aβ、tau和FDG PET阳性组中始终较高,证明了我们的框架诊断过程与当前的淀粉样蛋白、tau和神经退行性病变(ATN)标准一致,用于AD诊断。
在NACC队列中,FTD的概率P(FTD)显著与MRI和FDG PET生物标志物相关,生物标志物阳性组的P(FTD)较高。该结果验证了我们的模型能够检测到FTD,并与前额叶低代谢和萎缩的观察模式一致。最后,LBD的概率P(LBD)也表现出明显的差异,当与LBD的多巴胺转运蛋白扫描(DaTscan)证据进行分析时,DaTscan阳性组表现出更高的LBD概率。综上所述,这些发现验证了模型在捕捉痴呆症常见类型的病理生理基础方面的有效性,提供了与相应生物标志物资料密切匹配的病因特异性概率分数。这一一致性不仅证明了模型的预测有效性,还突出了它与现代临床实践的相关性,因为其鉴别诊断痴呆症的机制反映了既定的生物标志物标准。
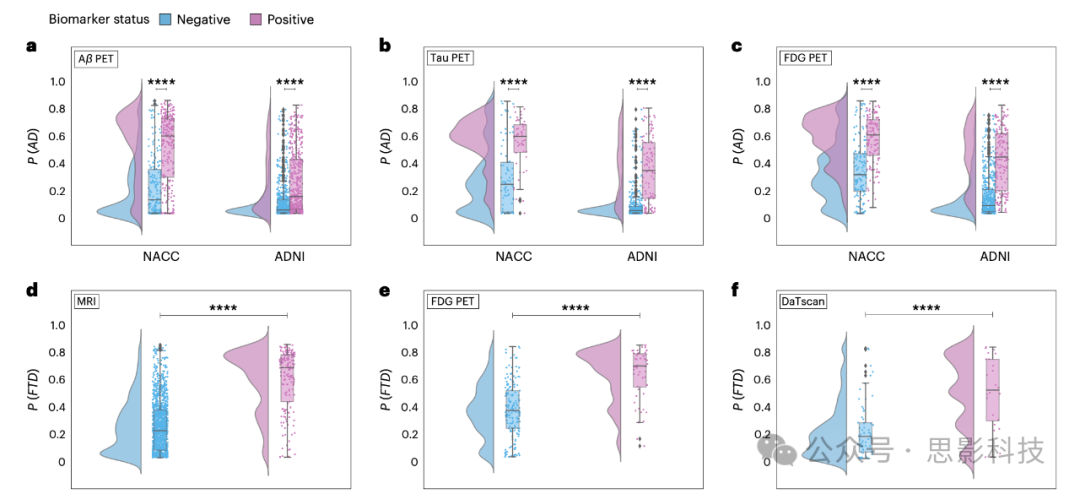
图4:生物标志物级验证
雨云图显示了模型在其相应的生物标志物阴性(蓝色)和阳性(粉色)组中的痴呆病因预测概率。
a, 模型预测的AD概率P(AD)与淀粉样β(Aβ)阳性状态的相关性分析,使用了NACC队列的单侧Mann-Whitney U检验(n = 440,U = 10,303.50,P = 2.04 × 10−25)和ADNI队列的单侧t检验(n = 1,108,t = −12.06,P = 9.74 × 10−31)。
b, P(AD)在tau PET阴性和阳性生物标志物组之间的差异,使用了NACC队列的单侧Mann-Whitney U检验(n = 132,U = 935.50,P = 6.48 × 10−8)和ADNI队列的单侧Mann-Whitney U检验(n = 475,U = 5,857.50,P = 4.10 × 10−27)。
c, 类似的分析用于区分NACC队列(n = 261,U = 3,730.00,P = 3.00 × 10−15)和ADNI队列(n = 760,U = 14,924.00,P = 5.66 × 10−43)中的氟脱氧葡萄糖(FDG)PET生物标志物组的P(AD)。
d,e, 在NACC队列中,模型预测的前额颞叶变性(FTD)概率P(FTD)在MRI(n = 1,494,U = 30,935.50,P = 1.52 × 10−51)和FDG PET生物标志物组(n = 233,U = 1,599.50,P = 2.08 × 10−13)之间进行了一侧Mann-Whitney U检验。
f, 在NACC队列中,LBD的概率P(LBD)在DaTscan阴性和阳性组之间进行了一侧Mann-Whitney U检验(n = 91,U = 318.50,P = 6.26 × 10−6)。所有箱形图中均包括一个箱子,表示中位数和IQR,whiskers从箱子延伸至最大值和最小值,且不超过1.5倍IQR的距离。在所有图中,****P < 0.0001,结果未进行多重比较校正。
模型与神经病理证据的验证
在有尸检数据的病例中(表S12),我们将模型的病因特异性概率分数与常见痴呆症类型的神经病理标志物进行了验证(扩展数据图3和表S13)。复合小提琴图和箱形图表明,随着病理严重程度的增加,模型预测的病因概率也相应升高。前三个图(扩展数据图3a–c)比较了AD概率与三种关键AD病理标志物的渐进性阶段:Aβ斑块的Thal阶段、神经纤维缠结的Braak阶段和新皮层神经性斑块的CERAD密度评分,分别以A1-A3、B1-B3和C1-C3表示。每个标志都显示,随着阶段的推进,AD的中位概率向上偏移,且IQR扩展,且具有统计学显著性(Thal、Braak和CERAD阶段的P值均为P < 0.0001)。我们进一步评估了模型预测的概率与脑淀粉样血管病(CAA)和小动脉硬化的关系,这两者在AD确认尸检病例中都是常见的病理发现。同样,我们观察到,模型在具有轻度、中度或重度CAA(脑淀粉样血管病)的个体中预测的AD概率显著高于没有CAA的个体(P < 0.05)(扩展数据图3d),并且在有小动脉硬化的个体中(P < 0.05)(扩展数据图3e),突出了血管因素在AD进展中的作用。总体而言,这些图表展示了AD相关病理进展的阶段与P(AD)的增加之间的明显趋势。最后,我们观察到P(VD)和P(FTD)与各自病理标志物的显著差异;P(VD)在有小动脉硬化(P < 0.001)和旧微梗塞(P < 0.001)的病例之间有所不同,而P(FTD)在有和没有TDP-43病理的病例之间差异显著(P < 0.001)(扩展数据图3f–h)。这些结果与脑血管病理与VD发生率之间的广泛联系一致。此外,TDP-43蛋白聚集与FTD的流行性之间的明确联系也得到了我们的数据的加强。这些发现总体上突显了我们的AI驱动框架将模型生成的概率分数与AD之外的广泛神经病理状态对齐的能力,支持其在更广泛神经退行性疾病评估中的潜在应用。
AI增强的临床医生评估
我们旨在评估我们的AI框架是否能够与专家临床医生在痴呆症鉴别诊断中的表现相比较并增强其效果。为此,我们将模型预测的概率与临床医生的诊断进行了比较,临床医生的诊断以置信度分数(0到100的评分)形式进行。神经科医生回顾了100个随机选择的病例,包括各种痴呆亚型,并提供了包括人口统计学、病史、神经心理学测试和多序列MRI扫描在内的全面数据。我们观察到,在诊断得到确认(真正阳性)的情况下,神经科医生在正常认知、轻度认知障碍、痴呆、AD、LBD、VD、FTD、NPH和PSY等类别的置信度分数普遍较高,相比之下,在被认为非诊断性(真正阴性)的病例中则较低(P < 0.01)(扩展数据图4a和表S17)。相反,对于同样的100个病例,模型在所有类别(除了ODE)中的真正阳性病例的预测概率均高于真正阴性病例的预测概率(P < 0.01),这表明我们的模型在更多病症中更能有效识别真正阳性病例(扩展数据图4a和表S17)。
我们随后分析了Pearson相关系数,以评估神经科医生置信度分数之间,以及神经科医生置信度分数与我们模型预测概率之间的评分一致性(扩展数据图5a)。在临床评估中,我们发现NC和痴呆组之间的一致性最强,其次是轻度认知障碍、AD、LBD、VD、FTD和PSY的评估之间的一致性较弱。相比之下,PRD、NPH、SEF、TBI和ODE的神经科医生评估之间的一致性最差。这一分析揭示了痴呆类型相对更难诊断的情况,正如专家临床医生的诊断置信度变异性所表明的那样。将神经科医生的置信度分数与我们模型的预测概率进行比较时,我们发现我们的模型提供的评估与神经科医生的评估在正常认知、轻度认知障碍、痴呆、AD和LBD方面普遍一致,Pearson相关系数均超过0.7(扩展数据图5b)。VD、FTD、PSY的关联较弱,Pearson相关系数平均约为0.5,而PRD、NPH、SEF、TBI和ODE的关联则较少一致。观察到的较低相关性反映了这些病症的复杂性,以及缺乏必要的特征来揭示它们的独特特征。
为了确定我们的模型是否能够增强神经科医生的评估,我们计算了AI辅助的神经科医生置信度分数,该分数定义为神经科医生置信度分数与我们模型预测概率的均值。然后,我们比较了单独神经科医生评估与AI增强神经科医生评估的诊断性能(图5a,b和表S14、S15)。我们发现,在所有病因中,AUROC和AUPR的得分普遍有所显著提高(P < 0.05)。所有类别的AUROC平均提高了26.25%,AUPR平均提高了73.23%。诊断性能的最大改进出现在PRD和TBI,其中AUROC的均值提高了73%和72%,AUPR的均值分别提高了242%和257%。在另一项评估中,神经放射科医生评估了一组70个随机选择的临床诊断痴呆病例,并提供了多序列MRI以及人口统计学信息。对于这些70个病例,我们发现我们的模型能够为真正阳性的病例提供更高的置信度分数(P < 0.01),涵盖10种痴呆病因中的4种(扩展数据图4b和表S18)。我们还评估了放射科医生和AI增强放射科医生的诊断性能,后者定义为放射科医生置信度分数与我们模型概率的均值(图5c,d和表S14、S15)。在各种痴呆病因中,我们观察到AUROC的平均提高了16.19%,AUPR的平均提高了41.79%。在除TBI和ODE之外的所有病因中,AUROC显示出显著的增强(P < 0.05),其中PRD(朊病毒病)的均值AUROC提高最大,为69%。AUPR在所有病因中也有所提高,特别是在PRD中,均值AUPR飙升了200%。
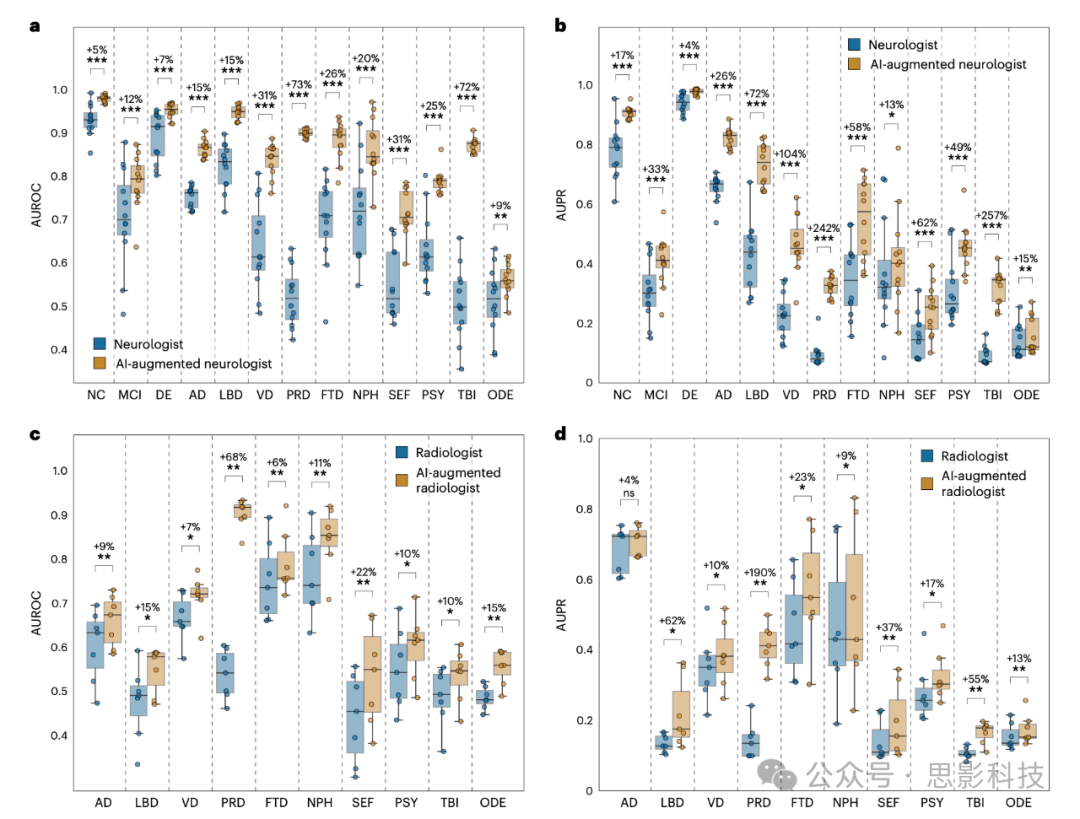
图5:AI增强的临床医生评估展示了由实际临床医生与模型辅助临床医生提供的评估表现的对比
a,b, 在此分析中,12名神经科医生对100个随机选择的病例进行评估,这些病例包括个体层面的人口统计信息、健康历史、神经学测试、体格及神经学检查和多序列MRI扫描。随后,神经科医生为正常认知(NC)、轻度认知障碍(MCI)、痴呆症以及10种痴呆病因(AD、LBD、VD、PRD、FTD、NPH、SEF、PSY、TBI和ODE)分配置信度分数。箱形图展示了单独神经科医生和模型辅助神经科医生(定义为模型与神经科医生置信度分数的平均值)在AUROC(a图)和AUPR(b图)上的表现。使用单侧Wilcoxon符号秩检验进行了配对统计比较,未进行多重比较校正,显著性水平标注为:ns(不显著)对于P ≥ 0.05;*P < 0.05,**P < 0.01,***P < 0.001,P < 0.0001。详细统计数据和P值见表S14。每个病因的平均性能百分比增加也展示在每个统计标注上方。
c,d, 同样,在单独的分析中,7名放射科医生对70个随机选择的病例进行评估,这些病例具有已确认的痴呆诊断,包括个体层面的人口统计学信息和多序列MRI扫描。放射科医生为10种痴呆病因分配了置信度分数,箱形图展示了单独放射科医生和模型辅助放射科医生在10种病因上的AUROC(c图)和AUPR(d图)表现。统计标注和每个病因的平均性能百分比增加以类似的方式展示,显著性水平对应未调整的单侧Wilcoxon符号秩检验的结果,标注为、、和。详细统计数据和P值见表S15。每个箱形图包含一个箱子,表示中位数和IQR,whiskers从箱子延伸至最大值和最小值,且不超过1.5倍IQR的距离。
讨论
我们提出了一个AI模型,用于处理一系列多模态数据,以进行痴呆症的鉴别诊断。与我们之前的研究不同,模型解决了区分不同痴呆病因的临床挑战,包括但不限于AD、VD和LBD。这种区分对精确识别痴呆症的多因素性质至关重要,这与优化个性化治疗干预和患者管理策略密切相关。通过在多个独立队列中进行训练和验证,模型的稳健性得到了确立。此外,我们模型对各种病因的预测结果通过与生物标志物和尸检数据的验证得到了印证。在一个随机选择的病例子集中,当模型预测与神经科医生评估相结合时,模型的表现超越了仅依靠神经科医生评估的表现。这些结果强调了我们模型在提高痴呆相关疾病诊断效果方面的潜力。
我们的模型旨在通过为每种病因提供概率分数来应对混合性痴呆症的复杂性。这种方法非常重要,因为它使临床医生能够根据可用数据系统地优先考虑认知障碍的可能驱动因素。模型有效地捕捉了各种痴呆类型的多因素和重叠特征,提供了一个清晰的框架来指导临床决策。例如,在痴呆的初期阶段,误诊是常见的,通常由于症状被误归因于精神障碍,这一情况在多重共病的存在下变得更加复杂。尽管这些误诊也可能出现在训练数据中,但我们验证过的模型可以作为帮助标准化实践的工具,可能减少临床评估中的变异性。具体而言,LBD在早期症状常常与AD和PSY相似,因此历史上很难诊断。LBD和AD的共存进一步复杂化了诊断,通常直到尸检时才会被完全发现。我们的模型表现出显著的性能,特别是在识别AD和LBD的组合时,突显了其检测常常仅通过尸检分析识别的混合性痴呆症的能力。鉴于相当一部分痴呆病例与可改变的风险因素相关,这一能力至关重要。我们的模型提供的洞察力可以帮助制定早期干预策略,潜在地改变疾病过程并提高患者预后。值得注意的是,我们的模型通过解决混合性痴呆症的检测问题,代表了该领域的一大进步,提供了一个有价值的工具,用于改进临床实践中的诊断准确性。
我们的建模框架以变换器架构为核心,基于其对多样化输入类型的强大处理能力以及通过随机特征屏蔽处理不完整数据的能力,奠定了其效用。这些特性对于需要即时和准确诊断信息的临床医生尤为重要,特别是在数据可用性多变的环境中。例如,当一名全科医生记录一名老年患者的临床观察和认知测试结果时,我们的模型可以计算出一个指示轻度认知障碍或痴呆的概率分数。这一功能促进了早期医疗干预,并为关于专家转诊的更有根据决策提供了支持。在专业的记忆诊所中,向模型添加广泛的神经影像数据和深入的神经心理学电池可能会提高诊断的精度,从而增强个性化管理策略的制定并修订概率分数。该模型能够根据输入数据的范围定制输出,突显了其在不同医疗环境中的作用,包括那些快速且资源高效的诊断至关重要的环境。模型生成的具体、可量化的概率分数增强了其效用,使其成为医疗服务过程中的有用组成部分。通过显示基于不同训练数据(包括人口统计信息、临床表现、神经影像学发现和神经学测试结果)的诊断准确性,模型的多样性使其能够适应不同的临床操作,而无需对现有工作流程进行根本性改动。为了进一步增强我们结果的稳健性并验证该工具在痴呆护理中的效用,前瞻性研究和临床试验是必要的。这些步骤将帮助验证模型的潜力,并确保它满足全科医生和专家在各种医疗环境中的需求。因此,我们的模型可以促进痴呆护理各个层面的无缝过渡,使全科医生能够进行初步的认知筛查,而专家则能进行更为彻底的检查。其包容性功能确保了一个可访问且全面的工具,在早期检测、持续监测和细化鉴别诊断中确保安全运行,从而提升痴呆护理的标准。
局限性
尽管我们的研究具有推动痴呆症鉴别诊断领域发展的潜力,但也存在一些局限性。我们的模型是在9个不同队列中开发和验证的,但其在不同人群和临床环境中的全面普适性仍待确定,因为数据集主要由白人群体组成。尽管我们的模型擅长处理缺失数据,但当前结果表明,当应用于NACC以外的队列(如ADNI和FHS)时,模型的表现可能有所不同,突显了进一步研究以增强其在不同人群中的普适性的重要性。未来,我们看到在护理连续体中评估模型效能的潜力,包括初级护理设施、老年学和普通神经学实践、家庭医学以及三级医疗中心的专业诊所。此外,像我们这样的AI模型有能力增强临床试验招募的患者筛查程序。我们的研究数据集主要由AD病例组成,尽管AD是最常见的痴呆类型,但这可能会导致模型偏向于更好地识别这一特定亚型,从而引入偏倚。尽管我们包含了各种痴呆病因,但不平衡的表现可能会影响模型的普适性和对较少见类型的敏感性。需要注意的是,除了数据不平衡外,某些病症由于可用特征集的限制,天然更难评估,正如专家神经科医生在诊断SEF和TBI等病症时表现较差所示。这一挑战还受到训练数据中标注不确定性或不一致性的影响,因为诊断决策可能因临床医生对症状的主观解释和可用信息的变异而有所不同。我们的训练数据可能反映了这些不确定性,可能影响模型的准确性。然而,在这种背景下使用AI模型也提供了一个机会。通过系统地分析大数据集,AI可以帮助识别在个别病例中不太明显的模式,从而减少临床评估中的变异性。使用不确定标注训练的模型还可以随着更准确和全面的数据的到来不断完善和改进。这一迭代学习过程可以增强模型在诊断复杂病症时的可靠性和效用。此外,我们选择将轻度、中度和重度痴呆病例合并为一个类别。我们承认,这种分类方法可能未完全反映某些医疗环境中个体分期的微妙差异,在这些环境中,不同程度的痴呆严重性对治疗和管理策略有不同的影响。我们主要关注的是鉴别诊断,而不是疾病分期,这促使了这一决定。未来对模型的改进可能包括将疾病分期作为一个额外维度,从而增强其粒度和相关性。最后,我们的研究并未完全解决AD的显著异质性问题,AD具有多样化的临床表现和病理特征。未来的研究需要通过基于特定临床和病理亚型进行分层分析,严格评估AD的异质性,以了解模型在不同AD变异中的表现。
总结
本研究收集的证据表明,先进的计算方法与痴呆症鉴别诊断任务之间的融合,对于资源匮乏的场景和常见但诊断复杂的混合痴呆症这一复杂挑战至关重要。我们的模型有效整合了多模态数据,在多种环境中表现强劲。未来的验证工作,如大规模前瞻性队列研究和多中心临床试验,涵盖更广泛的人群和地理范围,将是验证模型稳健性并增强其在痴呆护理中诊断效用的关键。此外,跟踪患者预后的纵向研究和与现有标准实践的比较效果研究对于确认我们工具的临床有效性至关重要。我们的务实研究突显了神经网络在提高神经认知障碍诊断评估粒度方面的潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









