







1.基于统计特征的关键词提取算法

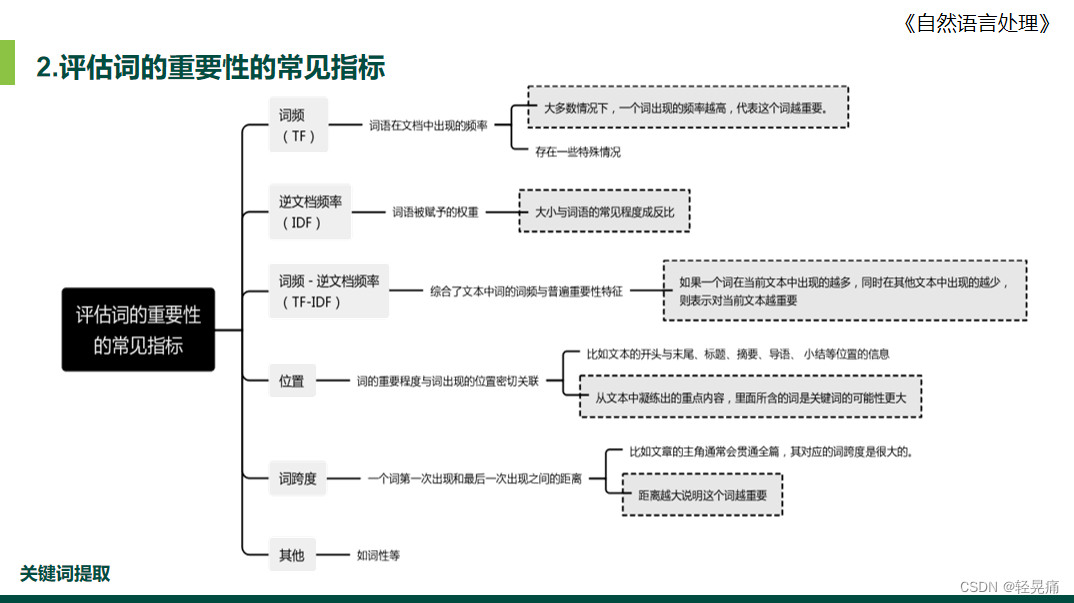
2.评估词的重要性的常见指标
3.TF-IDF算法
(1)概述

(2)基本原理——①计算词频TF

(2)基本原理——②计算逆文档频率 IDF
 (2)基本原理——③计算TF-IDF
(2)基本原理——③计算TF-IDF

(3)算法流程

(4)算法举例

(5)算法特点

TF-IDF关键词提取案例——用 TF-IDF 算法实现关键词提取。
1、数据预处理。对读取到的数据进行预处理,包括分词、去停用词和词性筛选, 处理完成后生成标记文件表示预处理部分完成
# 停用词表
stopWord = './data/stopWord.txt'
stopkey = [w.strip() for w in codecs.open(stopWord, 'rb').readlines()]
# 数据预处理操作:分词,去停用词,词性筛选
def dataPrepos(text,stopkey):
l = []
pos = ['n','nz','v', 'vd', 'vn', 'l', 'a', 'd'] # 定义选取的词性
seg = jieba.posseg.cut(text) #分词
for i in seg:
if i.word not in stopkey and i.flag in pos:# 去停用词 + 词性筛选
l.append(i.word)
return l2构建TF-IDF模型,计算TF-IDF矩阵。
● 构建词频矩阵
● 计算语料中每个词语的TF-IDF权值
● 获取词袋模型中的关键词
● 获取TF-IDF矩阵
● 完成后生成标记文件
def get_tfidf(data):
# 1、构建词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data) # 词频矩阵,a[i][j]:表示j词在第i个文本中的词频
# 2、统计每个词的TF-IDF权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3、获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4、获取TF-IDF矩阵,a[i][j]表示j词在i篇文本中的TF-IDF权重
weight = tfidf.toarray()
create__file('./data/flag3')3、 排序输出关键词,将结果写入文件。 计算好每个词的 TF-IDF 权值之后,对权值进行排序,并以“词语,TF-IDF”的格式依次输出。 全部输出完毕后生成标记文件 表示环节完成,然后将结果写入文件 中。
def getKeywords_tfidf(data, stopkey, topk):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
corpus = [] # 将所有文档输出到一个list中,一行就是一个文档
for index in range(len(idList)):
text = '%s。%s' % (titleList[index], abstractList[index]) # 拼接标题和摘要
text = dataPrepos(text, stopkey) # 文本预处理
text = " ".join(text) # 连接成字符串,空格分隔
corpus.append(text)
# 1、构建词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) # 词频矩阵,a[i][j]:表示j词在第i个文本中的词频
# 2、统计每个词的TF-IDF权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3、获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4、获取TF-IDF矩阵,a[i][j]表示j词在i篇文本中的TF-IDF权重
weight = tfidf.toarray()
create__file('./data/flag3')
# 5、打印词语权重
ids, titles, keys = [], [], []
for i in range(len(weight)):
print(u"-------这里输出第", i + 1, u"篇文本的词语tf-idf------")
ids.append(idList[i])
titles.append(titleList[i])
df_word, df_weight = [], [] # 当前文章的所有词汇列表、词汇对应权重列表
for j in range(len(word)):
print(word[j], weight[i][j])
df_word.append(word[j])
df_weight.append(weight[i][j])
df_word = pd.DataFrame(df_word, columns=['word'])
df_weight = pd.DataFrame(df_weight, columns=['weight'])
word_weight = pd.concat([df_word, df_weight], axis=1) # 拼接词汇列表和权重列表
word_weight = word_weight.sort_values(by='weight', ascending=False) # 按照权重值降序排列
keyword = np.array(word_weight['word']) # 选择词汇列并转成数组格式
word_split = [keyword[x] for x in range(0, topk)] # 抽取前topK个词汇作为关键词
word_split = " ".join(word_split)
keys.append(word_split)
result = pd.DataFrame({"id": ids, "title": titles, "key": keys}, columns=['id', 'title', 'key'])
create__file('./data/flag4')
return result
result = getKeywords_tfidf(data, stopkey, 10)
# result.to_csv("./data/keys_TFIDF.csv", index=False)5、完整代码
"""
导入模块
"""
import sys,codecs
import pandas as pd
import numpy as np
import jieba.posseg
import jieba.analyse
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
"""
标记函数
"""
def create__file(file_path):
f=open(file_path,'w')
f.close
# 读取数据集
dataFile = './data/sample_data - Copy.csv'
data = pd.read_csv(dataFile)
create__file('./data/flag1')
# 停用词表
stopWord = './data/stopWord.txt'
stopkey = [w.strip() for w in codecs.open(stopWord, 'rb').readlines()]
# 数据预处理操作:分词,去停用词,词性筛选
def dataPrepos(text,stopkey):
l = []
pos = ['n','nz','v', 'vd', 'vn', 'l', 'a', 'd'] # 定义选取的词性
seg = jieba.posseg.cut(text) #分词
for i in seg:
if i.word not in stopkey and i.flag in pos:# 去停用词 + 词性筛选
l.append(i.word)
return l
create__file('./data/flag2')
def get_tfidf(data):
# 1、构建词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data) # 词频矩阵,a[i][j]:表示j词在第i个文本中的词频
# 2、统计每个词的TF-IDF权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3、获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4、获取TF-IDF矩阵,a[i][j]表示j词在i篇文本中的TF-IDF权重
weight = tfidf.toarray()
create__file('./data/flag3')
def getKeywords_tfidf(data, stopkey, topk):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
corpus = [] # 将所有文档输出到一个list中,一行就是一个文档
for index in range(len(idList)):
text = '%s。%s' % (titleList[index], abstractList[index]) # 拼接标题和摘要
text = dataPrepos(text, stopkey) # 文本预处理
text = " ".join(text) # 连接成字符串,空格分隔
corpus.append(text)
# 1、构建词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) # 词频矩阵,a[i][j]:表示j词在第i个文本中的词频
# 2、统计每个词的TF-IDF权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3、获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4、获取TF-IDF矩阵,a[i][j]表示j词在i篇文本中的TF-IDF权重
weight = tfidf.toarray()
create__file('./data/flag3')
# 5、打印词语权重
ids, titles, keys = [], [], []
for i in range(len(weight)):
print(u"-------这里输出第", i + 1, u"篇文本的词语tf-idf------")
ids.append(idList[i])
titles.append(titleList[i])
df_word, df_weight = [], [] # 当前文章的所有词汇列表、词汇对应权重列表
for j in range(len(word)):
print(word[j], weight[i][j])
df_word.append(word[j])
df_weight.append(weight[i][j])
df_word = pd.DataFrame(df_word, columns=['word'])
df_weight = pd.DataFrame(df_weight, columns=['weight'])
word_weight = pd.concat([df_word, df_weight], axis=1) # 拼接词汇列表和权重列表
word_weight = word_weight.sort_values(by='weight', ascending=False) # 按照权重值降序排列
keyword = np.array(word_weight['word']) # 选择词汇列并转成数组格式
word_split = [keyword[x] for x in range(0, topk)] # 抽取前topK个词汇作为关键词
word_split = " ".join(word_split)
keys.append(word_split)
result = pd.DataFrame({"id": ids, "title": titles, "key": keys}, columns=['id', 'title', 'key'])
create__file('./data/flag4')
return result
result = getKeywords_tfidf(data, stopkey, 10)
# result.to_csv("./data/keys_TFIDF.csv", index=False)
print(result)
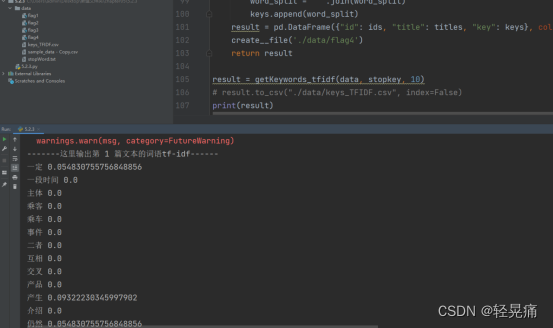
运行结果:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











