







这一周没有写博客,倒腾了好几天gitlab,白天一直在写爬虫,遇到了很多问题,一一解决了
这个爬虫目的是从东方财富网的 上证指数吧 爬取一天的所有发帖
http://guba.eastmoney.com/list,szzs,f.html
具体实现步骤如下:
1.分析网站首页
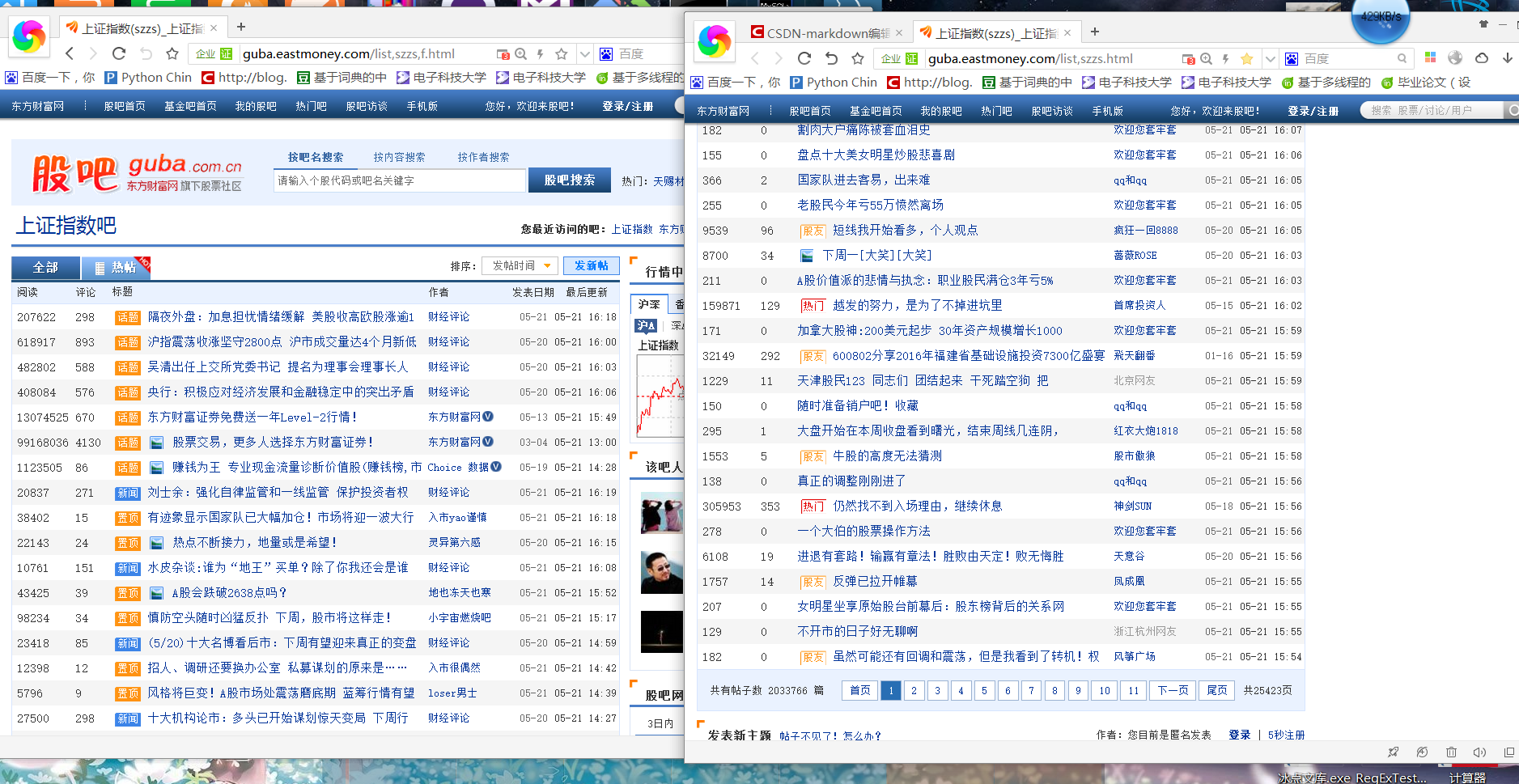
1.首页上有一个按照发帖时间排序我选择的target_urls是根据这个排序产生的网址集
2.对于分页的处理,我是进行的迭代确定的每夜的网址url
3.判断退出循环的标志
原本希望通过获得右下角的那个总页数,但是那个数据是通过js加载出来的,而这个爬虫是通过下载静态html然后解析数据,所以是找不到那个总页数所在的节点的.所以最终设置循环的上限并没有动态生成而是人工指定
(~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~待改进一)
代码片段:
def add_new_url(self,i):
self.target_urls.add('http://guba.eastmoney.com/list,szzs,f_%d.html'%i)
return
def add_new_urls(self,n):
for i in range(1,n+1):#range使用
self.add_new_url(i)
return2.分析帖子url
1.'/news ........ html'是帖子的url的后缀相同部分
2.因为我们将要访问url来下载评论,所以要把整个url拼接好 使用urlparse模块的urljoin方法
def parse(self,page_url):
self.new_comment_urls=set()
urls2=set()
html_cont=urllib2.urlopen(page_url).read()
new_comment_urls=re.findall('/news\S+html',html_cont)
for comment_url in new_comment_urls :
fu_url=urlparse.urljoin(page_url,comment_url)
urls2.add(fu_url)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1408
1408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









