







论文名称《Visualizing and Understanding Convolutional Networks 》
1.意义
该论文是在AlexNet基础上进行了一些细节的改动,网络结构上并没有太大的突破。该论文最大的贡献在于通过使用可视化技术揭示了神经网络各层到底在干什么,起到了什么作用。
从科学的观点出发,如果不知道神经网络为什么取得了如此好的效果,那么只能靠不停的实验来寻找更好的模型。
使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
2.实现方法
训练过程:
对前一层的输入进行卷积 -> relu -> max pooling(可选) -> 局部对比操作(可选) -> 全连接层 -> softmax分类器。
输入是(x,y),计算y与y的估计值之间的交叉熵损失,反向传播损失值的梯度,使用随机梯度下降算法来更新参数(w和b)以完成模型的训练。
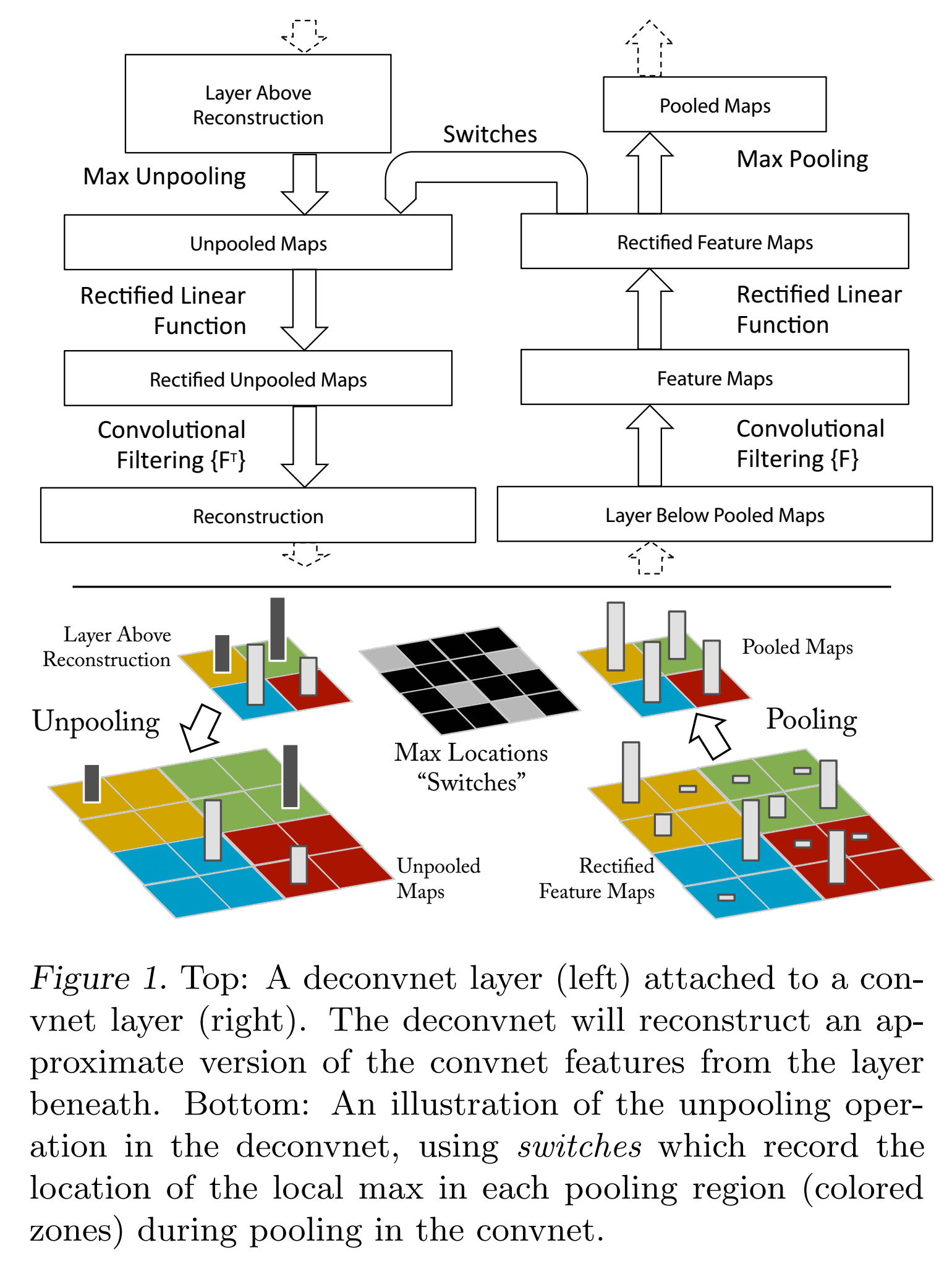
反卷积可视化:
一个卷积层加一个对应的反卷积层;
输入是feature map,输出是图像像素;
过程包括反池化操作、relu和反卷积过程。
反池化:
严格意义上的反池化是无法实现的。作者采用近似的实现,在训练过程中记录每一个池化操作的一个z*z的区域内输入的最大值的位置,这样在反池化的时候,就将最大值返回到其应该在的位置,其他位置的值补0。

relu:
卷积神经网络使用relu非线性函数来保证输出的feature map总是为正数。在反卷积的时候,也需要保证每一层的feature map都是正值,所以这里还是使用relu作为非线性激活函数。
滤波:
使用原卷积核的转秩和feature map进行卷积。反卷积其实是一个误导,这里真正的名字就是转秩卷积操作。可以参考《A guide to convolution arithmetic for deep learning》,https://github.com/vdumoulin/conv_arithmetic,http://deeplearning.net/software/theano_versions/dev/tutorial/conv_arithmetic.html#transposed-convolution-arithmetic,https://www.zhihu.com/question/43609045。
下述卷积和反卷积操作引用自:https://zhuanlan.zhihu.com/p/140896660


3.训练细节
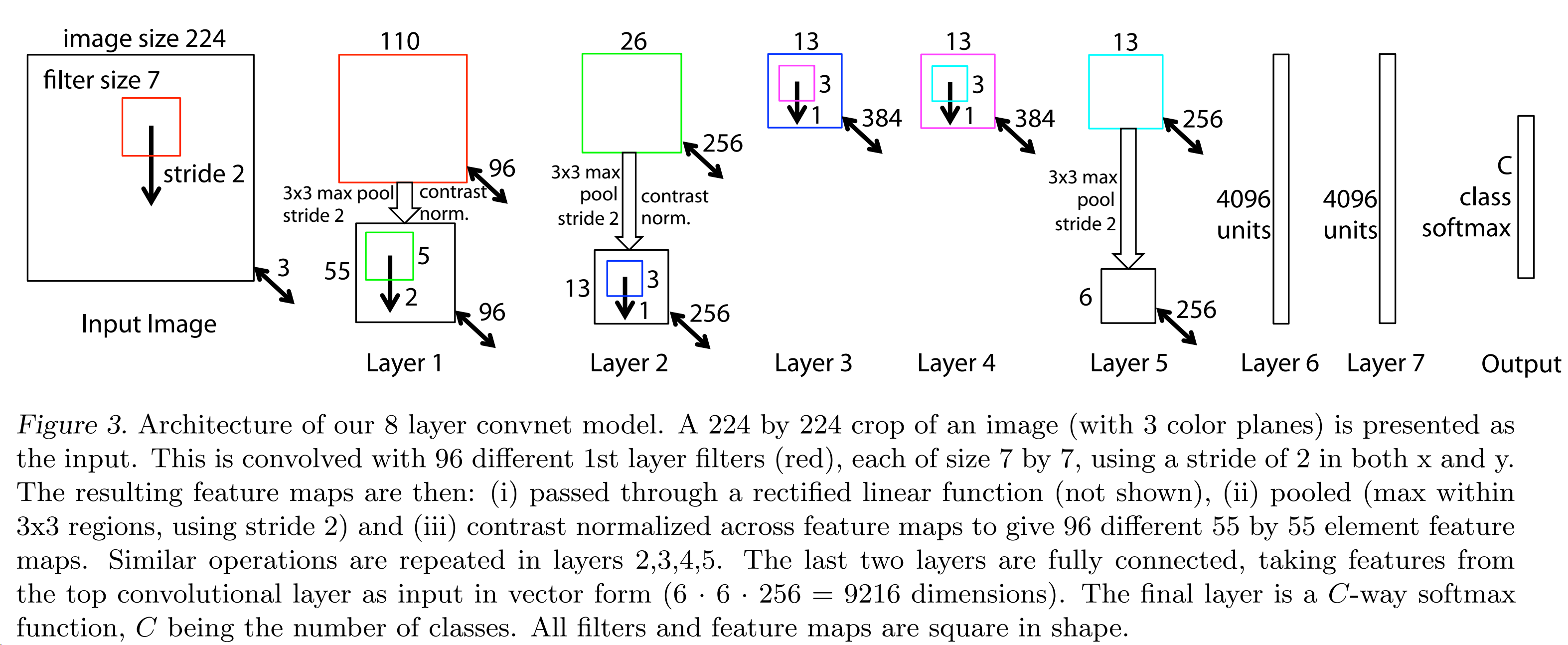
网络结构类似于AlexNet,有两点不同,一是将3,4,5层的变成了全连接,二是卷积核的大小减小。
图像预处理和训练过程中的参数设置也和AlexNet很像。
4.卷积网络可视化
特征可视化:通过对各层卷积核学习到的特征进行可视化发现神经网络学习到的特征存在层级结构。第二层是学习到边缘和角点检测器,第三层学习到了一些纹理特征,第四层学习到了对于指定类别图像的一些不变性的特征,例如狗脸、鸟腿,第五层得到了目标更显著的特征并且获取了位置变化信息。
训练过程中的特征演化:低层特征经过较少epoch的训练过程之后就学习的比较稳定了,层数越高越需要更多的epoch进行训练。因此需要足够多的epoch过程来保证顺利的模型收敛。
特征不变性:卷积神经网络具有平移和缩放不变性,并且层数越高不变性越强。但是不具有旋转不变性。
特征结构选择:作者通过可视化AlexNet第一层和第二层的特征,发现比较大的stride和卷积核提取的特征不理想,所以作者将第一层的卷积核从11*11减小到7*7,将stride从4减小到2,实验说明,这样有助于分类性能的提升。
遮挡实验:遮挡实验说明图像的关键区域被遮挡之后对分类性能有很大的影响,说明分类过程中模型明确定位出了场景中的物体。
一致性分析:不同图像的指定目标局部块之间是否存在一致性的关联,作者认为深度模型可能默认学习到了这种关联关系。作者通过对五张不同的狗的图像进行局部遮挡,然后分析原图和遮挡后的图像的特征之间的汉明距离的和值,值越小说明一致性越大。实验表明,对不同的狗的图像遮挡左眼、右眼和鼻子之后的汉明距离小于随机遮挡,证明存在一定的关联性。
5.实验结果
作者的单个模型(conv1 11 -> 7,4 -> 2)和AlexNet单个模型进行比较,top-5 error 降低了1.7%,证明了这样改进的正向效果。
删除模型的两个卷积层或者两个全连接层,对分类结果影响不大,但是全部删除四层,效果下降很多,说明了模型层数很关键。单独改变全连接层的尺寸,对分类结果影响不大,但增大中间卷积层的尺寸对分类结果有正向的提高,同时增大卷积层和全连接层的尺寸造成了过拟合。
使用ImageNet预训练的模型用到其他数据集上也取得了很好的效果,说明了fine-tuning的价值。
特征分析部分在原始模型某一中间层后加softmax或者svm分类器,说明了最后面层特征的分类效果最好,再次佐证了不同层之间学习到的特征具有层次结构,层数越大,学习到的特征表达能力越强。
6.总结
提出了一种可视化方法;
发现学习到的特征远不是无法解释的,而是特征间存在层次性,层数越深,特征不变性越强,类别的判别能力越强;
通过可视化模型中间层,在alexnet基础上进一步提升了分类效果;
遮挡实验表明分类时模型和局部块的特征高度相关;
模型的深度很关键;
预训练模型可以在其他数据集上fine-tuning得到很好的结果。















 4242
4242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









